Eliciting Informative Text Evaluations with Large Language Models
2405.15077
0
0
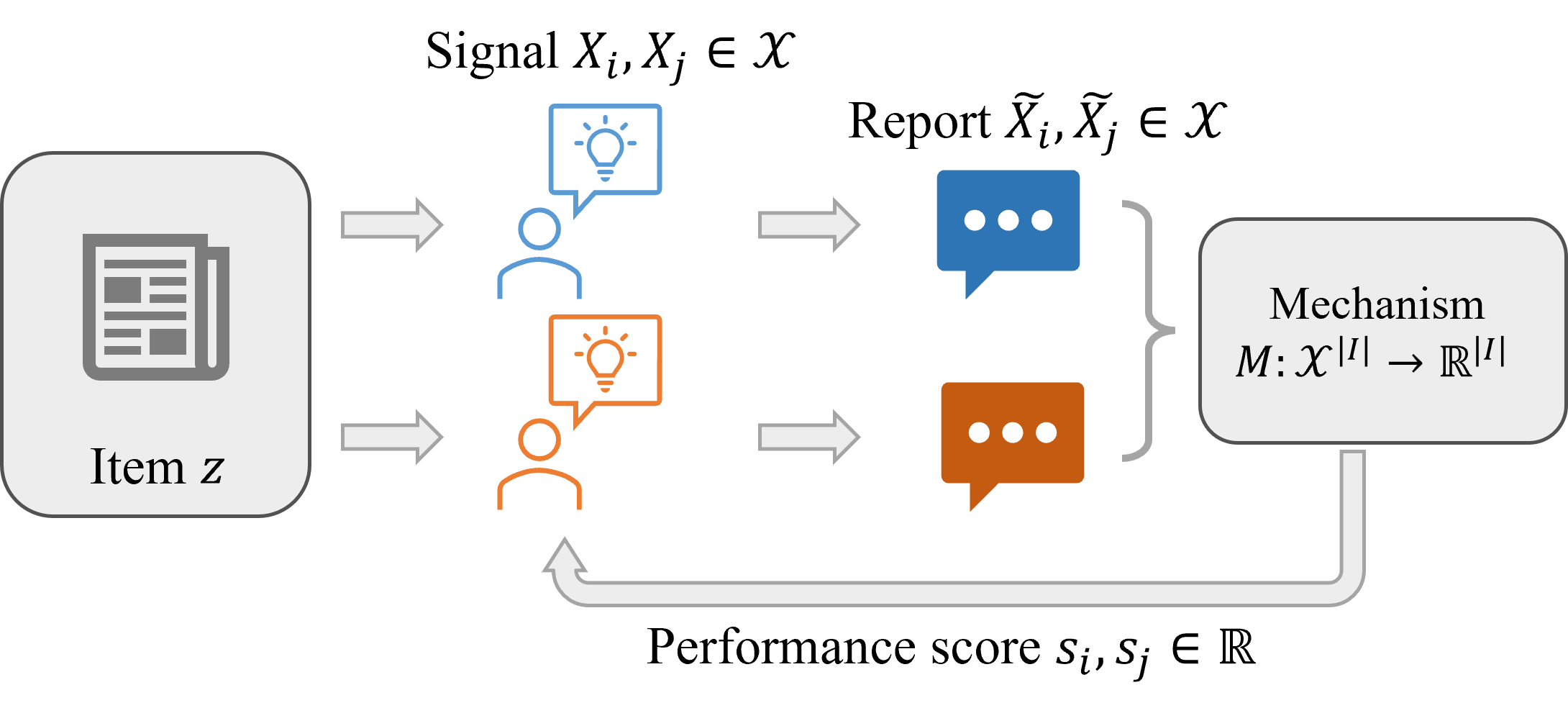
Abstract
Peer prediction mechanisms motivate high-quality feedback with provable guarantees. However, current methods only apply to rather simple reports, like multiple-choice or scalar numbers. We aim to broaden these techniques to the larger domain of text-based reports, drawing on the recent developments in large language models. This vastly increases the applicability of peer prediction mechanisms as textual feedback is the norm in a large variety of feedback channels: peer reviews, e-commerce customer reviews, and comments on social media. We introduce two mechanisms, the Generative Peer Prediction Mechanism (GPPM) and the Generative Synopsis Peer Prediction Mechanism (GSPPM). These mechanisms utilize LLMs as predictors, mapping from one agent's report to a prediction of her peer's report. Theoretically, we show that when the LLM prediction is sufficiently accurate, our mechanisms can incentivize high effort and truth-telling as an (approximate) Bayesian Nash equilibrium. Empirically, we confirm the efficacy of our mechanisms through experiments conducted on two real datasets: the Yelp review dataset and the ICLR OpenReview dataset. We highlight the results that on the ICLR dataset, our mechanisms can differentiate three quality levels -- human-written reviews, GPT-4-generated reviews, and GPT-3.5-generated reviews in terms of expected scores. Additionally, GSPPM penalizes LLM-generated reviews more effectively than GPPM.
