Embedded Heterogeneous Attention Transformer for Cross-lingual Image Captioning
2307.09915
0
0
🖼️
Abstract
Cross-lingual image captioning is a challenging task that requires addressing both cross-lingual and cross-modal obstacles in multimedia analysis. The crucial issue in this task is to model the global and the local matching between the image and different languages. Existing cross-modal embedding methods based on the transformer architecture oversee the local matching between the image region and monolingual words, especially when dealing with diverse languages. To overcome these limitations, we propose an Embedded Heterogeneous Attention Transformer (EHAT) to establish cross-domain relationships and local correspondences between images and different languages by using a heterogeneous network. EHAT comprises Masked Heterogeneous Cross-attention (MHCA), Heterogeneous Attention Reasoning Network (HARN), and Heterogeneous Co-attention (HCA). The HARN serves as the core network and it captures cross-domain relationships by leveraging visual bounding box representation features to connect word features from two languages and to learn heterogeneous maps. MHCA and HCA facilitate cross-domain integration in the encoder through specialized heterogeneous attention mechanisms, enabling a single model to generate captions in two languages. We evaluate our approach on the MSCOCO dataset to generate captions in English and Chinese, two languages that exhibit significant differences in their language families. The experimental results demonstrate the superior performance of our method compared to existing advanced monolingual methods. Our proposed EHAT framework effectively addresses the challenges of cross-lingual image captioning, paving the way for improved multilingual image analysis and understanding.
Create account to get full access
Overview
- Cross-lingual image captioning is a complex task that requires addressing challenges in translating between languages and connecting visual and textual information.
- Existing methods using transformer-based cross-modal embeddings often overlook the local associations between image regions and individual words, especially across diverse languages.
- To address these limitations, the researchers propose the Embedded Heterogeneous Attention Transformer (EHAT) framework, which uses specialized attention mechanisms to better capture cross-domain relationships and local correspondences between images and different languages.
Plain English Explanation
The paper tackles the challenge of cross-lingual image captioning, which involves generating captions for images in multiple languages. This is a difficult task because it requires bridging the gap between visual information and language, as well as translating between different languages.
Existing methods based on transformer architectures have struggled to capture the local-level connections between image regions and individual words, especially when dealing with languages that are very different, like English and Chinese.
To overcome these issues, the researchers developed the EHAT framework. EHAT uses specialized attention mechanisms, including Masked Heterogeneous Cross-attention (MHCA), Heterogeneous Attention Reasoning Network (HARN), and Heterogeneous Co-attention (HCA). These components help the model better understand the relationships between visual and textual information across language boundaries, enabling it to generate high-quality captions in multiple languages from a single model.
Technical Explanation
The key elements of the EHAT framework are:
-
Masked Heterogeneous Cross-attention (MHCA): This attention mechanism facilitates cross-domain integration in the encoder by using specialized heterogeneous attention to connect image regions and words from different languages.
-
Heterogeneous Attention Reasoning Network (HARN): The core of the EHAT model, HARN captures cross-domain relationships by leveraging visual bounding box features to link word features from two languages and learn heterogeneous mappings.
-
Heterogeneous Co-attention (HCA): Similar to MHCA, HCA uses a specialized attention mechanism to enable the model to jointly attend to image regions and words from different languages.
The researchers evaluate their approach on the MSCOCO dataset, generating captions in both English and Chinese. The experimental results demonstrate that EHAT outperforms existing advanced monolingual captioning methods, showcasing the effectiveness of the model in addressing the challenges of cross-lingual image captioning.
Critical Analysis
The paper provides a comprehensive solution to the cross-lingual image captioning task, addressing the key limitations of existing transformer-based approaches. However, the researchers do not discuss some potential caveats or areas for further research:
- The performance of the model on language pairs with even greater differences, such as those from different language families, is not explored. Further testing on a wider range of language combinations would be valuable.
- The computational complexity and inference time of the EHAT framework are not reported. As the model uses several specialized attention mechanisms, the efficiency of the approach should be considered, especially for real-world applications.
- The paper does not address the issue of dataset bias in cross-lingual image captioning, which could limit the model's generalization to more diverse visual and linguistic contexts.
Overall, the EHAT framework represents a significant advancement in cross-lingual image captioning, but further research is needed to fully understand its limitations and potential for real-world deployment.
