EfficientViT-SAM: Accelerated Segment Anything Model Without Accuracy Loss

0
📈
Sign in to get full access
Overview
- Researchers present a new family of accelerated Segment Anything Models (SAM) called EfficientViT-SAM.
- EfficientViT-SAM retains SAM's lightweight prompt encoder and mask decoder while replacing the heavy image encoder with the more efficient EfficientViT.
- The training process involves knowledge distillation from the SAM-ViT-H image encoder to EfficientViT, followed by end-to-end training on the SA-1B dataset.
- EfficientViT-SAM delivers a 48.9x measured TensorRT speedup on A100 GPU over SAM-ViT-H without sacrificing performance.
- The code and pre-trained models are available on GitHub.
Plain English Explanation
The researchers have developed a new version of the Segment Anything Model (SAM) called EfficientViT-SAM. SAM is a machine learning model that can accurately segment, or outline, objects in an image, even if it's not clear what the object is.
The key innovation in EfficientViT-SAM is that it uses a more efficient image encoder called EfficientViT instead of the original, heavier encoder used in SAM. This makes the model faster and more efficient to run, without sacrificing its performance in segmenting objects.
The researchers trained EfficientViT-SAM using a two-step process. First, they used "knowledge distillation" to transfer the capabilities of the original, larger SAM encoder to the smaller EfficientViT encoder. Then, they trained the entire EfficientViT-SAM model end-to-end on a large dataset of segmented images.
The result is a Segment Anything Model that is nearly 50 times faster to run on a GPU compared to the original SAM, while maintaining its ability to accurately segment objects in images. The researchers have made the code and pre-trained models publicly available, so others can use and build upon their work.
Technical Explanation
The researchers present a new family of accelerated Segment Anything Models (SAM) called EfficientViT-SAM. They retain SAM's lightweight prompt encoder and mask decoder but replace the heavy image encoder with the more efficient EfficientViT architecture.
The training process begins with knowledge distillation, where the researchers transfer knowledge from the SAM-ViT-H image encoder to the EfficientViT encoder. This helps the smaller EfficientViT model learn the segmentation capabilities of the larger SAM encoder. Following this, they conduct end-to-end training on the SA-1B dataset, a large-scale segmentation dataset.
The resulting EfficientViT-SAM model delivers a remarkable 48.9x measured TensorRT speedup on an A100 GPU compared to the original SAM-ViT-H, without sacrificing performance. This significant acceleration is enabled by the efficiency and capacity of the EfficientViT architecture.
The researchers have released the code and pre-trained models for EfficientViT-SAM on GitHub, allowing others to build upon their work.
Critical Analysis
The researchers have addressed an important challenge in the field of computer vision - developing efficient and high-performing segmentation models. By replacing the heavy image encoder in SAM with the more lightweight EfficientViT, they have achieved impressive speedups without compromising the model's ability to accurately segment objects.
However, the paper does not provide extensive details on the specific performance trade-offs or limitations of the EfficientViT-SAM model. It would be useful to understand the exact performance metrics, such as segmentation accuracy, inference time, and memory usage, compared to the original SAM-ViT-H model and other state-of-the-art segmentation approaches.
Additionally, the researchers could explore the model's robustness to different types of images, varying object sizes, and challenging scenarios, as well as its generalization capabilities beyond the SA-1B dataset used for training. Investigating these aspects would help provide a more comprehensive understanding of the model's strengths and weaknesses.
Overall, the EfficientViT-SAM approach is a promising step forward in making high-performance segmentation models more accessible and practical for real-world applications. Further research and analysis could help refine the model and uncover additional insights.
Conclusion
The researchers have presented EfficientViT-SAM, a new family of accelerated Segment Anything Models that deliver significant performance improvements over the original SAM-ViT-H model. By replacing the heavy image encoder with the more efficient EfficientViT architecture and using a two-stage training process, the researchers have achieved a 48.9x speedup on A100 GPUs without sacrificing segmentation accuracy.
This work is an important contribution to the field of computer vision, as it demonstrates the potential for developing high-performing, yet efficient, segmentation models that can be more readily deployed in real-world applications. The public release of the code and pre-trained models will also enable other researchers and developers to build upon this work and further advance the state of the art in object segmentation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
EfficientViT-SAM: Accelerated Segment Anything Model Without Accuracy Loss
Zhuoyang Zhang, Han Cai, Song Han
We present EfficientViT-SAM, a new family of accelerated segment anything models. We retain SAM's lightweight prompt encoder and mask decoder while replacing the heavy image encoder with EfficientViT. For the training, we begin with the knowledge distillation from the SAM-ViT-H image encoder to EfficientViT. Subsequently, we conduct end-to-end training on the SA-1B dataset. Benefiting from EfficientViT's efficiency and capacity, EfficientViT-SAM delivers 48.9x measured TensorRT speedup on A100 GPU over SAM-ViT-H without sacrificing performance. Our code and pre-trained models are released at https://github.com/mit-han-lab/efficientvit.
Read more5/20/2024