Create account to get full access
Overview
- This paper explores how to elicit more informative and actionable text evaluations from large language models (LLMs).
- The researchers develop a framework to guide LLMs to provide detailed, high-quality feedback on text, going beyond simple ratings or binary judgments.
- They test their approach on a range of text evaluation tasks, including summarization, translation, and text generation.
- The findings suggest that their method can lead to more comprehensive and insightful text evaluations from LLMs.
Plain English Explanation
The paper focuses on improving the way large language models (LLMs) - powerful AI systems that can understand and generate human-like text - provide feedback and evaluations on different types of text, such as summaries, translations, or generated content.
Typically, when asked to evaluate text, LLMs might just give a simple rating or a binary judgment (e.g. "good" or "bad"). However, the researchers recognized that more detailed and actionable feedback could be valuable, for example to help writers, translators or content creators improve their work.
So they developed a framework to guide LLMs to provide richer, more comprehensive evaluations. This involved giving the LLMs additional prompts and instructions to encourage them to analyze the text in depth, highlight both strengths and weaknesses, and suggest concrete ways to improve.
When tested on a variety of text evaluation tasks, this approach led the LLMs to generate much more informative and useful feedback compared to their typical responses. The researchers believe this could be a valuable tool for anyone seeking high-quality, constructive evaluations of their text-based work from powerful AI systems.
Technical Explanation
The paper presents a framework for eliciting more informative and actionable text evaluations from large language models (LLMs). Typical text evaluation tasks often result in LLMs providing simplistic ratings or binary judgments (e.g. "good" or "bad"). To address this, the researchers developed a multi-stage prompting approach to guide LLMs to generate more detailed and comprehensive feedback.
The key elements of their framework include:
- Providing LLMs with a set of targeted prompts to evaluate different aspects of the text, such as [object Object], [object Object], and [object Object].
- Instructing the LLMs to not only identify strengths and weaknesses, but also suggest specific ways to improve the text.
- Encouraging the LLMs to provide a holistic, multi-paragraph evaluation rather than a single rating or judgment.
The researchers tested their framework on a range of text evaluation tasks, including [object Object], translation, and [object Object]. Their results showed that this approach led to significantly more informative and actionable feedback from the LLMs compared to their typical responses.
Critical Analysis
The researchers acknowledge several limitations and areas for future research:
- The effectiveness of the framework may depend on the specific prompts and instructions provided, which require careful design and testing.
- The evaluations generated by LLMs, even with the proposed framework, may still contain biases or inconsistencies that need to be addressed.
- It's unclear how well the framework would scale to more complex or open-ended text evaluation tasks beyond the specific scenarios tested in the paper.
Additionally, while the paper demonstrates the potential benefits of using targeted prompts to elicit more informative LLM evaluations, it does not explore alternative approaches, such as fine-tuning the LLMs on high-quality human evaluations or using ensemble models to generate more reliable feedback.
Conclusion
This paper presents a promising framework for eliciting more detailed and actionable text evaluations from large language models. By guiding LLMs with carefully designed prompts and instructions, the researchers were able to significantly improve the quality and informativeness of the feedback generated, which could be valuable for a wide range of text-based applications and use cases.
While the approach has some limitations and areas for further research, the findings suggest that thoughtful prompt engineering can be an effective way to unlock the full potential of LLMs as intelligent, high-fidelity evaluators of text-based content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
ElicitationGPT: Text Elicitation Mechanisms via Language Models
Yifan Wu, Jason Hartline
0
0
Scoring rules evaluate probabilistic forecasts of an unknown state against the realized state and are a fundamental building block in the incentivized elicitation of information and the training of machine learning models. This paper develops mechanisms for scoring elicited text against ground truth text using domain-knowledge-free queries to a large language model (specifically ChatGPT) and empirically evaluates their alignment with human preferences. The empirical evaluation is conducted on peer reviews from a peer-grading dataset and in comparison to manual instructor scores for the peer reviews.
