Frozen Transformers in Language Models Are Effective Visual Encoder Layers
2310.12973
0
0
Abstract
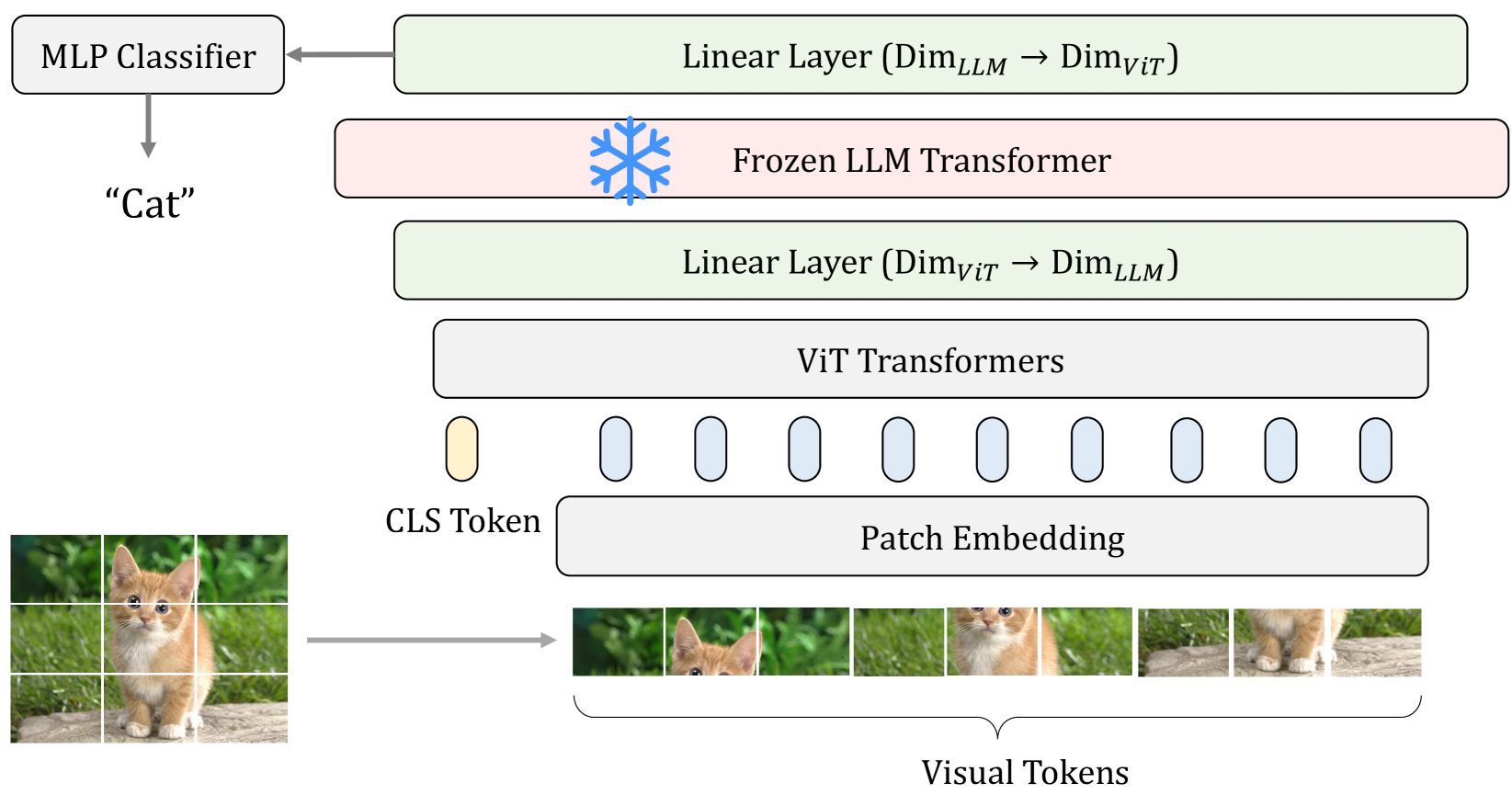
This paper reveals that large language models (LLMs), despite being trained solely on textual data, are surprisingly strong encoders for purely visual tasks in the absence of language. Even more intriguingly, this can be achieved by a simple yet previously overlooked strategy -- employing a frozen transformer block from pre-trained LLMs as a constituent encoder layer to directly process visual tokens. Our work pushes the boundaries of leveraging LLMs for computer vision tasks, significantly departing from conventional practices that typically necessitate a multi-modal vision-language setup with associated language prompts, inputs, or outputs. We demonstrate that our approach consistently enhances performance across a diverse range of tasks, encompassing pure 2D and 3D visual recognition tasks (e.g., image and point cloud classification), temporal modeling tasks (e.g., action recognition), non-semantic tasks (e.g., motion forecasting), and multi-modal tasks (e.g., 2D/3D visual question answering and image-text retrieval). Such improvements are a general phenomenon, applicable to various types of LLMs (e.g., LLaMA and OPT) and different LLM transformer blocks. We additionally propose the information filtering hypothesis to explain the effectiveness of pre-trained LLMs in visual encoding -- the pre-trained LLM transformer blocks discern informative visual tokens and further amplify their effect. This hypothesis is empirically supported by the observation that the feature activation, after training with LLM transformer blocks, exhibits a stronger focus on relevant regions. We hope that our work inspires new perspectives on utilizing LLMs and deepening our understanding of their underlying mechanisms. Code is available at https://github.com/ziqipang/LM4VisualEncoding.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper investigates using frozen transformer layers from large language models as effective visual encoders.
