EgoVideo: Exploring Egocentric Foundation Model and Downstream Adaptation
2406.18070
0
0
📈
Abstract
In this report, we present our solutions to the EgoVis Challenges in CVPR 2024, including five tracks in the Ego4D challenge and three tracks in the EPIC-Kitchens challenge. Building upon the video-language two-tower model and leveraging our meticulously organized egocentric video data, we introduce a novel foundation model called EgoVideo. This model is specifically designed to cater to the unique characteristics of egocentric videos and provides strong support for our competition submissions. In the Ego4D challenges, we tackle various tasks including Natural Language Queries, Step Grounding, Moment Queries, Short-term Object Interaction Anticipation, and Long-term Action Anticipation. In addition, we also participate in the EPIC-Kitchens challenge, where we engage in the Action Recognition, Multiple Instance Retrieval, and Domain Adaptation for Action Recognition tracks. By adapting EgoVideo to these diverse tasks, we showcase its versatility and effectiveness in different egocentric video analysis scenarios, demonstrating the powerful representation ability of EgoVideo as an egocentric foundation model. Our codebase and pretrained models are publicly available at https://github.com/OpenGVLab/EgoVideo.
Create account to get full access
Overview
- This paper introduces EgoVideo, a new foundation model for egocentric video understanding.
- EgoVideo is trained on a large-scale dataset of first-person video to learn robust representations for downstream tasks.
- The paper explores the capabilities of EgoVideo and how it can be adapted for different applications like video captioning, action recognition, and object detection.
Plain English Explanation
The paper describes a new AI model called EgoVideo that is designed to understand and process first-person or "egocentric" video. Egocentric video refers to video recorded from the perspective of the person wearing the camera, rather than an external observer.
EgoVideo is a "foundation model" - a large, general-purpose model that can be fine-tuned for specific tasks. The researchers trained EgoVideo on a huge dataset of egocentric video to teach it to recognize common patterns and extract meaningful information from this type of footage.
The paper then demonstrates how EgoVideo can be adapted and applied to various downstream tasks, such as describing the contents of a video, detecting actions, and understanding the user's environment. This shows the versatility of the EgoVideo model and its potential to advance research in egocentric vision and embodied AI.
Technical Explanation
The training process for EgoVideo involves pretraining the model on a large-scale dataset of first-person video. This dataset covers a diverse range of scenes, activities, and objects that the model learns to recognize and reason about. The pretraining objective encourages the model to extract useful visual and temporal features from the egocentric video.
After pretraining, EgoVideo can be fine-tuned on specific downstream tasks by adding task-specific heads and continuing the training process. The paper demonstrates this process for video captioning, action recognition, and object detection, showing how EgoVideo can be adapted to excel at these different applications.
The model architecture of EgoVideo builds upon recent advances in transformer-based vision-language models. It consists of a visual encoder, a language model, and multimodal fusion components that allow the model to reason about the ego-centric video and language jointly.
Critical Analysis
The paper provides a thorough exploration of the EgoVideo model and its capabilities, highlighting its potential to advance research in egocentric vision and embodied AI. However, the authors acknowledge that the model has limitations, such as its dependency on the quality and diversity of the pretraining dataset.
Additionally, while the paper demonstrates strong performance on several downstream tasks, the authors note that further research is needed to fully understand the model's limitations and potential biases. For example, the model may perform better on certain types of egocentric video or tasks compared to others, and its robustness to variations in the input data should be further investigated.
As with any foundation model, there are also concerns about potential misuse or unintended consequences that should be carefully considered as this technology is developed and deployed. The authors encourage the research community to continue studying these issues and to work towards responsible development of egocentric vision AI systems.
Conclusion
The EgoVideo paper presents a significant advancement in the field of egocentric video understanding, introducing a versatile foundation model that can be adapted for a wide range of downstream applications. By leveraging large-scale pretraining on first-person video data, EgoVideo demonstrates strong performance on tasks like video captioning, action recognition, and object detection.
