Efficient Visual Transformer by Learnable Token Merging

0

Sign in to get full access
Overview
- The paper proposes an efficient visual transformer architecture called Efficient Visual Transformer (EVT) that uses a learnable token merging mechanism to reduce the model size and computational cost.
- EVT achieves competitive performance on image classification tasks while being more efficient than standard visual transformers.
- The authors use an information bottleneck principle and a variational upper bound to guide the token merging process.
Plain English Explanation
The paper introduces a new type of visual transformer architecture called the Efficient Visual Transformer (EVT). Visual transformers are a popular type of deep learning model used for tasks like image classification.
The key innovation in EVT is a learnable token merging mechanism. In a standard visual transformer, the input image is first split into a grid of small image patches, which are then individually processed by the transformer. EVT introduces a way to intelligently combine or "merge" these image patches together during the transformation process.
This merging helps make the model more efficient - it reduces the total number of tokens the transformer needs to process, which in turn reduces the model's size and computational requirements. At the same time, the authors use principles from information theory to ensure the merging process preserves important information from the original image.
Overall, EVT achieves competitive performance on image classification tasks, but is more efficient than standard visual transformer architectures. This could make it useful for deploying transformers in real-world applications with limited computational resources, like on mobile devices.
Technical Explanation
The core innovation in the Efficient Visual Transformer (EVT) is a learnable token merging mechanism. In a standard visual transformer, the input image is first split into a grid of small image patches, which are then individually processed by the transformer layers.
EVT introduces a way to intelligently combine or "merge" these image patches during the transformation process. This is done by adding a token merging module between the transformer layers. This module learns how to group the image patches together in a way that preserves the most important information.
The authors use two key principles to guide this merging process:
-
Information Bottleneck: The merging should discard redundant information while retaining the most relevant features for the task at hand (e.g. image classification).
-
Variational Upper Bound: The authors derive a variational upper bound objective that encourages the merging to be both informative and compact.
Optimizing this objective during training allows the model to learn an effective token merging strategy. This results in a more efficient transformer architecture that can achieve similar performance to standard visual transformers, but with a smaller model size and lower computational cost.
The authors evaluate EVT on several image classification benchmarks and show it outperforms other efficient transformer variants in terms of accuracy, model size, and inference time.
Critical Analysis
The paper provides a well-designed and principled approach to improving the efficiency of visual transformers through learnable token merging. The use of the information bottleneck principle and variational upper bound is a thoughtful way to guide the merging process.
However, some potential limitations or areas for further research include:
- Generalization to other tasks: The evaluation is focused on image classification, so it's unclear how well the learnable token merging would generalize to other computer vision tasks like object detection or segmentation.
- Interpretability of merging process: The paper doesn't provide much insight into what types of image features or patch groupings the model learns to merge. More analysis of the learned merging strategies could yield interesting insights.
- Comparison to other efficient transformer designs: While EVT outperforms other efficient transformer variants, it would be valuable to understand how it compares to other architectural innovations, such as adaptive token reduction or spectrum-preserving token merging.
Overall, the Efficient Visual Transformer represents an important step forward in making transformer-based models more practical for real-world deployment, and the principled approach taken by the authors is commendable. Further research exploring the generalization and interpretability of the learnable merging process could yield valuable insights.
Conclusion
The Efficient Visual Transformer (EVT) introduces a novel learnable token merging mechanism that allows visual transformers to achieve competitive performance with significantly reduced model size and computational cost. By leveraging information theory principles like the information bottleneck and variational upper bound, EVT learns to intelligently combine image patches in a way that preserves the most relevant features for the task at hand.
This work represents an important advance in making transformer-based models more practical and efficient for real-world applications, particularly on resource-constrained devices. The insights and techniques developed in this paper could have broad implications for the development of more compact and deployable transformer architectures across a range of computer vision and other AI tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Visual Transformer by Learnable Token Merging
Yancheng Wang, Yingzhen Yang
Self-attention and transformers have been widely used in deep learning. Recent efforts have been devoted to incorporating transformer blocks into different neural architectures, including those with convolutions, leading to various visual transformers for computer vision tasks. In this paper, we propose a novel and compact transformer block, Transformer with Learnable Token Merging (LTM), or LTM-Transformer. LTM-Transformer performs token merging in a learnable scheme. LTM-Transformer is compatible with many popular and compact transformer networks, and it reduces the FLOPs and the inference time of the visual transformers while maintaining or even improving the prediction accuracy. In the experiments, we replace all the transformer blocks in popular visual transformers, including MobileViT, EfficientViT, ViT-S/16, and Swin-T, with LTM-Transformer blocks, leading to LTM-Transformer networks with different backbones. The LTM-Transformer is motivated by reduction of Information Bottleneck, and a novel and separable variational upper bound for the IB loss is derived. The architecture of mask module in our LTM blocks which generate the token merging mask is designed to reduce the derived upper bound for the IB loss. Extensive results on computer vision tasks evidence that LTM-Transformer renders compact and efficient visual transformers with comparable or much better prediction accuracy than the original visual transformers. The code of the LTM-Transformer is available at url{https://github.com/Statistical-Deep-Learning/LTM}.
