EIT: Enhanced Interactive Transformer
2212.10197
0
0
🤿
Abstract
Two principles: the complementary principle and the consensus principle are widely acknowledged in the literature of multi-view learning. However, the current design of multi-head self-attention, an instance of multi-view learning, prioritizes the complementarity while ignoring the consensus. To address this problem, we propose an enhanced multi-head self-attention (EMHA). First, to satisfy the complementary principle, EMHA removes the one-to-one mapping constraint among queries and keys in multiple subspaces and allows each query to attend to multiple keys. On top of that, we develop a method to fully encourage consensus among heads by introducing two interaction models, namely inner-subspace interaction and cross-subspace interaction. Extensive experiments on a wide range of language tasks (e.g., machine translation, abstractive summarization and grammar correction, language modeling), show its superiority, with a very modest increase in model size. Our code would be available at: https://github.com/zhengkid/EIT-Enhanced-Interactive-Transformer.
Create account to get full access
Overview
- The paper discusses two key principles in multi-view learning: the complementary principle and the consensus principle.
- It argues that the current design of multi-head self-attention, a type of multi-view learning, prioritizes the complementarity while ignoring the consensus.
- To address this issue, the paper proposes an Enhanced Multi-head Self-Attention (EMHA) mechanism that satisfies both principles.
Plain English Explanation
The paper focuses on improving a common machine learning technique called multi-head self-attention, which is used in many powerful language models like Transformers. Multi-head self-attention allows a model to look at a piece of text from multiple "perspectives" or "views" to better understand it.
The key ideas behind multi-view learning are the complementary principle and the consensus principle. The complementary principle says that each view should provide different, complementary information. The consensus principle says that the different views should also agree on the overall meaning.
The current design of multi-head self-attention emphasizes the complementarity between the different views, but doesn't do enough to ensure they reach a consensus. The paper's proposed EMHA mechanism tries to fix this by:
- Allowing each "view" (attention head) to attend to multiple parts of the input, rather than just one. This satisfies the complementary principle.
- Introducing new techniques to encourage the different views to interact and reach a consensus on the overall meaning. This satisfies the consensus principle.
By doing this, the EMHA mechanism can capture both the complementary and consensual aspects of multi-view learning, leading to improved performance on a variety of language tasks like translation, summarization, and grammar correction.
Technical Explanation
The paper's key contribution is the Enhanced Multi-head Self-Attention (EMHA) mechanism, which builds on the standard multi-head self-attention used in Transformer-based models.
In standard multi-head self-attention, each "head" or attention subspace has a one-to-one mapping between queries and keys. EMHA removes this constraint, allowing each query to attend to multiple keys across the different subspaces. This satisfies the complementary principle by enabling each head to capture different information.
To also satisfy the consensus principle, EMHA introduces two new interaction models:
- Inner-subspace interaction: This encourages the different attention heads within the same subspace to reach a consensus.
- Cross-subspace interaction: This encourages the different attention subspaces to exchange information and align their outputs.
These interaction models help ensure that the different attention heads converge to a shared understanding of the input, rather than just providing complementary but disconnected views.
The paper evaluates EMHA on a range of language tasks, including machine translation, abstractive summarization, grammar correction, and language modeling. EMHA consistently outperforms the standard multi-head attention, with only a modest increase in model size.
Critical Analysis
The paper makes a compelling case for the importance of satisfying both the complementary and consensus principles in multi-view learning. The proposed EMHA mechanism represents a thoughtful attempt to address the limitations of standard multi-head attention in this regard.
That said, the paper does not provide a deep analysis of the specific circumstances or task characteristics where EMHA is likely to shine compared to other attention mechanisms. For example, it would be interesting to understand if EMHA is particularly beneficial for tasks that require a more holistic, integrated understanding of the input, versus those that can be solved by aggregating complementary, specialized views.
Additionally, the paper does not explore the potential downsides or trade-offs of the EMHA approach. For instance, the added complexity of the inter-head and inter-subspace interactions could impact inference speed or memory usage, which may be important considerations for certain applications, such as real-time semantic communications or efficient image deblurring.
Overall, the paper makes a valuable contribution by highlighting the importance of balancing complementarity and consensus in multi-view learning, and proposing a concrete mechanism to achieve this. Further research exploring the specific strengths and limitations of EMHA could help refine our understanding of when and how to best apply this approach.
Conclusion
The paper introduces an Enhanced Multi-head Self-Attention (EMHA) mechanism that addresses the shortcomings of standard multi-head attention in satisfying both the complementary and consensus principles of multi-view learning. By allowing each attention head to attend to multiple keys and introducing new interaction models to align the different heads, EMHA is able to capture both the complementary and consensual aspects of multi-view learning, leading to improved performance on a variety of language tasks.
