Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
2311.18259
0
0
🤔
Abstract
We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). 740 participants from 13 cities worldwide performed these activities in 123 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,286 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel expert commentary done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources are open sourced to fuel new research in the community. Project page: http://ego-exo4d-data.org/
Create account to get full access
Overview
- Ego-Exo4D is a large, diverse multimodal video dataset and benchmark challenge focused on skilled human activities.
- The dataset features simultaneously-captured egocentric (first-person) and exocentric (third-person) video, along with a wealth of additional sensor data.
- The dataset is designed to push the boundaries of first-person video understanding for skilled activities like sports, music, dance, and bike repair.
Plain English Explanation
Ego-Exo4D is a new dataset that aims to help computers better understand skilled human activities. It contains thousands of videos of people doing things like playing sports, playing music, dancing, and repairing bikes.
What makes this dataset unique is that it includes two different perspectives on these activities: a first-person view from the person doing the activity, and a third-person view from cameras watching them. This allows AI systems to see both what the person sees and what someone else sees while they're doing the activity.
In addition to the videos, the dataset also includes other data like audio, eye gaze tracking, 3D point clouds, camera positions, and written descriptions of the activities - even expert commentary from coaches and teachers. This allows AI systems to analyze the activities in much more detail.
The goal is to push the boundaries of how well computers can understand skilled human activities, like estimating 3D hand and body pose or translating between first-person and third-person views. This could lead to better AI assistants, video analysis tools, and augmented reality applications.
Technical Explanation
Ego-Exo4D is a large-scale multimodal video dataset that captures skilled human activities from both egocentric (first-person) and exocentric (third-person) perspectives. The dataset includes 1,286 hours of video across 740 participants in 13 cities, with activities ranging from sports and music to dance and bike repair.
In addition to the video, the dataset includes a wealth of accompanying sensor data, including multichannel audio, eye gaze, 3D point clouds, camera poses, and inertial measurement units (IMUs). This multimodal data allows for detailed analysis of the activities beyond just the visual aspects.
The dataset also includes novel language annotations, such as expert commentary from coaches and teachers tailored to the specific skilled activities. This provides valuable contextual information to complement the sensor data.
To benchmark the capabilities of AI systems on this data, the authors present a suite of tasks, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose estimation. These tasks are designed to push the frontiers of first-person video understanding.
The dataset and associated resources are open-sourced to fuel new research in the community.
Critical Analysis
The Ego-Exo4D dataset and benchmark represent a significant advancement in the field of first-person video understanding. By capturing skilled activities from multiple perspectives and with a wealth of additional sensor data, the authors have created a unique resource for developing more holistic models of human behavior and performance.
One potential limitation of the dataset is the scope - while it covers a diverse range of activities, the number of participants and scenes may not be sufficient to fully capture the breadth of human expertise and environmental variation. Additionally, the language annotations, while novel, may be biased by the specific coaches and teachers involved.
Further research could explore ways to generate synthetic egocentric data to augment the dataset, or investigate techniques for leveraging the multimodal data to improve cross-view understanding and activity analysis.
Overall, Ego-Exo4D represents an important step forward in the quest to build AI systems that can truly comprehend and interact with skilled human activities in naturalistic settings.
Conclusion
The Ego-Exo4D dataset and benchmark challenge provide a powerful new resource for advancing the field of first-person video understanding. By capturing skilled human activities from multiple perspectives and with rich multimodal data, the authors have created a unique testbed for developing AI systems that can better comprehend and assist with complex real-world tasks.