- The researchers explore repurposing pre-trained language model components for computer vision tasks, rather than training new vision-specific models from scratch.
- Their method involves freezing the transformer layers of a large language model and using them as the encoder in a vision-focused model, leading to strong performance on image classification and retrieval benchmarks.
Plain English Explanation
The researchers in this paper had an interesting idea: instead of building brand new computer vision models from scratch, they wanted to see if they could reuse parts of large language models that have already been trained on massive amounts of text data.
Transformer-Aided Semantic Communications and LLM2Vec: Large Language Models are Secretly Powerful have shown that the transformer layers in these large language models can actually be quite powerful and useful for all kinds of tasks, not just natural language processing.
So the researchers in this paper took the transformer layers from a pre-trained language model, froze them so they couldn't be further trained, and then used them as the encoder part of a computer vision model. Essentially, they were reusing the language model's built-in ability to understand and represent information as a way to also understand and represent visual information.
This ended up working surprisingly well - the frozen language model transformers were able to achieve strong performance on standard image classification and retrieval benchmarks, without needing to train brand new vision-specific models from scratch. The key insight seems to be that the transformers have learned very general ways of understanding and representing information that can be applied to both text and images.
Technical Explanation
The core of this paper's method is to take the transformer layers from a pre-trained large language model (LLM) and use them as the encoder in a vision-focused model, without further fine-tuning the transformer weights.
Residual-Based Language Models are Free Boosters and Enhancing Inference Efficiency of Large Language Models by Investigating Unconventional Architectures have shown that the transformer components of LLMs can be effectively repurposed for a variety of tasks beyond just natural language.
In this work, the researchers freeze the weights of the LLM transformer and use it as the encoder for both image classification and retrieval tasks. They find that this "frozen LLM transformer" approach outperforms training a new vision-specific encoder from scratch, despite the transformers not being explicitly trained on visual data.
The key insight seems to be that the LLM transformers have learned general representations and reasoning capabilities that are applicable to visual information as well as text. By reusing these powerful pre-trained components, the researchers are able to build effective vision models without the need for costly from-scratch training.
The paper evaluates this frozen LLM transformer approach on several standard benchmarks, including ImageNet classification and COCO image retrieval. The results demonstrate the effectiveness of this method, suggesting that transformer-based language models can serve as highly capable visual encoders when appropriately repurposed.
Critical Analysis
One key limitation of this work is that it is primarily focused on evaluating the frozen LLM transformer approach on standard computer vision benchmarks. While these results are promising, it would be valuable to see how this method performs on a wider range of real-world visual tasks and datasets, including more complex or domain-specific scenarios.
The paper also does not deeply explore the underlying reasons why the LLM transformers are so effective as visual encoders. Further research into the nature of the representations learned by these models, and how they generalize across modalities, could provide valuable insights.
Additionally, the researchers do not compare their approach to more recent developments in MM1 Methods and Analysis: Insights from Multimodal LLMs, which have shown the potential of training large language models to jointly process text and images. It would be interesting to see how the frozen LLM transformer method stacks up against these more integrated multimodal approaches.
Overall, this paper makes an important contribution by demonstrating the effectiveness of repurposing pre-trained language model components for visual tasks. However, further research is needed to fully understand the implications and limitations of this approach.
