ElicitationGPT: Text Elicitation Mechanisms via Language Models

0
💬
Sign in to get full access
Overview
- This paper explores methods for eliciting informative text evaluations from large language models (LLMs).
- The authors propose single-dimensional and multi-dimensional scoring rules as effective techniques for getting LLMs to provide more detailed and nuanced feedback on text outputs.
- Key ideas include using scoring rules to incentivize LLMs to give more thoughtful and comprehensive evaluations, as well as introducing multi-dimensional scoring to capture different aspects of text quality.
Plain English Explanation
The paper looks at ways to get large language models (LLMs) like GPT to provide more useful and insightful feedback on text outputs. One approach the authors explore is using "scoring rules" - essentially a set of guidelines or incentives to encourage the LLMs to give more detailed and nuanced evaluations.
The idea is that by structuring the evaluation process in a certain way, you can nudge the LLM to consider different dimensions of text quality, rather than just giving a simple overall score. For example, a multi-dimensional scoring rule might ask the model to rate the text on factors like clarity, creativity, and factual accuracy separately.
This can lead to more informative and actionable feedback compared to a single numeric score. It's like asking a human reviewer to not just give a grade, but to also explain what they liked, didn't like, and how the text could be improved.
The researchers tested these scoring rule techniques across a variety of text generation tasks, like summarizing Wikipedia articles and matching patients to clinical trials. They found that the more structured evaluation approaches did indeed elicit richer and more nuanced feedback from the LLMs.
Technical Explanation
The paper introduces two main techniques for eliciting informative text evaluations from large language models (LLMs):
-
Single-dimensional Scoring Rules: These involve defining a specific evaluation metric or scale, and asking the LLM to provide a numeric score according to that criteria. For example, rating the "clarity" of a text passage on a scale of 1-5.
-
Multi-dimensional Scoring Rules: Here, the LLM is asked to evaluate the text along multiple distinct dimensions, like clarity, creativity, and factual accuracy. The model provides a separate score for each dimension.
The key insight is that these structured scoring approaches incentivize the LLM to engage more deeply with the text and consider different aspects of quality, rather than just giving a simple overall impression.
The authors evaluated these techniques across a range of text generation tasks, including:
- Summarizing Wikipedia articles
- Matching patients to clinical trials
- Knowledge-grounded text generation
Their experiments showed that the scoring rule approaches consistently led to more detailed and informative evaluations from the LLMs, compared to just asking for an unstructured free-text critique.
Critical Analysis
The paper makes a compelling case for using structured scoring rules to elicit richer feedback from large language models. However, a few potential limitations are worth considering:
-
The scoring rules themselves require careful design to ensure they capture the most relevant dimensions of text quality. Poorly chosen criteria could lead to evaluations that miss key aspects.
-
There may be a trade-off between the increased informativeness of the multi-dimensional scores and the additional cognitive load placed on the LLM. Striking the right balance is an area for further research.
-
The experiments were conducted on specific text generation tasks. Broader real-world deployment may uncover additional challenges or edge cases not covered in the study.
-
While the scoring rule approach seems promising, it's unclear how it would scale to extremely large or open-ended text corpora. Managing the evaluation process could become unwieldy.
Overall, the techniques proposed in this paper represent an important step forward in getting LLMs to provide more useful and actionable feedback. But there is still work to be done to fully realize the potential of these methods in practice.
Conclusion
This paper introduces novel techniques for eliciting more informative text evaluations from large language models. By using structured single-dimensional and multi-dimensional scoring rules, the authors show that LLMs can be incentivized to provide richer and more nuanced feedback on text outputs.
These approaches have promising applications in areas like text summarization, clinical trial matching, and knowledge-grounded generation. They could help unlock the full potential of LLMs as powerful text evaluation tools, rather than just text generation.
