EgoFlowNet: Non-Rigid Scene Flow from Point Clouds with Ego-Motion Support

0
Sign in to get full access
Overview
- This paper presents EgoFlowNet, a deep learning-based method for estimating non-rigid scene flow from point cloud data, with support for ego-motion.
- The proposed approach aims to accurately capture both the motion of the camera (ego-motion) and the non-rigid motion of objects in the scene.
- EgoFlowNet leverages a novel network architecture and training strategy to learn effective representations for scene flow estimation.
Plain English Explanation
EgoFlowNet is a new AI system that can analyze 3D point cloud data (like that captured by a depth camera) and understand the motion happening in the scene. It can detect both the movement of the camera itself (the "ego-motion") and the movement of objects and people within the scene (the "non-rigid motion").
This is useful for applications like autonomous vehicles, augmented reality, and robotics, where understanding the dynamic 3D environment is crucial. Previous methods have struggled to accurately capture both the camera motion and the independent object motion, but EgoFlowNet aims to solve this problem.
The key innovation in EgoFlowNet is its novel neural network architecture and training approach. The network is designed to learn effective representations of the 3D scene and the different types of motion happening within it. Through careful training, the system can parse out the camera movement from the independent object movements, allowing it to provide a comprehensive understanding of the 3D scene flow.
Technical Explanation
The EgoFlowNet architecture consists of several key components:
-
Ego-motion Estimation Module: This module takes the input point cloud data and estimates the camera's 3D motion (translation and rotation) between consecutive frames.
-
Non-Rigid Motion Estimation Module: This module analyzes the residual motion in the point cloud data after accounting for the estimated ego-motion, allowing it to detect the independent movement of objects and people.
-
Feature Extraction and Aggregation: The system extracts and aggregates multi-scale features from the point cloud data to capture both local and global context, which is important for accurate scene flow estimation.
-
Iterative Refinement: EgoFlowNet uses an iterative refinement process, where the estimated ego-motion and non-rigid motion are repeatedly refined to improve the overall scene flow prediction.
The authors propose a novel training strategy that jointly optimizes the ego-motion estimation, non-rigid motion estimation, and scene flow prediction tasks. This helps the network learn effective representations that can accurately capture the complex 3D motion dynamics in the scene.
Critical Analysis
The authors acknowledge several limitations and areas for future work:
- The current implementation assumes a static background, which may not hold true in all real-world scenarios. Extending the method to handle dynamic backgrounds could further improve its applicability.
- The network architecture and training process could potentially be made more efficient, which would be important for real-time applications like Let It Flow: Simultaneous Optimization of 3D Flow or SSFlowNet: Semi-Supervised Scene Flow Estimation from Point Clouds.
- Evaluating the method's performance on larger and more diverse datasets, such as those used in RMS-FlowNet: Efficient and Robust Multi-Scale Scene Flow Estimation from Point Clouds or CMU-FlowNet: Exploring Point Cloud Scene Flow, could provide a more comprehensive understanding of its capabilities and limitations.
- The authors mention the potential for attacking scene flow using point clouds, which could be an important consideration for real-world deployment.
Overall, EgoFlowNet represents a promising step forward in the field of 3D scene flow estimation, with its ability to jointly handle ego-motion and non-rigid motion. Further research and development in this area could lead to important advancements in various applications involving dynamic 3D environments.
Conclusion
The EgoFlowNet paper presents a novel deep learning-based approach for estimating non-rigid scene flow from point cloud data, with the ability to account for the camera's own motion (ego-motion). This is a significant advance over previous methods that struggled to separate the camera motion from the independent object motions.
The proposed architecture and training strategy allow EgoFlowNet to learn effective representations for accurately capturing the complex 3D motion dynamics in a scene. This could have important implications for applications such as autonomous vehicles, augmented reality, and robotics, where understanding the dynamic environment is crucial for safe and intelligent operation.
While the method has some limitations that require further research, the core ideas and contributions of EgoFlowNet represent an important step forward in the field of 3D scene flow estimation. Continued advancements in this area could lead to more robust and reliable systems for perceiving and navigating dynamic 3D environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EgoFlowNet: Non-Rigid Scene Flow from Point Clouds with Ego-Motion Support
Ramy Battrawy, Ren'e Schuster, Didier Stricker
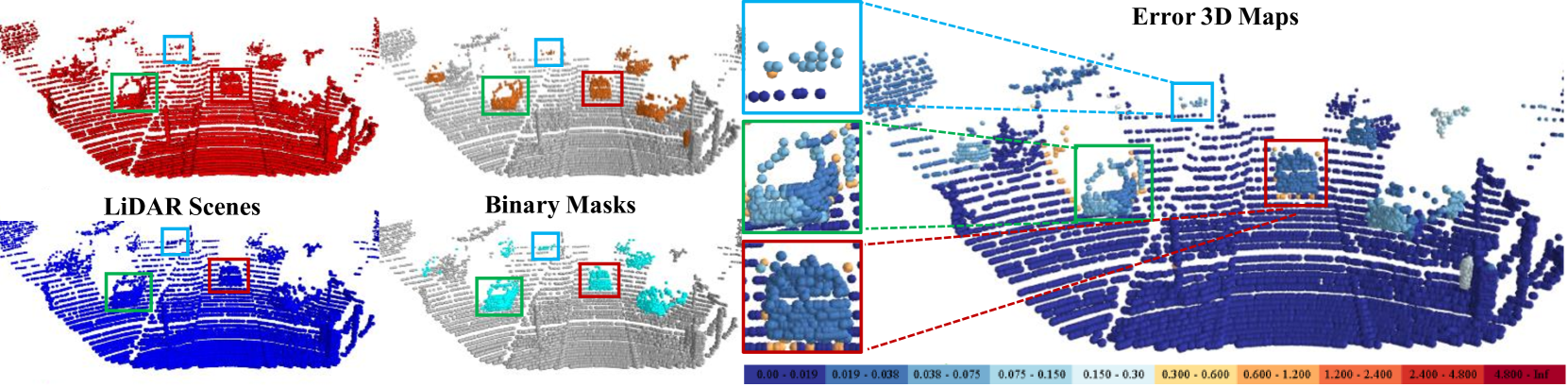
Recent weakly-supervised methods for scene flow estimation from LiDAR point clouds are limited to explicit reasoning on object-level. These methods perform multiple iterative optimizations for each rigid object, which makes them vulnerable to clustering robustness. In this paper, we propose our EgoFlowNet - a point-level scene flow estimation network trained in a weakly-supervised manner and without object-based abstraction. Our approach predicts a binary segmentation mask that implicitly drives two parallel branches for ego-motion and scene flow. Unlike previous methods, we provide both branches with all input points and carefully integrate the binary mask into the feature extraction and losses. We also use a shared cost volume with local refinement that is updated at multiple scales without explicit clustering or rigidity assumptions. On realistic KITTI scenes, we show that our EgoFlowNet performs better than state-of-the-art methods in the presence of ground surface points.
Read more7/4/2024