Conclusion
This paper presents an innovative method for leveraging pre-trained language model components, specifically the transformer layers, as effective visual encoders. By freezing the weights of the transformer layers from a large language model and using them as the encoder in a vision-focused model, the researchers are able to achieve strong performance on image classification and retrieval benchmarks.
The key insight is that the transformers in these large language models have learned highly general representations and reasoning capabilities that can be effectively applied to visual data, without the need for costly from-scratch training of new vision-specific models. This work suggests that repurposing components of pre-trained language models could be a powerful approach for building effective computer vision systems, and opens up interesting avenues for further research into the connections between language and visual understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
Transformer-Aided Semantic Communications
Matin Mortaheb, Erciyes Karakaya, Mohammad A. Amir Khojastepour, Sennur Ulukus
0
0
The transformer structure employed in large language models (LLMs), as a specialized category of deep neural networks (DNNs) featuring attention mechanisms, stands out for their ability to identify and highlight the most relevant aspects of input data. Such a capability is particularly beneficial in addressing a variety of communication challenges, notably in the realm of semantic communication where proper encoding of the relevant data is critical especially in systems with limited bandwidth. In this work, we employ vision transformers specifically for the purpose of compression and compact representation of the input image, with the goal of preserving semantic information throughout the transmission process. Through the use of the attention mechanism inherent in transformers, we create an attention mask. This mask effectively prioritizes critical segments of images for transmission, ensuring that the reconstruction phase focuses on key objects highlighted by the mask. Our methodology significantly improves the quality of semantic communication and optimizes bandwidth usage by encoding different parts of the data in accordance with their semantic information content, thus enhancing overall efficiency. We evaluate the effectiveness of our proposed framework using the TinyImageNet dataset, focusing on both reconstruction quality and accuracy. Our evaluation results demonstrate that our framework successfully preserves semantic information, even when only a fraction of the encoded data is transmitted, according to the intended compression rates.
5/3/2024
LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
Parishad BehnamGhader, Vaibhav Adlakha, Marius Mosbach, Dzmitry Bahdanau, Nicolas Chapados, Siva Reddy
0
0
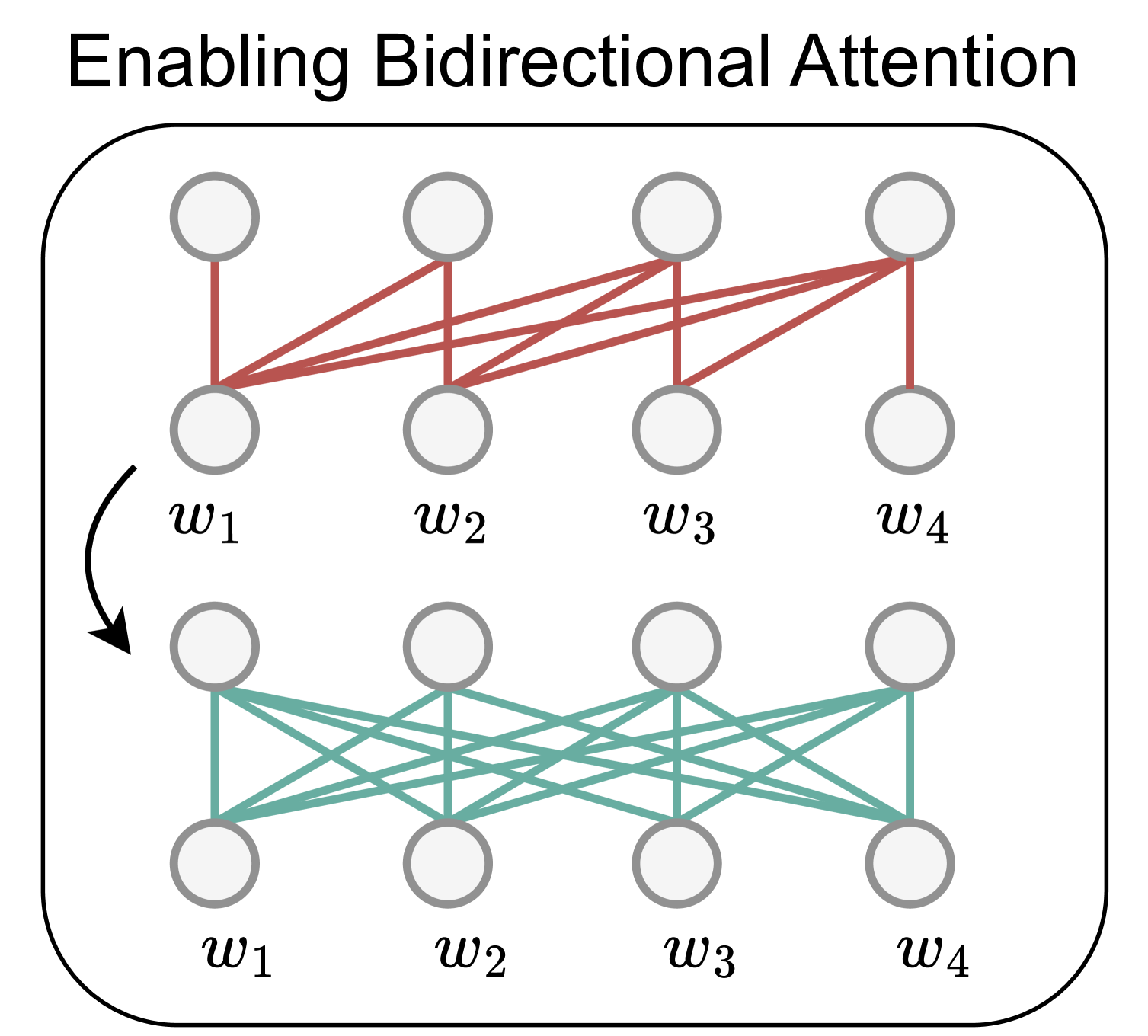