This work represents an important step forward in designing more sophisticated attention mechanisms that can better leverage the strengths of multi-view learning. As cross-lingual and cross-modal applications become more prevalent, techniques like EMHA that can extract coherent, consensus-driven representations from diverse information sources will likely grow in importance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Embedded Heterogeneous Attention Transformer for Cross-lingual Image Captioning
Zijie Song, Zhenzhen Hu, Yuanen Zhou, Ye Zhao, Richang Hong, Meng Wang
0
0
Cross-lingual image captioning is a challenging task that requires addressing both cross-lingual and cross-modal obstacles in multimedia analysis. The crucial issue in this task is to model the global and the local matching between the image and different languages. Existing cross-modal embedding methods based on the transformer architecture oversee the local matching between the image region and monolingual words, especially when dealing with diverse languages. To overcome these limitations, we propose an Embedded Heterogeneous Attention Transformer (EHAT) to establish cross-domain relationships and local correspondences between images and different languages by using a heterogeneous network. EHAT comprises Masked Heterogeneous Cross-attention (MHCA), Heterogeneous Attention Reasoning Network (HARN), and Heterogeneous Co-attention (HCA). The HARN serves as the core network and it captures cross-domain relationships by leveraging visual bounding box representation features to connect word features from two languages and to learn heterogeneous maps. MHCA and HCA facilitate cross-domain integration in the encoder through specialized heterogeneous attention mechanisms, enabling a single model to generate captions in two languages. We evaluate our approach on the MSCOCO dataset to generate captions in English and Chinese, two languages that exhibit significant differences in their language families. The experimental results demonstrate the superior performance of our method compared to existing advanced monolingual methods. Our proposed EHAT framework effectively addresses the challenges of cross-lingual image captioning, paving the way for improved multilingual image analysis and understanding.
4/8/2024
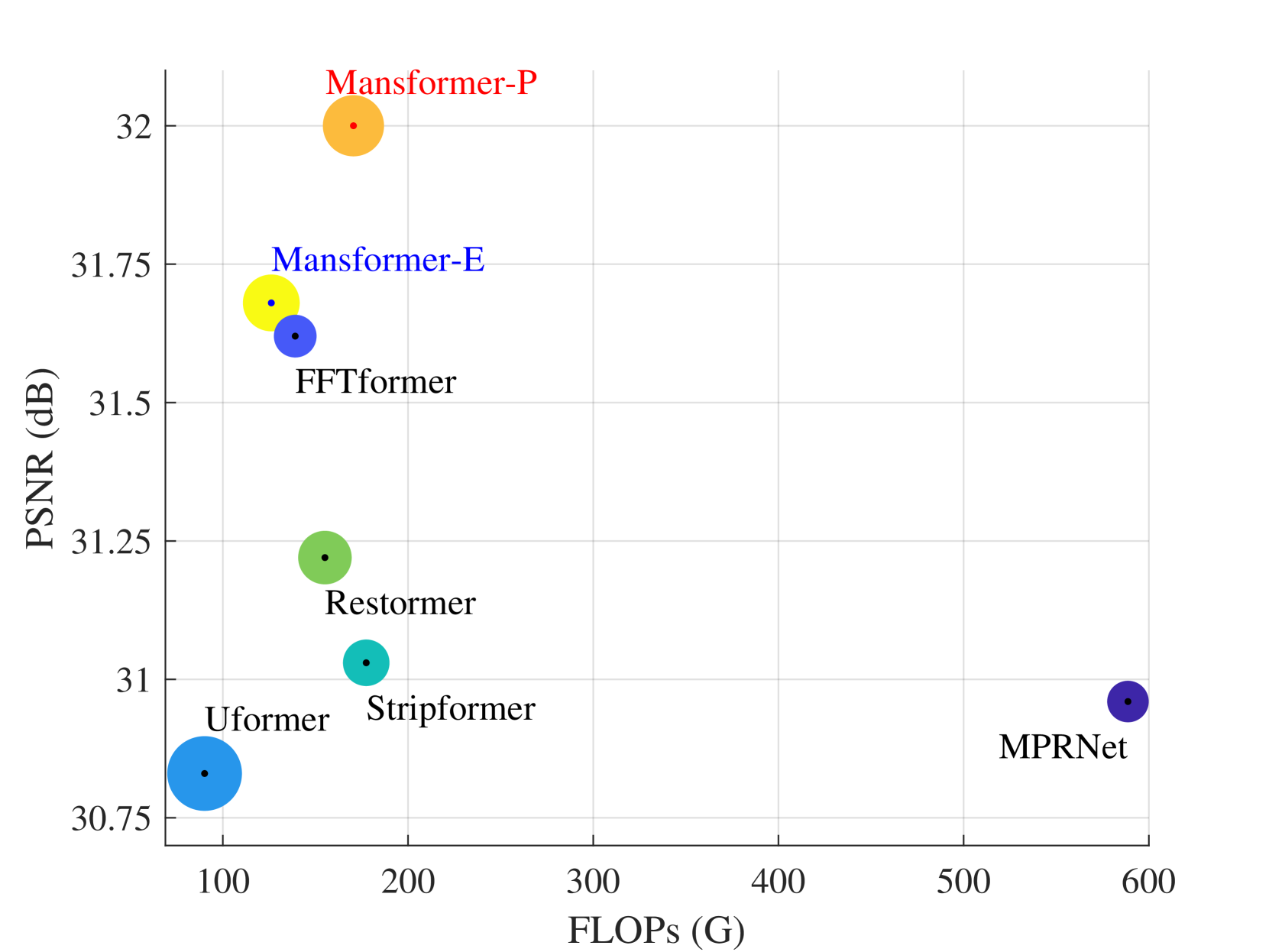
Mansformer: Efficient Transformer of Mixed Attention for Image Deblurring and Beyond
Pin-Hung Kuo, Jinshan Pan, Shao-Yi Chien, Ming-Hsuan Yang
0
0
Transformer has made an enormous success in natural language processing and high-level vision over the past few years. However, the complexity of self-attention is quadratic to the image size, which makes it infeasible for high-resolution vision tasks. In this paper, we propose the Mansformer, a Transformer of mixed attention that combines multiple self-attentions, gate, and multi-layer perceptions (MLPs), to explore and employ more possibilities of self-attention. Taking efficiency into account, we design four kinds of self-attention, whose complexities are all linear. By elaborate adjustment of the tensor shapes and dimensions for the dot product, we split the typical self-attention of quadratic complexity into four operations of linear complexity. To adaptively merge these different kinds of self-attention, we take advantage of an architecture similar to Squeeze-and-Excitation Networks. Furthermore, we make it to merge the two-staged Transformer design into one stage by the proposed gated-dconv MLP. Image deblurring is our main target, while extensive quantitative and qualitative evaluations show that this method performs favorably against the state-of-the-art methods far more than simply deblurring. The source codes and trained models will be made available to the public.