The work highlights the potential of egocentric vision AI to enable new human-centric applications and to deepen our understanding of human perception and cognition. As the authors note, further research is needed to fully explore the capabilities and limitations of EgoVideo and similar models, but this paper marks an important step forward in this rapidly evolving field of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Retrieval-Augmented Egocentric Video Captioning
Jilan Xu, Yifei Huang, Junlin Hou, Guo Chen, Yuejie Zhang, Rui Feng, Weidi Xie
0
0
Understanding human actions from videos of first-person view poses significant challenges. Most prior approaches explore representation learning on egocentric videos only, while overlooking the potential benefit of exploiting existing large-scale third-person videos. In this paper, (1) we develop EgoInstructor, a retrieval-augmented multimodal captioning model that automatically retrieves semantically relevant third-person instructional videos to enhance the video captioning of egocentric videos. (2) For training the cross-view retrieval module, we devise an automatic pipeline to discover ego-exo video pairs from distinct large-scale egocentric and exocentric datasets. (3) We train the cross-view retrieval module with a novel EgoExoNCE loss that pulls egocentric and exocentric video features closer by aligning them to shared text features that describe similar actions. (4) Through extensive experiments, our cross-view retrieval module demonstrates superior performance across seven benchmarks. Regarding egocentric video captioning, EgoInstructor exhibits significant improvements by leveraging third-person videos as references. Project page is available at: https://jazzcharles.github.io/Egoinstructor/
6/21/2024
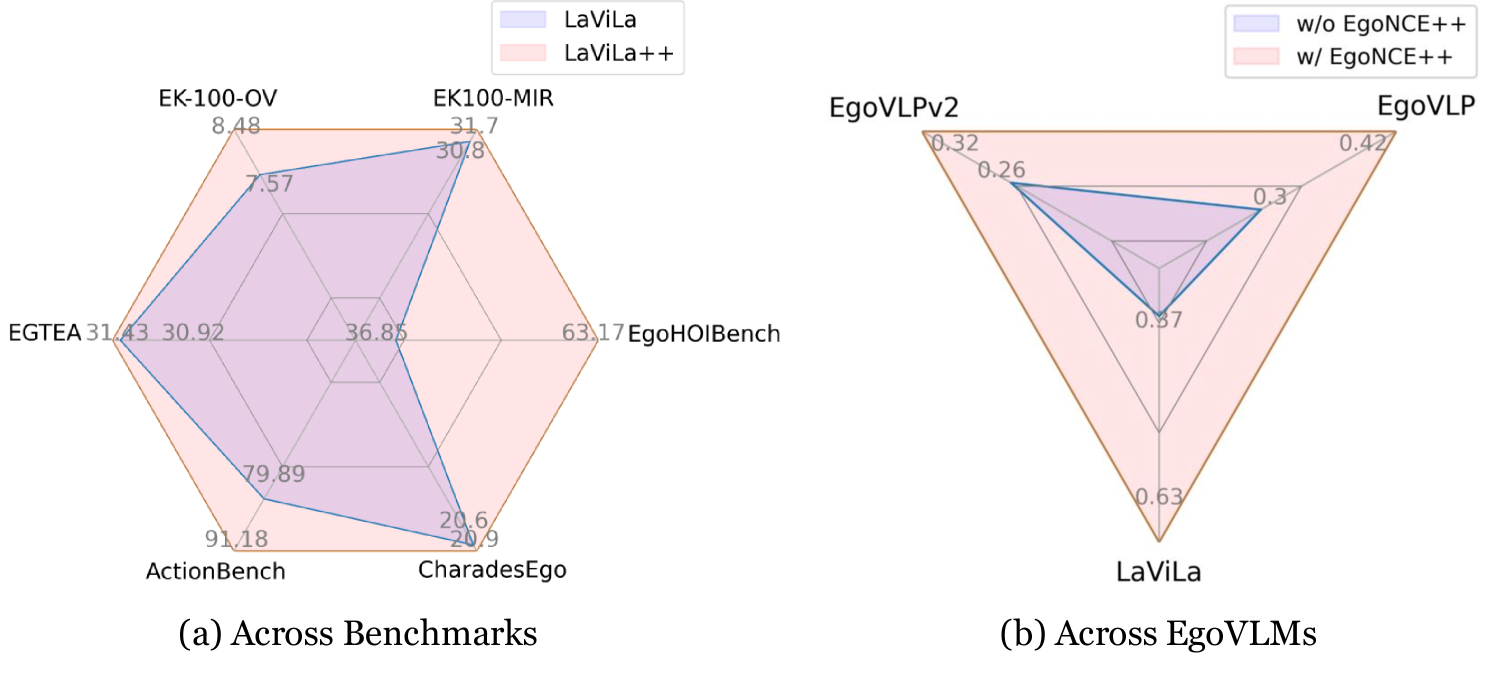
EgoNCE++: Do Egocentric Video-Language Models Really Understand Hand-Object Interactions?