While the proposed methods show strong initial results, further research is needed to address potential scalability challenges and ensure the scoring rules capture the most relevant dimensions of text quality. But overall, this paper represents an important advance in the quest to build more insightful and useful language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
ElicitationGPT: Text Elicitation Mechanisms via Language Models
Yifan Wu, Jason Hartline
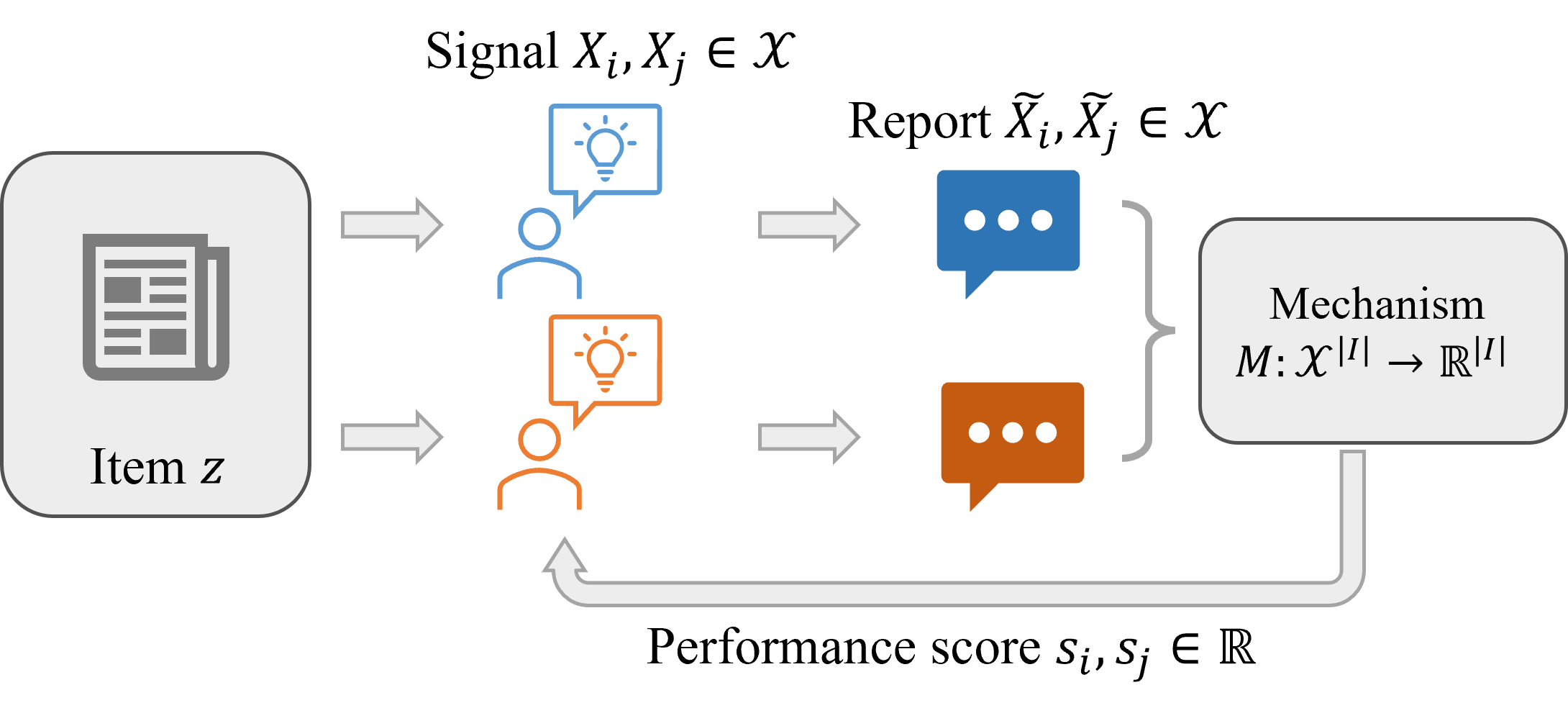
Scoring rules evaluate probabilistic forecasts of an unknown state against the realized state and are a fundamental building block in the incentivized elicitation of information and the training of machine learning models. This paper develops mechanisms for scoring elicited text against ground truth text using domain-knowledge-free queries to a large language model (specifically ChatGPT) and empirically evaluates their alignment with human preferences. The empirical evaluation is conducted on peer reviews from a peer-grading dataset and in comparison to manual instructor scores for the peer reviews.
