EgoExo-Fitness: Towards Egocentric and Exocentric Full-Body Action Understanding
2406.08877
0
0
Abstract
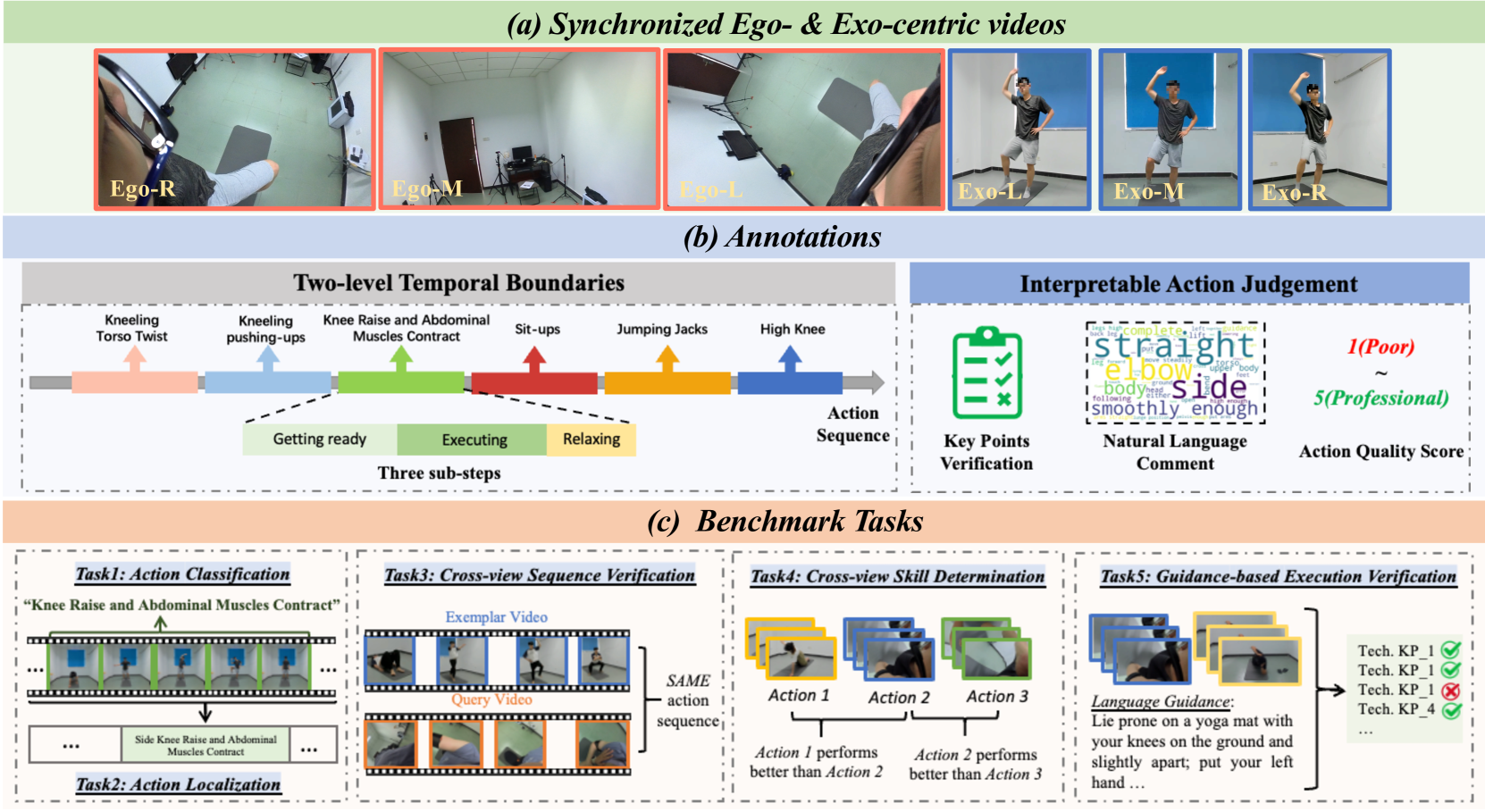
We present EgoExo-Fitness, a new full-body action understanding dataset, featuring fitness sequence videos recorded from synchronized egocentric and fixed exocentric (third-person) cameras. Compared with existing full-body action understanding datasets, EgoExo-Fitness not only contains videos from first-person perspectives, but also provides rich annotations. Specifically, two-level temporal boundaries are provided to localize single action videos along with sub-steps of each action. More importantly, EgoExo-Fitness introduces innovative annotations for interpretable action judgement--including technical keypoint verification, natural language comments on action execution, and action quality scores. Combining all of these, EgoExo-Fitness provides new resources to study egocentric and exocentric full-body action understanding across dimensions of what, when, and how well. To facilitate research on egocentric and exocentric full-body action understanding, we construct benchmarks on a suite of tasks (i.e., action classification, action localization, cross-view sequence verification, cross-view skill determination, and a newly proposed task of guidance-based execution verification), together with detailed analysis. Code and data will be available at https://github.com/iSEE-Laboratory/EgoExo-Fitness/tree/main.