Read more7/23/2024
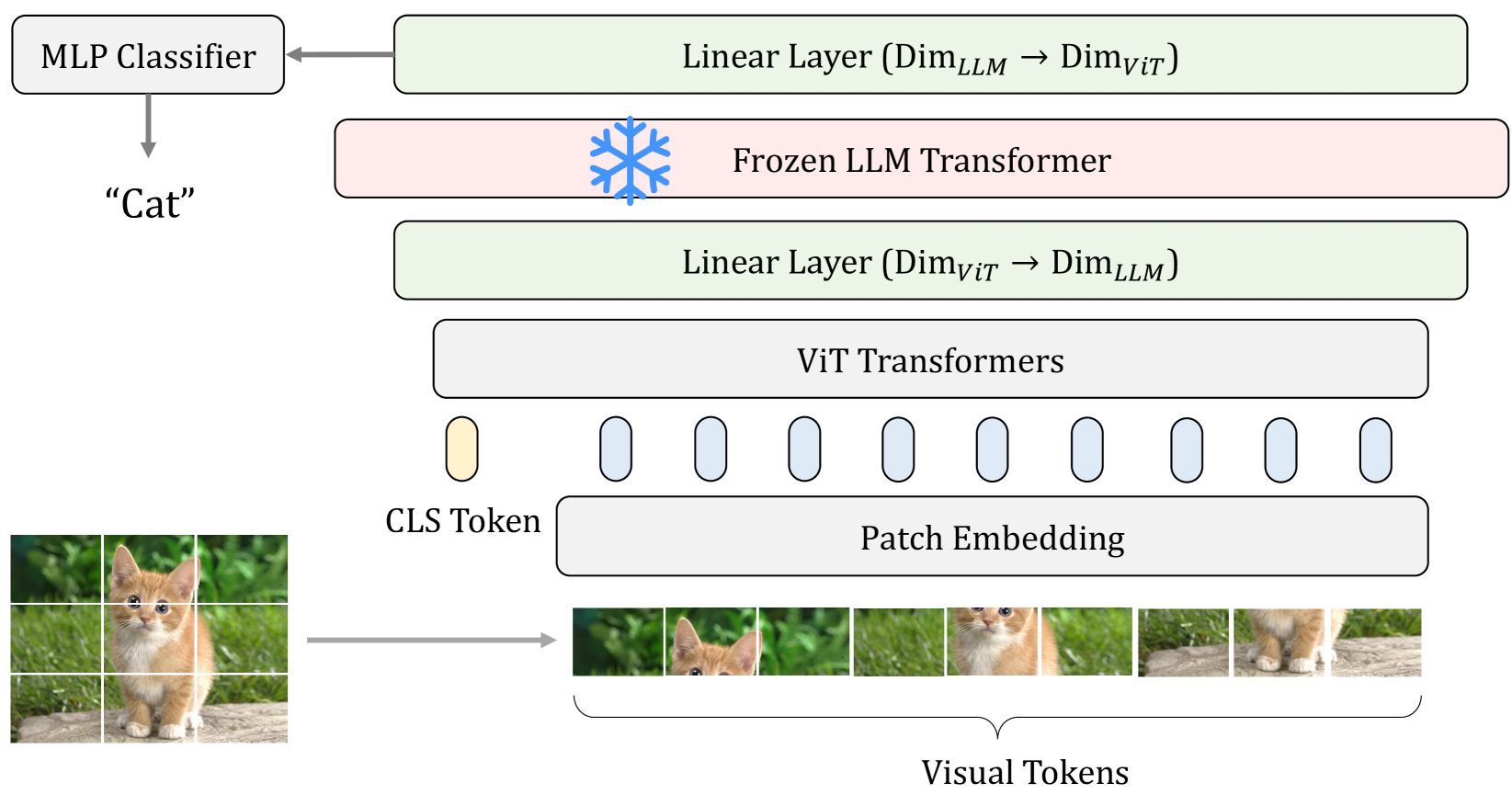
0
Frozen Transformers in Language Models Are Effective Visual Encoder Layers
Ziqi Pang, Ziyang Xie, Yunze Man, Yu-Xiong Wang
This paper reveals that large language models (LLMs), despite being trained solely on textual data, are surprisingly strong encoders for purely visual tasks in the absence of language. Even more intriguingly, this can be achieved by a simple yet previously overlooked strategy -- employing a frozen transformer block from pre-trained LLMs as a constituent encoder layer to directly process visual tokens. Our work pushes the boundaries of leveraging LLMs for computer vision tasks, significantly departing from conventional practices that typically necessitate a multi-modal vision-language setup with associated language prompts, inputs, or outputs. We demonstrate that our approach consistently enhances performance across a diverse range of tasks, encompassing pure 2D and 3D visual recognition tasks (e.g., image and point cloud classification), temporal modeling tasks (e.g., action recognition), non-semantic tasks (e.g., motion forecasting), and multi-modal tasks (e.g., 2D/3D visual question answering and image-text retrieval). Such improvements are a general phenomenon, applicable to various types of LLMs (e.g., LLaMA and OPT) and different LLM transformer blocks. We additionally propose the information filtering hypothesis to explain the effectiveness of pre-trained LLMs in visual encoding -- the pre-trained LLM transformer blocks discern informative visual tokens and further amplify their effect. This hypothesis is empirically supported by the observation that the feature activation, after training with LLM transformer blocks, exhibits a stronger focus on relevant regions. We hope that our work inspires new perspectives on utilizing LLMs and deepening our understanding of their underlying mechanisms. Code is available at https://github.com/ziqipang/LM4VisualEncoding.
Read more5/7/2024

0
LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, Yan Yan
Large Multimodal Models (LMMs) have shown significant visual reasoning capabilities by connecting a visual encoder and a large language model. LMMs typically take in a fixed and large amount of visual tokens, such as the penultimate layer features in the CLIP visual encoder, as the prefix content. Recent LMMs incorporate more complex visual inputs, such as high-resolution images and videos, which further increases the number of visual tokens significantly. However, due to the inherent