0
Let It Flow: Simultaneous Optimization of 3D Flow and Object Clustering
Patrik Vacek, David Hurych, Tom'av{s} Svoboda, Karel Zimmermann
We study the problem of self-supervised 3D scene flow estimation from real large-scale raw point cloud sequences, which is crucial to various tasks like trajectory prediction or instance segmentation. In the absence of ground truth scene flow labels, contemporary approaches concentrate on deducing optimizing flow across sequential pairs of point clouds by incorporating structure based regularization on flow and object rigidity. The rigid objects are estimated by a variety of 3D spatial clustering methods. While state-of-the-art methods successfully capture overall scene motion using the Neural Prior structure, they encounter challenges in discerning multi-object motions. We identified the structural constraints and the use of large and strict rigid clusters as the main pitfall of the current approaches and we propose a novel clustering approach that allows for combination of overlapping soft clusters as well as non-overlapping rigid clusters representation. Flow is then jointly estimated with progressively growing non-overlapping rigid clusters together with fixed size overlapping soft clusters. We evaluate our method on multiple datasets with LiDAR point clouds, demonstrating the superior performance over the self-supervised baselines reaching new state of the art results. Our method especially excels in resolving flow in complicated dynamic scenes with multiple independently moving objects close to each other which includes pedestrians, cyclists and other vulnerable road users. Our codes are publicly available on https://github.com/ctu-vras/let-it-flow.
Read more8/14/2024

0
SSFlowNet: Semi-supervised Scene Flow Estimation On Point Clouds With Pseudo Label
Jingze Chen, Junfeng Yao, Qiqin Lin, Rongzhou Zhou, Lei Li
In the domain of supervised scene flow estimation, the process of manual labeling is both time-intensive and financially demanding. This paper introduces SSFlowNet, a semi-supervised approach for scene flow estimation, that utilizes a blend of labeled and unlabeled data, optimizing the balance between the cost of labeling and the precision of model training. SSFlowNet stands out through its innovative use of pseudo-labels, mainly reducing the dependency on extensively labeled datasets while maintaining high model accuracy. The core of our model is its emphasis on the intricate geometric structures of point clouds, both locally and globally, coupled with a novel spatial memory feature. This feature is adept at learning the geometric relationships between points over sequential time frames. By identifying similarities between labeled and unlabeled points, SSFlowNet dynamically constructs a correlation matrix to evaluate scene flow dependencies at individual point level. Furthermore, the integration of a flow consistency module within SSFlowNet enhances its capability to consistently estimate flow, an essential aspect for analyzing dynamic scenes. Empirical results demonstrate that SSFlowNet surpasses existing methods in pseudo-label generation and shows adaptability across varying data volumes. Moreover, our semi-supervised training technique yields promising outcomes even with different smaller ratio labeled data, marking a substantial advancement in the field of scene flow estimation.
Read more6/5/2024

0
SeFlow: A Self-Supervised Scene Flow Method in Autonomous Driving
Qingwen Zhang, Yi Yang, Peizheng Li, Olov Andersson, Patric Jensfelt
Scene flow estimation predicts the 3D motion at each point in successive LiDAR scans. This detailed, point-level, information can help autonomous vehicles to accurately predict and understand dynamic changes in their surroundings. Current state-of-the-art methods require annotated data to train scene flow networks and the expense of labeling inherently limits their scalability. Self-supervised approaches can overcome the above limitations, yet face two principal challenges that hinder optimal performance: point distribution imbalance and disregard for object-level motion constraints. In this paper, we propose SeFlow, a self-supervised method that integrates efficient dynamic classification into a learning-based scene flow pipeline. We demonstrate that classifying static and dynamic points helps design targeted objective functions for different motion patterns. We also emphasize the importance of internal cluster consistency and correct object point association to refine the scene flow estimation, in particular on object details. Our real-time capable method achieves state-of-the-art performance on the self-supervised scene flow task on Argoverse 2 and Waymo datasets. The code is open-sourced at https://github.com/KTH-RPL/SeFlow along with trained model weights.
Read more9/18/2024