0
RobustSAM: Segment Anything Robustly on Degraded Images
Wei-Ting Chen, Yu-Jiet Vong, Sy-Yen Kuo, Sizhuo Ma, Jian Wang
Segment Anything Model (SAM) has emerged as a transformative approach in image segmentation, acclaimed for its robust zero-shot segmentation capabilities and flexible prompting system. Nonetheless, its performance is challenged by images with degraded quality. Addressing this limitation, we propose the Robust Segment Anything Model (RobustSAM), which enhances SAM's performance on low-quality images while preserving its promptability and zero-shot generalization. Our method leverages the pre-trained SAM model with only marginal parameter increments and computational requirements. The additional parameters of RobustSAM can be optimized within 30 hours on eight GPUs, demonstrating its feasibility and practicality for typical research laboratories. We also introduce the Robust-Seg dataset, a collection of 688K image-mask pairs with different degradations designed to train and evaluate our model optimally. Extensive experiments across various segmentation tasks and datasets confirm RobustSAM's superior performance, especially under zero-shot conditions, underscoring its potential for extensive real-world application. Additionally, our method has been shown to effectively improve the performance of SAM-based downstream tasks such as single image dehazing and deblurring.
Read more6/17/2024
0
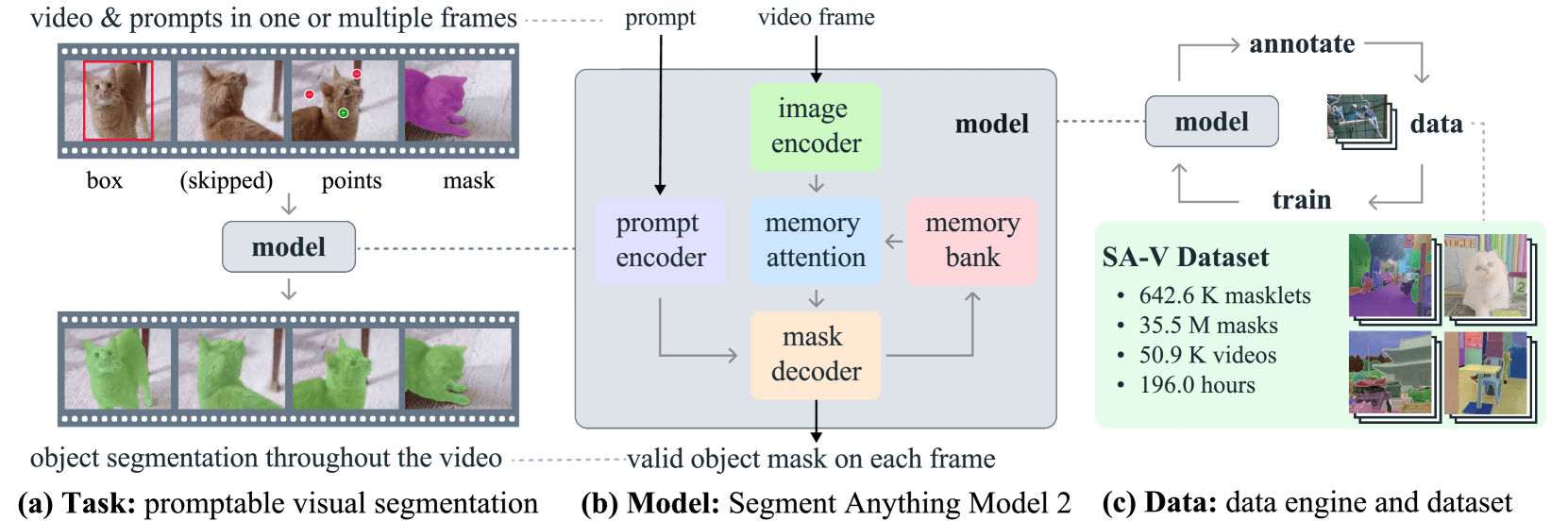
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Radle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Doll'ar, Christoph Feichtenhofer
We present Segment Anything Model 2 (SAM 2), a foundation model towards solving promptable visual segmentation in images and videos. We build a data engine, which improves model and data via user interaction, to collect the largest video segmentation dataset to date. Our model is a simple transformer architecture with streaming memory for real-time video processing. SAM 2 trained on our data provides strong performance across a wide range of tasks. In video segmentation, we observe better accuracy, using 3x fewer interactions than prior approaches. In image segmentation, our model is more accurate and 6x faster than the Segment Anything Model (SAM). We believe that our data, model, and insights will serve as a significant milestone for video segmentation and related perception tasks. We are releasing a version of our model, the dataset and an interactive demo.
Read more8/2/2024

0
From SAM to SAM 2: Exploring Improvements in Meta's Segment Anything Model
Athulya Sundaresan Geetha, Muhammad Hussain
The Segment Anything Model (SAM), introduced to the computer vision community by Meta in April 2023, is a groundbreaking tool that allows automated segmentation of objects in images based on prompts such as text, clicks, or bounding boxes. SAM excels in zero-shot performance, segmenting unseen objects without additional training, stimulated by a large dataset of over one billion image masks. SAM 2 expands this functionality to video, leveraging memory from preceding and subsequent frames to generate accurate segmentation across entire videos, enabling near real-time performance. This comparison shows how SAM has evolved to meet the growing need for precise and efficient segmentation in various applications. The study suggests that future advancements in models like SAM will be crucial for improving computer vision technology.
Read more8/13/2024