Conclusion
The paper presents the Embedded Heterogeneous Attention Transformer (EHAT) framework, a novel approach to the challenge of cross-lingual image captioning. By using specialized attention mechanisms to better capture cross-domain relationships and local correspondences between images and different languages, EHAT outperforms existing advanced monolingual captioning methods.
The successful development of EHAT demonstrates the potential for improving multilingual image analysis and understanding, which has important implications for a wide range of applications, from AI-powered translation services to assistive technologies for users with diverse language backgrounds. As the field of cross-modal and cross-lingual AI continues to evolve, the insights and techniques presented in this paper will likely inform future research and contribute to the ongoing progress in this exciting area of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Temporal Cross-Attention for Dynamic Embedding and Tokenization of Multimodal Electronic Health Records
Yingbo Ma, Suraj Kolla, Dhruv Kaliraman, Victoria Nolan, Zhenhong Hu, Ziyuan Guan, Yuanfang Ren, Brooke Armfield, Tezcan Ozrazgat-Baslanti, Tyler J. Loftus, Parisa Rashidi, Azra Bihorac, Benjamin Shickel
0
0
The breadth, scale, and temporal granularity of modern electronic health records (EHR) systems offers great potential for estimating personalized and contextual patient health trajectories using sequential deep learning. However, learning useful representations of EHR data is challenging due to its high dimensionality, sparsity, multimodality, irregular and variable-specific recording frequency, and timestamp duplication when multiple measurements are recorded simultaneously. Although recent efforts to fuse structured EHR and unstructured clinical notes suggest the potential for more accurate prediction of clinical outcomes, less focus has been placed on EHR embedding approaches that directly address temporal EHR challenges by learning time-aware representations from multimodal patient time series. In this paper, we introduce a dynamic embedding and tokenization framework for precise representation of multimodal clinical time series that combines novel methods for encoding time and sequential position with temporal cross-attention. Our embedding and tokenization framework, when integrated into a multitask transformer classifier with sliding window attention, outperformed baseline approaches on the exemplar task of predicting the occurrence of nine postoperative complications of more than 120,000 major inpatient surgeries using multimodal data from three hospitals and two academic health centers in the United States.
4/3/2024
🤿
EIT: Enhanced Interactive Transformer
Tong Zheng, Bei Li, Huiwen Bao, Tong Xiao, Jingbo Zhu
0
0
Two principles: the complementary principle and the consensus principle are widely acknowledged in the literature of multi-view learning. However, the current design of multi-head self-attention, an instance of multi-view learning, prioritizes the complementarity while ignoring the consensus. To address this problem, we propose an enhanced multi-head self-attention (EMHA). First, to satisfy the complementary principle, EMHA removes the one-to-one mapping constraint among queries and keys in multiple subspaces and allows each query to attend to multiple keys. On top of that, we develop a method to fully encourage consensus among heads by introducing two interaction models, namely inner-subspace interaction and cross-subspace interaction. Extensive experiments on a wide range of language tasks (e.g., machine translation, abstractive summarization and grammar correction, language modeling), show its superiority, with a very modest increase in model size. Our code would be available at: https://github.com/zhengkid/EIT-Enhanced-Interactive-Transformer.
6/6/2024

Hyperbolic Heterogeneous Graph Attention Networks
Jongmin Park, Seunghoon Han, Soohwan Jeong, Sungsu Lim
0
0
Most previous heterogeneous graph embedding models represent elements in a heterogeneous graph as vector representations in a low-dimensional Euclidean space. However, because heterogeneous graphs inherently possess complex structures, such as hierarchical or power-law structures, distortions can occur when representing them in Euclidean space. To overcome this limitation, we propose Hyperbolic Heterogeneous Graph Attention Networks (HHGAT) that learn vector representations in hyperbolic spaces with meta-path instances. We conducted experiments on three real-world heterogeneous graph datasets, demonstrating that HHGAT outperforms state-of-the-art heterogeneous graph embedding models in node classification and clustering tasks.