Large decoder-only language models (LLMs) are the state-of-the-art models on most of today's NLP tasks and benchmarks. Yet, the community is only slowly adopting these models for text embedding tasks, which require rich contextualized representations. In this work, we introduce LLM2Vec, a simple unsupervised approach that can transform any decoder-only LLM into a strong text encoder. LLM2Vec consists of three simple steps: 1) enabling bidirectional attention, 2) masked next token prediction, and 3) unsupervised contrastive learning. We demonstrate the effectiveness of LLM2Vec by applying it to 3 popular LLMs ranging from 1.3B to 7B parameters and evaluate the transformed models on English word- and sequence-level tasks. We outperform encoder-only models by a large margin on word-level tasks and reach a new unsupervised state-of-the-art performance on the Massive Text Embeddings Benchmark (MTEB). Moreover, when combining LLM2Vec with supervised contrastive learning, we achieve state-of-the-art performance on MTEB among models that train only on publicly available data. Our strong empirical results and extensive analysis demonstrate that LLMs can be effectively transformed into universal text encoders in a parameter-efficient manner without the need for expensive adaptation or synthetic GPT-4 generated data.
4/10/2024
💬
Large Language Model (LLM) AI text generation detection based on transformer deep learning algorithm
Yuhong Mo, Hao Qin, Yushan Dong, Ziyi Zhu, Zhenglin Li
0
0
In this paper, a tool for detecting LLM AI text generation is developed based on the Transformer model, aiming to improve the accuracy of AI text generation detection and provide reference for subsequent research. Firstly the text is Unicode normalised, converted to lowercase form, characters other than non-alphabetic characters and punctuation marks are removed by regular expressions, spaces are added around punctuation marks, first and last spaces are removed, consecutive ellipses are replaced with single spaces and the text is connected using the specified delimiter. Next remove non-alphabetic characters and extra whitespace characters, replace multiple consecutive whitespace characters with a single space and again convert to lowercase form. The deep learning model combines layers such as LSTM, Transformer and CNN for text classification or sequence labelling tasks. The training and validation sets show that the model loss decreases from 0.127 to 0.005 and accuracy increases from 94.96 to 99.8, indicating that the model has good detection and classification ability for AI generated text. The test set confusion matrix and accuracy show that the model has 99% prediction accuracy for AI-generated text, with a precision of 0.99, a recall of 1, and an f1 score of 0.99, achieving a very high classification accuracy. Looking forward, it has the prospect of wide application in the field of AI text detection.