Boshen Xu, Ziheng Wang, Yang Du, Zhinan Song, Sipeng Zheng, Qin Jin
0
0
Egocentric video-language pretraining is a crucial paradigm to advance the learning of egocentric hand-object interactions (EgoHOI). Despite the great success on existing testbeds, these benchmarks focus more on closed-set visual concepts or limited scenarios. Due to the occurrence of diverse EgoHOIs in the real world, we propose an open-vocabulary benchmark named EgoHOIBench to reveal the diminished performance of current egocentric video-language models (EgoVLM) on fined-grained concepts, indicating that these models still lack a full spectrum of egocentric understanding. We attribute this performance gap to insufficient fine-grained supervision and strong bias towards understanding objects rather than temporal dynamics in current methods. To tackle these issues, we introduce a novel asymmetric contrastive objective for EgoHOI named EgoNCE++. For video-to-text loss, we enhance text supervision through the generation of negative captions by leveraging the in-context learning of large language models to perform HOI-related word substitution. For text-to-video loss, we propose an object-centric positive video sampling strategy that aggregates video representations by the same nouns. Our extensive experiments demonstrate that EgoNCE++ significantly boosts open-vocabulary HOI recognition, multi-instance retrieval, and action recognition tasks across various egocentric models, with improvements of up to +26.55%. Our code is available at https://github.com/xuboshen/EgoNCEpp.
6/4/2024

AlanaVLM: A Multimodal Embodied AI Foundation Model for Egocentric Video Understanding
Alessandro Suglia, Claudio Greco, Katie Baker, Jose L. Part, Ioannis Papaioannou, Arash Eshghi, Ioannis Konstas, Oliver Lemon
0
0
AI personal assistants deployed via robots or wearables require embodied understanding to collaborate with humans effectively. However, current Vision-Language Models (VLMs) primarily focus on third-person view videos, neglecting the richness of egocentric perceptual experience. To address this gap, we propose three key contributions. First, we introduce the Egocentric Video Understanding Dataset (EVUD) for training VLMs on video captioning and question answering tasks specific to egocentric videos. Second, we present AlanaVLM, a 7B parameter VLM trained using parameter-efficient methods on EVUD. Finally, we evaluate AlanaVLM's capabilities on OpenEQA, a challenging benchmark for embodied video question answering. Our model achieves state-of-the-art performance, outperforming open-source models including strong Socratic models using GPT-4 as a planner by 3.6%. Additionally, we outperform Claude 3 and Gemini Pro Vision 1.0 and showcase competitive results compared to Gemini Pro 1.5 and GPT-4V, even surpassing the latter in spatial reasoning. This research paves the way for building efficient VLMs that can be deployed in robots or wearables, leveraging embodied video understanding to collaborate seamlessly with humans in everyday tasks, contributing to the next generation of Embodied AI.