Read more6/21/2024
0
Eliciting Informative Text Evaluations with Large Language Models
Yuxuan Lu, Shengwei Xu, Yichi Zhang, Yuqing Kong, Grant Schoenebeck
Peer prediction mechanisms motivate high-quality feedback with provable guarantees. However, current methods only apply to rather simple reports, like multiple-choice or scalar numbers. We aim to broaden these techniques to the larger domain of text-based reports, drawing on the recent developments in large language models. This vastly increases the applicability of peer prediction mechanisms as textual feedback is the norm in a large variety of feedback channels: peer reviews, e-commerce customer reviews, and comments on social media. We introduce two mechanisms, the Generative Peer Prediction Mechanism (GPPM) and the Generative Synopsis Peer Prediction Mechanism (GSPPM). These mechanisms utilize LLMs as predictors, mapping from one agent's report to a prediction of her peer's report. Theoretically, we show that when the LLM prediction is sufficiently accurate, our mechanisms can incentivize high effort and truth-telling as an (approximate) Bayesian Nash equilibrium. Empirically, we confirm the efficacy of our mechanisms through experiments conducted on two real datasets: the Yelp review dataset and the ICLR OpenReview dataset. We highlight the results that on the ICLR dataset, our mechanisms can differentiate three quality levels -- human-written reviews, GPT-4-generated reviews, and GPT-3.5-generated reviews in terms of expected scores. Additionally, GSPPM penalizes LLM-generated reviews more effectively than GPPM.
Read more9/4/2024
💬
0
From Text to Insight: Leveraging Large Language Models for Performance Evaluation in Management
Ning Li, Huaikang Zhou, Mingze Xu
This study explores the potential of Large Language Models (LLMs), specifically GPT-4, to enhance objectivity in organizational task performance evaluations. Through comparative analyses across two studies, including various task performance outputs, we demonstrate that LLMs can serve as a reliable and even superior alternative to human raters in evaluating knowledge-based performance outputs, which are a key contribution of knowledge workers. Our results suggest that GPT ratings are comparable to human ratings but exhibit higher consistency and reliability. Additionally, combined multiple GPT ratings on the same performance output show strong correlations with aggregated human performance ratings, akin to the consensus principle observed in performance evaluation literature. However, we also find that LLMs are prone to contextual biases, such as the halo effect, mirroring human evaluative biases. Our research suggests that while LLMs are capable of extracting meaningful constructs from text-based data, their scope is currently limited to specific forms of performance evaluation. By highlighting both the potential and limitations of LLMs, our study contributes to the discourse on AI role in management studies and sets a foundation for future research to refine AI theoretical and practical applications in management.
Read more8/13/2024
🎲
0
Using ChatGPT to Score Essays and Short-Form Constructed Responses
Mark D. Shermis
This study aimed to determine if ChatGPT's large language models could match the scoring accuracy of human and machine scores from the ASAP competition. The investigation focused on various prediction models, including linear regression, random forest, gradient boost, and boost. ChatGPT's performance was evaluated against human raters using quadratic weighted kappa (QWK) metrics. Results indicated that while ChatGPT's gradient boost model achieved QWKs close to human raters for some data sets, its overall performance was inconsistent and often lower than human scores. The study highlighted the need for further refinement, particularly in handling biases and ensuring scoring fairness. Despite these challenges, ChatGPT demonstrated potential for scoring efficiency, especially with domain-specific fine-tuning. The study concludes that ChatGPT can complement human scoring but requires additional development to be reliable for high-stakes assessments. Future research should improve model accuracy, address ethical considerations, and explore hybrid models combining ChatGPT with empirical methods.
Read more8/20/2024