The open-sourcing of this dataset and associated resources will undoubtedly fuel new research and innovation in areas like activity recognition, proficiency estimation, and cross-view translation. As these capabilities continue to improve, we can expect to see significant advancements in applications like video analysis, augmented reality, and human-robot interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

EgoExoLearn: A Dataset for Bridging Asynchronous Ego- and Exo-centric View of Procedural Activities in Real World
Yifei Huang, Guo Chen, Jilan Xu, Mingfang Zhang, Lijin Yang, Baoqi Pei, Hongjie Zhang, Lu Dong, Yali Wang, Limin Wang, Yu Qiao
0
0
Being able to map the activities of others into one's own point of view is one fundamental human skill even from a very early age. Taking a step toward understanding this human ability, we introduce EgoExoLearn, a large-scale dataset that emulates the human demonstration following process, in which individuals record egocentric videos as they execute tasks guided by demonstration videos. Focusing on the potential applications in daily assistance and professional support, EgoExoLearn contains egocentric and demonstration video data spanning 120 hours captured in daily life scenarios and specialized laboratories. Along with the videos we record high-quality gaze data and provide detailed multimodal annotations, formulating a playground for modeling the human ability to bridge asynchronous procedural actions from different viewpoints. To this end, we present benchmarks such as cross-view association, cross-view action planning, and cross-view referenced skill assessment, along with detailed analysis. We expect EgoExoLearn can serve as an important resource for bridging the actions across views, thus paving the way for creating AI agents capable of seamlessly learning by observing humans in the real world. Code and data can be found at: https://github.com/OpenGVLab/EgoExoLearn
6/6/2024
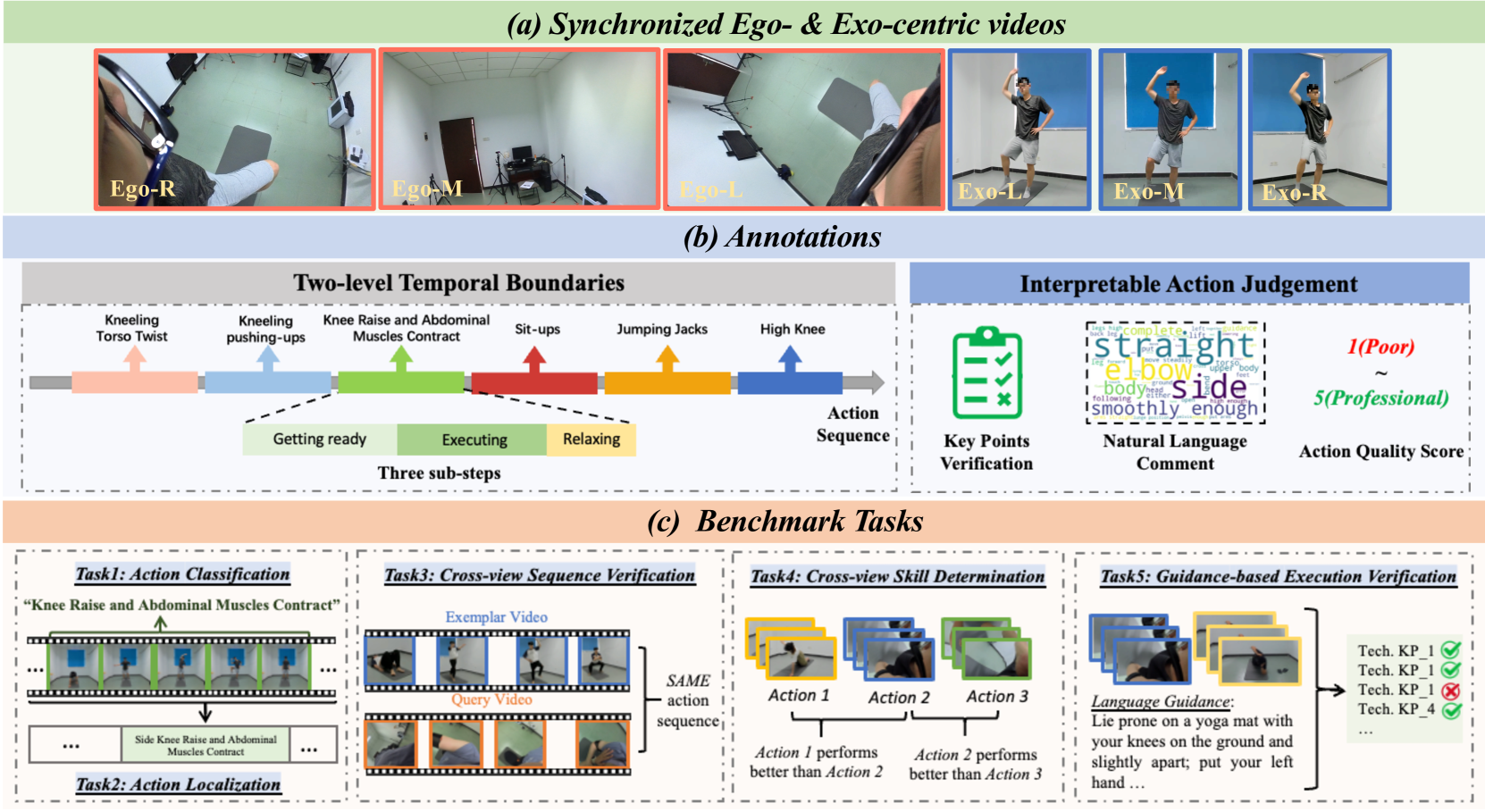
EgoExo-Fitness: Towards Egocentric and Exocentric Full-Body Action Understanding
Yuan-Ming Li, Wei-Jin Huang, An-Lan Wang, Ling-An Zeng, Jing-Ke Meng, Wei-Shi Zheng
0
0
We present EgoExo-Fitness, a new full-body action understanding dataset, featuring fitness sequence videos recorded from synchronized egocentric and fixed exocentric (third-person) cameras. Compared with existing full-body action understanding datasets, EgoExo-Fitness not only contains videos from first-person perspectives, but also provides rich annotations. Specifically, two-level temporal boundaries are provided to localize single action videos along with sub-steps of each action. More importantly, EgoExo-Fitness introduces innovative annotations for interpretable action judgement--including technical keypoint verification, natural language comments on action execution, and action quality scores. Combining all of these, EgoExo-Fitness provides new resources to study egocentric and exocentric full-body action understanding across dimensions of what, when, and how well. To facilitate research on egocentric and exocentric full-body action understanding, we construct benchmarks on a suite of tasks (i.e., action classification, action localization, cross-view sequence verification, cross-view skill determination, and a newly proposed task of guidance-based execution verification), together with detailed analysis. Code and data will be available at https://github.com/iSEE-Laboratory/EgoExo-Fitness/tree/main.