Create account to get full access
Overview
- The paper presents the "EgoExo-Fitness" dataset, which captures full-body actions from both egocentric (first-person) and exocentric (third-person) perspectives during fitness activities.
- The dataset aims to enable research on understanding skilled human activity from multimodal video data, bridging the gap between egocentric and exocentric viewpoints.
- The paper also introduces a new action recognition model that can effectively learn from and predict actions across both egocentric and exocentric views.
Plain English Explanation
The researchers have created a new dataset called "EgoExo-Fitness" that captures people doing fitness activities from two different camera perspectives - first-person (egocentric) and third-person (exocentric). This dataset can be used to train AI systems to better understand human actions and movements, particularly skilled activities like fitness exercises.
Traditionally, action recognition models have been trained on data from either egocentric or exocentric viewpoints, but not both. This new dataset bridges that gap, allowing AI models to learn from the complementary information provided by these different camera perspectives. The researchers also developed a new AI model that can effectively learn from and predict actions across both egocentric and exocentric views.
This work is significant because it can lead to advancements in areas like retrieval-augmented egocentric video captioning, object-aware egocentric online action detection, and understanding skilled human activity from ego-exo perspectives. By combining information from first-person and third-person views, AI systems can gain a more comprehensive understanding of human actions and movements, with potential applications in fitness training, sports analysis, and assistive technologies.
Technical Explanation
The paper introduces the "EgoExo-Fitness" dataset, which contains video data of people performing various fitness activities from both egocentric (first-person) and exocentric (third-person) viewpoints. The dataset is designed to enable research on cross-view action recognition and understanding, bridging the gap between these two distinct perspectives.
The dataset includes annotations for full-body actions, such as squats, lunges, and jumping jacks, captured using multiple cameras and wearable sensors. This multimodal data allows AI models to learn from the complementary information provided by the different viewpoints, leading to more robust and generalizable action recognition capabilities.
The paper also introduces a new action recognition model that can effectively learn from and predict actions across both egocentric and exocentric views. This model leverages cross-view feature learning and adaption techniques to overcome the domain shift between the two perspectives, enabling accurate action recognition in both settings.
The authors evaluate their approach on the EgoExo-Fitness dataset and demonstrate significant performance improvements compared to existing action recognition models trained on either egocentric or exocentric data alone. This suggests that the combined use of egocentric and exocentric information can lead to more comprehensive and accurate understanding of human actions and movements.
Critical Analysis
The EgoExo-Fitness dataset and the proposed action recognition model are valuable contributions to the field of human activity understanding. By bridging the gap between egocentric and exocentric perspectives, the research opens up new possibilities for more holistic and context-aware action recognition systems.
However, the paper does not delve into the potential limitations or drawbacks of the dataset or the model. For example, the dataset may be limited in its diversity of fitness activities or the number of participants, which could impact the generalizability of the findings. Additionally, the authors do not discuss the computational and memory requirements of their model, which could be a concern for real-world applications.
Furthermore, the paper does not address the ethical considerations surrounding the use of such technology, such as privacy concerns or the potential for misuse in areas like surveillance or worker monitoring. These are important aspects that should be carefully considered as the field of human action understanding continues to evolve.
Despite these potential limitations, the EgoExo-Fitness dataset and the proposed action recognition model represent a significant step forward in the quest to understand skilled human activity from ego-exo perspectives. By combining multiple viewpoints, the research can lead to more nuanced and holistic understanding of human behavior, with applications in fields like fitness, sports, and assistive technologies.
Conclusion
The EgoExo-Fitness dataset and the associated action recognition model presented in this paper are important contributions to the field of human activity understanding. By bridging the gap between egocentric and exocentric perspectives, the research enables more comprehensive and context-aware action recognition, with potential applications in areas like retrieval-augmented egocentric video captioning and object-aware egocentric online action detection.