6/21/2024
💬
PRE: A Peer Review Based Large Language Model Evaluator
Zhumin Chu, Qingyao Ai, Yiteng Tu, Haitao Li, Yiqun Liu
0
0
The impressive performance of large language models (LLMs) has attracted considerable attention from the academic and industrial communities. Besides how to construct and train LLMs, how to effectively evaluate and compare the capacity of LLMs has also been well recognized as an important yet difficult problem. Existing paradigms rely on either human annotators or model-based evaluators to evaluate the performance of LLMs on different tasks. However, these paradigms often suffer from high cost, low generalizability, and inherited biases in practice, which make them incapable of supporting the sustainable development of LLMs in long term. In order to address these issues, inspired by the peer review systems widely used in academic publication process, we propose a novel framework that can automatically evaluate LLMs through a peer-review process. Specifically, for the evaluation of a specific task, we first construct a small qualification exam to select reviewers from a couple of powerful LLMs. Then, to actually evaluate the submissions written by different candidate LLMs, i.e., the evaluatees, we use the reviewer LLMs to rate or compare the submissions. The final ranking of evaluatee LLMs is generated based on the results provided by all reviewers. We conducted extensive experiments on text summarization tasks with eleven LLMs including GPT-4. The results demonstrate the existence of biasness when evaluating using a single LLM. Also, our PRE model outperforms all the baselines, illustrating the effectiveness of the peer review mechanism.
6/4/2024
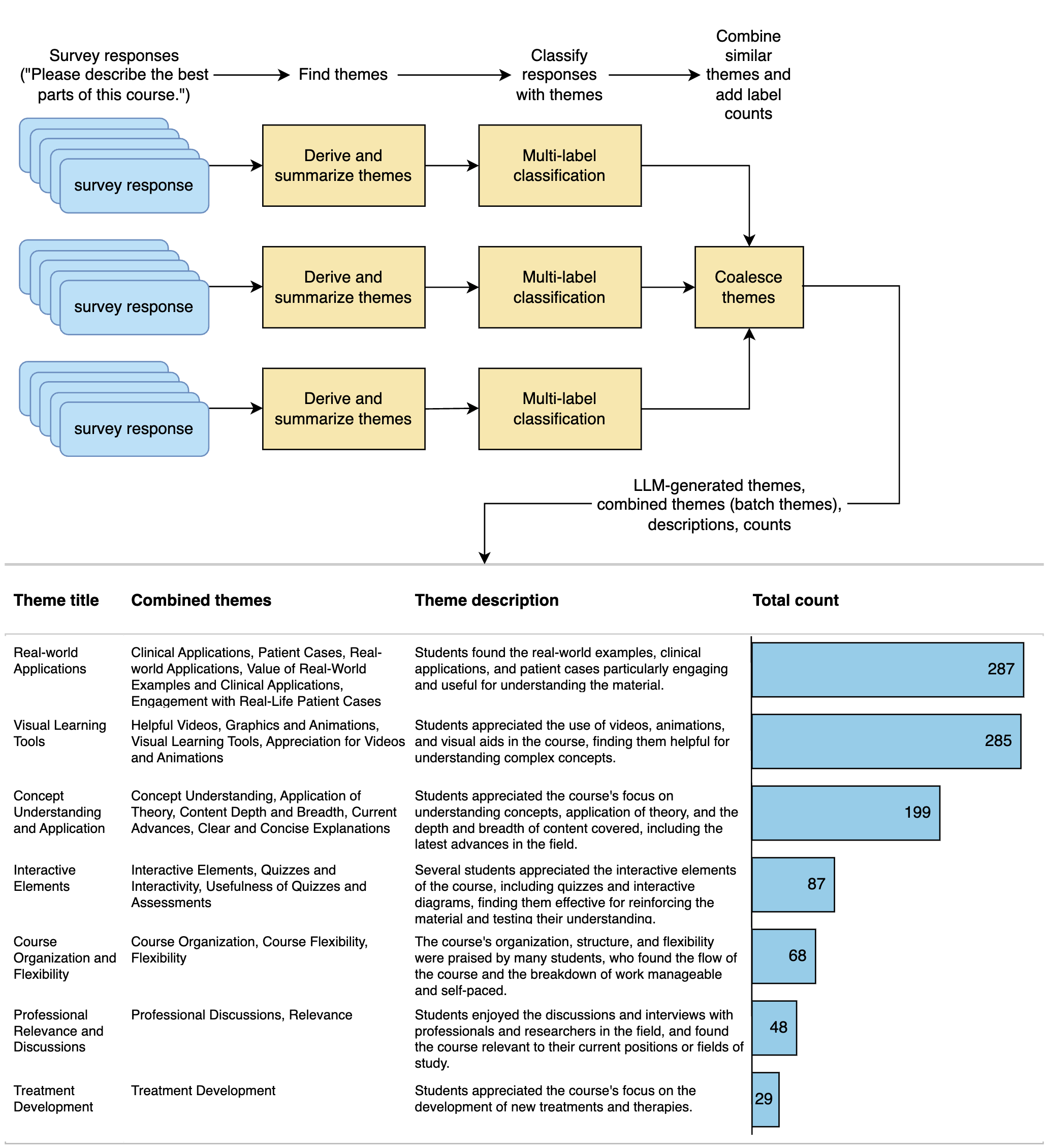
A Large Language Model Approach to Educational Survey Feedback Analysis
Michael J. Parker, Caitlin Anderson, Claire Stone, YeaRim Oh
0
0
This paper assesses the potential for the large language models (LLMs) GPT-4 and GPT-3.5 to aid in deriving insight from education feedback surveys. Exploration of LLM use cases in education has focused on teaching and learning, with less exploration of capabilities in education feedback analysis. Survey analysis in education involves goals such as finding gaps in curricula or evaluating teachers, often requiring time-consuming manual processing of textual responses. LLMs have the potential to provide a flexible means of achieving these goals without specialized machine learning models or fine-tuning. We demonstrate a versatile approach to such goals by treating them as sequences of natural language processing (NLP) tasks including classification (multi-label, multi-class, and binary), extraction, thematic analysis, and sentiment analysis, each