6/14/2024

Retrieval-Augmented Egocentric Video Captioning
Jilan Xu, Yifei Huang, Junlin Hou, Guo Chen, Yuejie Zhang, Rui Feng, Weidi Xie
0
0
Understanding human actions from videos of first-person view poses significant challenges. Most prior approaches explore representation learning on egocentric videos only, while overlooking the potential benefit of exploiting existing large-scale third-person videos. In this paper, (1) we develop EgoInstructor, a retrieval-augmented multimodal captioning model that automatically retrieves semantically relevant third-person instructional videos to enhance the video captioning of egocentric videos. (2) For training the cross-view retrieval module, we devise an automatic pipeline to discover ego-exo video pairs from distinct large-scale egocentric and exocentric datasets. (3) We train the cross-view retrieval module with a novel EgoExoNCE loss that pulls egocentric and exocentric video features closer by aligning them to shared text features that describe similar actions. (4) Through extensive experiments, our cross-view retrieval module demonstrates superior performance across seven benchmarks. Regarding egocentric video captioning, EgoInstructor exhibits significant improvements by leveraging third-person videos as references. Project page is available at: https://jazzcharles.github.io/Egoinstructor/
6/21/2024

New!EgoGaussian: Dynamic Scene Understanding from Egocentric Video with 3D Gaussian Splatting
Daiwei Zhang, Gengyan Li, Jiajie Li, Mickael Bressieux, Otmar Hilliges, Marc Pollefeys, Luc Van Gool, Xi Wang
0
0
Human activities are inherently complex, and even simple household tasks involve numerous object interactions. To better understand these activities and behaviors, it is crucial to model their dynamic interactions with the environment. The recent availability of affordable head-mounted cameras and egocentric data offers a more accessible and efficient means to understand dynamic human-object interactions in 3D environments. However, most existing methods for human activity modeling either focus on reconstructing 3D models of hand-object or human-scene interactions or on mapping 3D scenes, neglecting dynamic interactions with objects. The few existing solutions often require inputs from multiple sources, including multi-camera setups, depth-sensing cameras, or kinesthetic sensors. To this end, we introduce EgoGaussian, the first method capable of simultaneously reconstructing 3D scenes and dynamically tracking 3D object motion from RGB egocentric input alone. We leverage the uniquely discrete nature of Gaussian Splatting and segment dynamic interactions from the background. Our approach employs a clip-level online learning pipeline that leverages the dynamic nature of human activities, allowing us to reconstruct the temporal evolution of the scene in chronological order and track rigid object motion. Additionally, our method automatically segments object and background Gaussians, providing 3D representations for both static scenes and dynamic objects. EgoGaussian outperforms previous NeRF and Dynamic Gaussian methods in challenging in-the-wild videos and we also qualitatively demonstrate the high quality of the reconstructed models.
7/1/2024