The availability of this multimodal dataset and the introduction of a cross-view action recognition model are significant steps towards understanding skilled human activity from ego-exo perspectives and cross-view action recognition and understanding. As the field continues to evolve, it will be important to address the potential limitations and ethical considerations surrounding the use of such technologies to ensure they are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

EgoExoLearn: A Dataset for Bridging Asynchronous Ego- and Exo-centric View of Procedural Activities in Real World
Yifei Huang, Guo Chen, Jilan Xu, Mingfang Zhang, Lijin Yang, Baoqi Pei, Hongjie Zhang, Lu Dong, Yali Wang, Limin Wang, Yu Qiao
0
0
Being able to map the activities of others into one's own point of view is one fundamental human skill even from a very early age. Taking a step toward understanding this human ability, we introduce EgoExoLearn, a large-scale dataset that emulates the human demonstration following process, in which individuals record egocentric videos as they execute tasks guided by demonstration videos. Focusing on the potential applications in daily assistance and professional support, EgoExoLearn contains egocentric and demonstration video data spanning 120 hours captured in daily life scenarios and specialized laboratories. Along with the videos we record high-quality gaze data and provide detailed multimodal annotations, formulating a playground for modeling the human ability to bridge asynchronous procedural actions from different viewpoints. To this end, we present benchmarks such as cross-view association, cross-view action planning, and cross-view referenced skill assessment, along with detailed analysis. We expect EgoExoLearn can serve as an important resource for bridging the actions across views, thus paving the way for creating AI agents capable of seamlessly learning by observing humans in the real world. Code and data can be found at: https://github.com/OpenGVLab/EgoExoLearn
6/6/2024
🤔
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, Eugene Byrne, Zach Chavis, Joya Chen, Feng Cheng, Fu-Jen Chu, Sean Crane, Avijit Dasgupta, Jing Dong, Maria Escobar, Cristhian Forigua, Abrham Gebreselasie, Sanjay Haresh, Jing Huang, Md Mohaiminul Islam, Suyog Jain, Rawal Khirodkar, Devansh Kukreja, Kevin J Liang, Jia-Wei Liu, Sagnik Majumder, Yongsen Mao, Miguel Martin, Effrosyni Mavroudi, Tushar Nagarajan, Francesco Ragusa, Santhosh Kumar Ramakrishnan, Luigi Seminara, Arjun Somayazulu, Yale Song, Shan Su, Zihui Xue, Edward Zhang, Jinxu Zhang, Angela Castillo, Changan Chen, Xinzhu Fu, Ryosuke Furuta, Cristina Gonzalez, Prince Gupta, Jiabo Hu, Yifei Huang, Yiming Huang, Weslie Khoo, Anush Kumar, Robert Kuo, Sach Lakhavani, Miao Liu, Mi Luo, Zhengyi Luo, Brighid Meredith, Austin Miller, Oluwatumininu Oguntola, Xiaqing Pan, Penny Peng, Shraman Pramanick, Merey Ramazanova, Fiona Ryan, Wei Shan, Kiran Somasundaram, Chenan Song, Audrey Southerland, Masatoshi Tateno, Huiyu Wang, Yuchen Wang, Takuma Yagi, Mingfei Yan, Xitong Yang, Zecheng Yu, Shengxin Cindy Zha, Chen Zhao, Ziwei Zhao, Zhifan Zhu, Jeff Zhuo, Pablo Arbelaez, Gedas Bertasius, David Crandall, Dima Damen, Jakob Engel, Giovanni Maria Farinella, Antonino Furnari, Bernard Ghanem, Judy Hoffman, C. V. Jawahar, Richard Newcombe, Hyun Soo Park, James M. Rehg, Yoichi Sato, Manolis Savva, Jianbo Shi, Mike Zheng Shou, Michael Wray
0
0
We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). 740 participants from 13 cities worldwide performed these activities in 123 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,286 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel expert commentary done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources are open sourced to fuel new research in the community. Project page: http://ego-exo4d-data.org/
4/30/2024
👁️
Cross-view Action Recognition Understanding From Exocentric to Egocentric Perspective
Thanh-Dat Truong, Khoa Luu
0
0
Understanding action recognition in egocentric videos has emerged as a vital research topic with numerous practical applications. With the limitation in the scale of egocentric data collection, learning robust deep learning-based action recognition models remains difficult. Transferring knowledge learned from the large-scale exocentric data to the egocentric data is challenging due to the difference in videos across views. Our work introduces a novel cross-view learning approach to action recognition (CVAR) that effectively transfers knowledge from the exocentric to the selfish view. First, we present a novel geometric-based constraint into the self-attention mechanism in Transformer based on analyzing the camera positions between two views. Then, we propose a new cross-view self-attention loss learned on unpaired cross-view data to enforce the self-attention mechanism learning to transfer knowledge across views. Finally, to further improve the performance of our cross-view learning approach, we present the metrics to measure the correlations in videos and attention maps effectively. Experimental results on standard egocentric action recognition benchmarks, i.e., Charades-Ego, EPIC-Kitchens-55, and EPIC-Kitchens-100, have shown our approach's effectiveness and state-of-the-art performance.
5/16/2024

Retrieval-Augmented Egocentric Video Captioning
Jilan Xu, Yifei Huang, Junlin Hou, Guo Chen, Yuejie Zhang, Rui Feng, Weidi Xie
0
0
Understanding human actions from videos of first-person view poses significant challenges. Most prior approaches explore representation learning on egocentric videos only, while overlooking the potential benefit of exploiting existing large-scale third-person videos. In this paper, (1) we develop EgoInstructor, a retrieval-augmented multimodal captioning model that automatically retrieves semantically relevant third-person instructional videos to enhance the video captioning of egocentric videos. (2) For training the cross-view retrieval module, we devise an automatic pipeline to discover ego-exo video pairs from distinct large-scale egocentric and exocentric datasets. (3) We train the cross-view retrieval module with a novel EgoExoNCE loss that pulls egocentric and exocentric video features closer by aligning them to shared text features that describe similar actions. (4) Through extensive experiments, our cross-view retrieval module demonstrates superior performance across seven benchmarks. Regarding egocentric video captioning, EgoInstructor exhibits significant improvements by leveraging third-person videos as references. Project page is available at: https://jazzcharles.github.io/Egoinstructor/
6/21/2024