4/16/2024
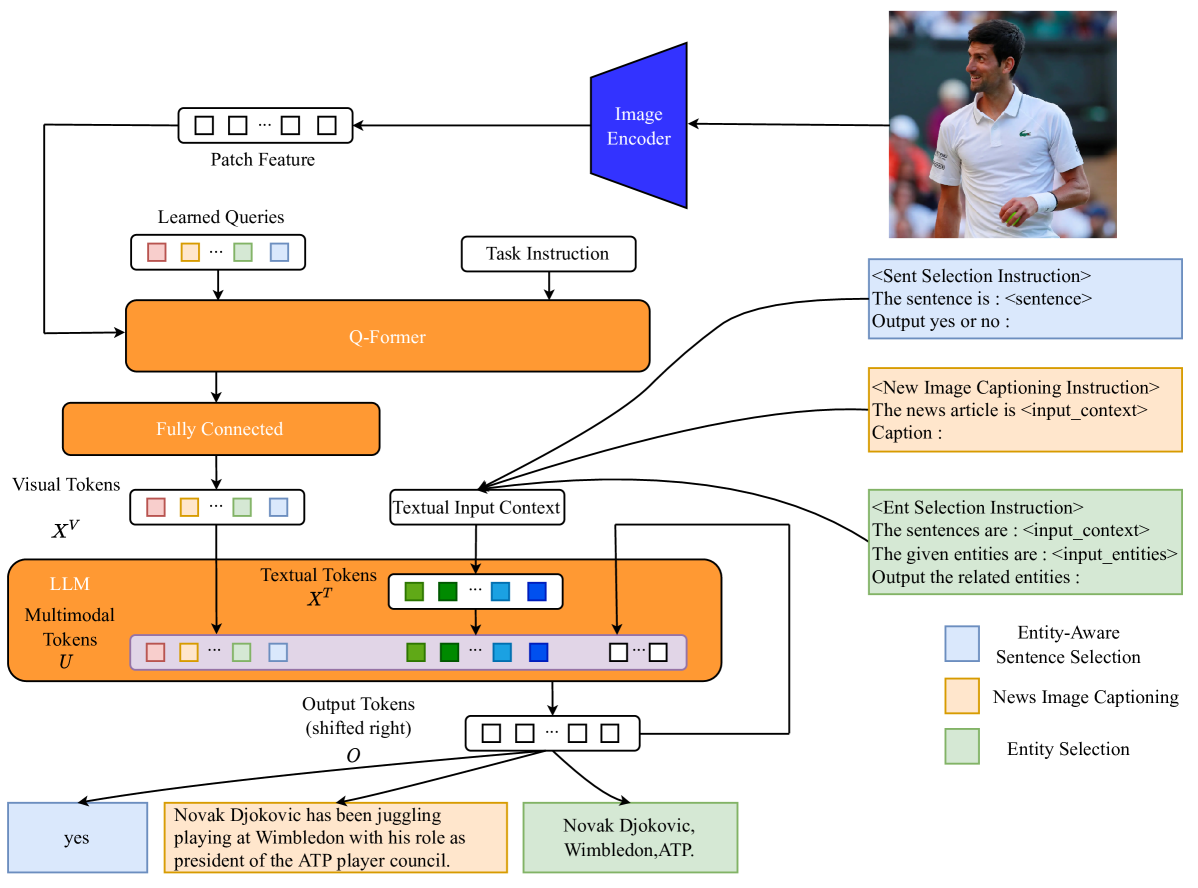
EAMA : Entity-Aware Multimodal Alignment Based Approach for News Image Captioning
Junzhe Zhang, Huixuan Zhang, Xunjian Yin, Xiaojun Wan
0
0
News image captioning requires model to generate an informative caption rich in entities, with the news image and the associated news article. Though Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in addressing various vision-language tasks, our research finds that current MLLMs still bear limitations in handling entity information on news image captioning task. Besides, while MLLMs have the ability to process long inputs, generating high-quality news image captions still requires a trade-off between sufficiency and conciseness of textual input information. To explore the potential of MLLMs and address problems we discovered, we propose : an Entity-Aware Multimodal Alignment based approach for news image captioning. Our approach first aligns the MLLM through Balance Training Strategy with two extra alignment tasks: Entity-Aware Sentence Selection task and Entity Selection task, together with News Image Captioning task, to enhance its capability in handling multimodal entity information. The aligned MLLM will utilizes the additional entity-related information it explicitly extracts to supplement its textual input while generating news image captions. Our approach achieves better results than all previous models in CIDEr score on GoodNews dataset (72.33 -> 88.39) and NYTimes800k dataset (70.83 -> 85.61).
5/7/2024