5/14/2024
Residual-based Language Models are Free Boosters for Biomedical Imaging
Zhixin Lai, Jing Wu, Suiyao Chen, Yucheng Zhou, Naira Hovakimyan
0
0
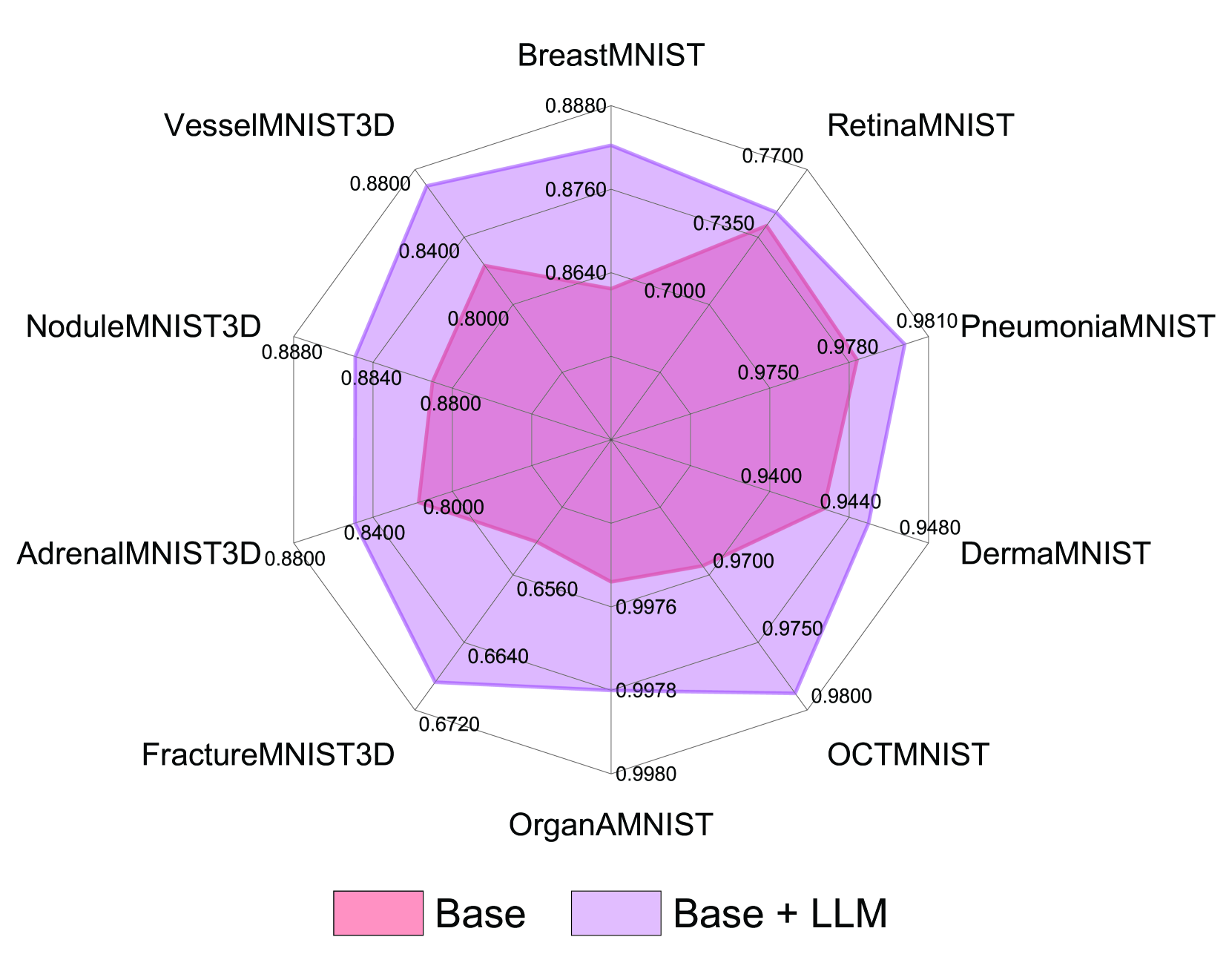
In this study, we uncover the unexpected efficacy of residual-based large language models (LLMs) as part of encoders for biomedical imaging tasks, a domain traditionally devoid of language or textual data. The approach diverges from established methodologies by utilizing a frozen transformer block, extracted from pre-trained LLMs, as an innovative encoder layer for the direct processing of visual tokens. This strategy represents a significant departure from the standard multi-modal vision-language frameworks, which typically hinge on language-driven prompts and inputs. We found that these LLMs could boost performance across a spectrum of biomedical imaging applications, including both 2D and 3D visual classification tasks, serving as plug-and-play boosters. More interestingly, as a byproduct, we found that the proposed framework achieved superior performance, setting new state-of-the-art results on extensive, standardized datasets in MedMNIST-2D and 3D. Through this work, we aim to open new avenues for employing LLMs in biomedical imaging and enriching the understanding of their potential in this specialized domain.
4/1/2024