4/10/2024

Symmetric Dot-Product Attention for Efficient Training of BERT Language Models
Martin Courtois, Malte Ostendorff, Leonhard Hennig, Georg Rehm
0
0
Initially introduced as a machine translation model, the Transformer architecture has now become the foundation for modern deep learning architecture, with applications in a wide range of fields, from computer vision to natural language processing. Nowadays, to tackle increasingly more complex tasks, Transformer-based models are stretched to enormous sizes, requiring increasingly larger training datasets, and unsustainable amount of compute resources. The ubiquitous nature of the Transformer and its core component, the attention mechanism, are thus prime targets for efficiency research. In this work, we propose an alternative compatibility function for the self-attention mechanism introduced by the Transformer architecture. This compatibility function exploits an overlap in the learned representation of the traditional scaled dot-product attention, leading to a symmetric with pairwise coefficient dot-product attention. When applied to the pre-training of BERT-like models, this new symmetric attention mechanism reaches a score of 79.36 on the GLUE benchmark against 78.74 for the traditional implementation, leads to a reduction of 6% in the number of trainable parameters, and reduces the number of training steps required before convergence by half.
6/21/2024
👨🏫
Transformer-Aided Semantic Communications
Matin Mortaheb, Erciyes Karakaya, Mohammad A. Amir Khojastepour, Sennur Ulukus
0
0
The transformer structure employed in large language models (LLMs), as a specialized category of deep neural networks (DNNs) featuring attention mechanisms, stands out for their ability to identify and highlight the most relevant aspects of input data. Such a capability is particularly beneficial in addressing a variety of communication challenges, notably in the realm of semantic communication where proper encoding of the relevant data is critical especially in systems with limited bandwidth. In this work, we employ vision transformers specifically for the purpose of compression and compact representation of the input image, with the goal of preserving semantic information throughout the transmission process. Through the use of the attention mechanism inherent in transformers, we create an attention mask. This mask effectively prioritizes critical segments of images for transmission, ensuring that the reconstruction phase focuses on key objects highlighted by the mask. Our methodology significantly improves the quality of semantic communication and optimizes bandwidth usage by encoding different parts of the data in accordance with their semantic information content, thus enhancing overall efficiency. We evaluate the effectiveness of our proposed framework using the TinyImageNet dataset, focusing on both reconstruction quality and accuracy. Our evaluation results demonstrate that our framework successfully preserves semantic information, even when only a fraction of the encoded data is transmitted, according to the intended compression rates.
5/3/2024