design of the Transformer architecture, the computational costs of these models tend to increase quadratically with the number of input tokens. To tackle this problem, we explore a token reduction mechanism that identifies significant spatial redundancy among visual tokens. In response, we propose PruMerge, a novel adaptive visual token reduction strategy that significantly reduces the number of visual tokens without compromising the performance of LMMs. Specifically, to metric the importance of each token, we exploit the sparsity observed in the visual encoder, characterized by the sparse distribution of attention scores between the class token and visual tokens. This sparsity enables us to dynamically select the most crucial visual tokens to retain. Subsequently, we cluster the selected (unpruned) tokens based on their key similarity and merge them with the unpruned tokens, effectively supplementing and enhancing their informational content. Empirically, when applied to LLaVA-1.5, our approach can compress the visual tokens by 14 times on average, and achieve comparable performance across diverse visual question-answering and reasoning tasks. Code and checkpoints are at https://llava-prumerge.github.io/.
Read more5/24/2024

0
Token Turing Machines are Efficient Vision Models
Purvish Jajal, Nick John Eliopoulos, Benjamin Shiue-Hal Chou, George K. Thiravathukal, James C. Davis, Yung-Hsiang Lu
We propose Vision Token Turing Machines (ViTTM), an efficient, low-latency, memory-augmented Vision Transformer (ViT). Our approach builds on Neural Turing Machines and Token Turing Machines, which were applied to NLP and sequential visual understanding tasks. ViTTMs are designed for non-sequential computer vision tasks such as image classification and segmentation. Our model creates two sets of tokens: process tokens and memory tokens; process tokens pass through encoder blocks and read-write from memory tokens at each encoder block in the network, allowing them to store and retrieve information from memory. By ensuring that there are fewer process tokens than memory tokens, we are able to reduce the inference time of the network while maintaining its accuracy. On ImageNet-1K, the state-of-the-art ViT-B has median latency of 529.5ms and 81.0% accuracy, while our ViTTM-B is 56% faster (234.1ms), with 2.4 times fewer FLOPs, with an accuracy of 82.9%. On ADE20K semantic segmentation, ViT-B achieves 45.65mIoU at 13.8 frame-per-second (FPS) whereas our ViTTM-B model acheives a 45.17 mIoU with 26.8 FPS (+94%).
Read more9/14/2024