performed by LLM. We apply these workflows to a real-world dataset of 2500 end-of-course survey comments from biomedical science courses, and evaluate a zero-shot approach (i.e., requiring no examples or labeled training data) across all tasks, reflecting education settings, where labeled data is often scarce. By applying effective prompting practices, we achieve human-level performance on multiple tasks with GPT-4, enabling workflows necessary to achieve typical goals. We also show the potential of inspecting LLMs' chain-of-thought (CoT) reasoning for providing insight that may foster confidence in practice. Moreover, this study features development of a versatile set of classification categories, suitable for various course types (online, hybrid, or in-person) and amenable to customization. Our results suggest that LLMs can be used to derive a range of insights from survey text.
6/28/2024

Large Language Models as Evaluators for Recommendation Explanations
Xiaoyu Zhang, Yishan Li, Jiayin Wang, Bowen Sun, Weizhi Ma, Peijie Sun, Min Zhang
0
0
The explainability of recommender systems has attracted significant attention in academia and industry. Many efforts have been made for explainable recommendations, yet evaluating the quality of the explanations remains a challenging and unresolved issue. In recent years, leveraging LLMs as evaluators presents a promising avenue in Natural Language Processing tasks (e.g., sentiment classification, information extraction), as they perform strong capabilities in instruction following and common-sense reasoning. However, evaluating recommendation explanatory texts is different from these NLG tasks, as its criteria are related to human perceptions and are usually subjective. In this paper, we investigate whether LLMs can serve as evaluators of recommendation explanations. To answer the question, we utilize real user feedback on explanations given from previous work and additionally collect third-party annotations and LLM evaluations. We design and apply a 3-level meta evaluation strategy to measure the correlation between evaluator labels and the ground truth provided by users. Our experiments reveal that LLMs, such as GPT4, can provide comparable evaluations with appropriate prompts and settings. We also provide further insights into combining human labels with the LLM evaluation process and utilizing ensembles of multiple heterogeneous LLM evaluators to enhance the accuracy and stability of evaluations. Our study verifies that utilizing LLMs as evaluators can be an accurate, reproducible and cost-effective solution for evaluating recommendation explanation texts. Our code is available at https://github.com/Xiaoyu-SZ/LLMasEvaluator.
6/7/2024