6/24/2024
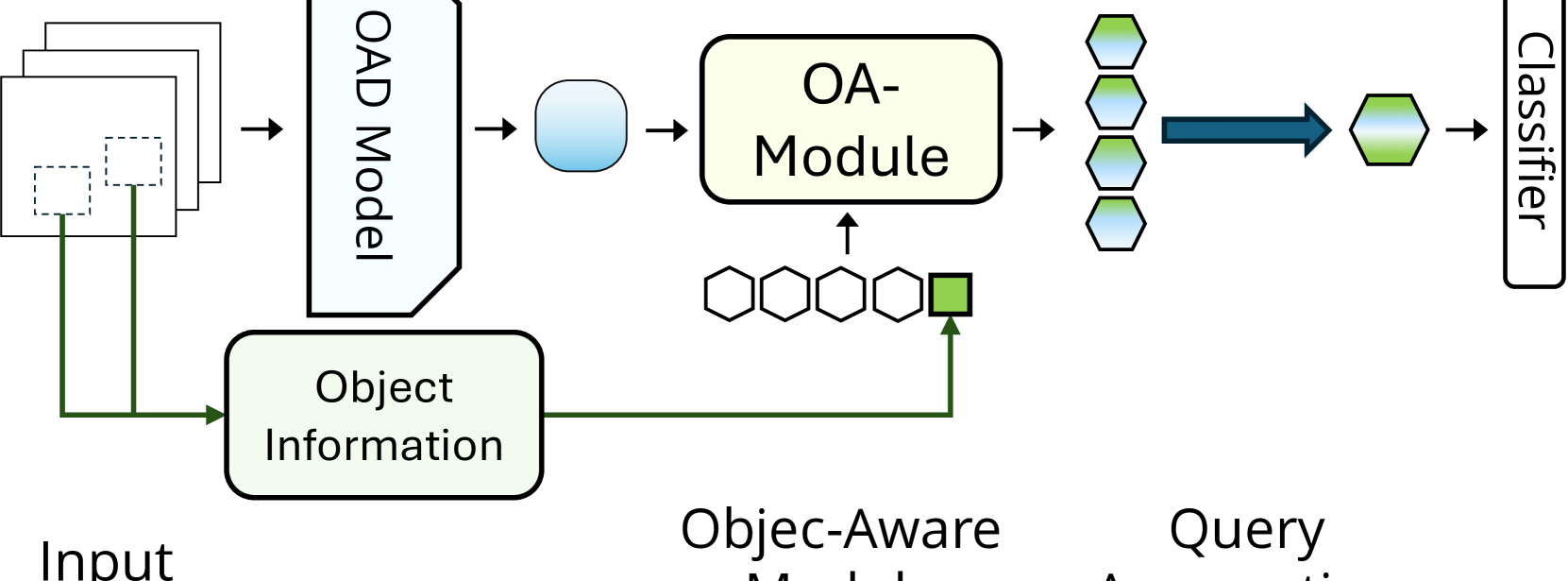
Object Aware Egocentric Online Action Detection
Joungbin An, Yunsu Park, Hyolim Kang, Seon Joo Kim
0
0
Advancements in egocentric video datasets like Ego4D, EPIC-Kitchens, and Ego-Exo4D have enriched the study of first-person human interactions, which is crucial for applications in augmented reality and assisted living. Despite these advancements, current Online Action Detection methods, which efficiently detect actions in streaming videos, are predominantly designed for exocentric views and thus fail to capitalize on the unique perspectives inherent to egocentric videos. To address this gap, we introduce an Object-Aware Module that integrates egocentric-specific priors into existing OAD frameworks, enhancing first-person footage interpretation. Utilizing object-specific details and temporal dynamics, our module improves scene understanding in detecting actions. Validated extensively on the Epic-Kitchens 100 dataset, our work can be seamlessly integrated into existing models with minimal overhead and bring consistent performance enhancements, marking an important step forward in adapting action detection systems to egocentric video analysis.
6/4/2024