Towards Fundamentally Scalable Model Selection: Asymptotically Fast Update and Selection

0

Sign in to get full access
Overview
- This paper proposes a new approach for efficient model selection that is scalable and can handle large-scale machine learning problems.
- The key ideas are:
- Asymptotically Fast Update and Selection: The authors develop a method that can update and select models much faster than traditional approaches, especially as the problem size grows.
- Leveraging the Structure of the Problem: The method exploits the specific structure of model selection problems to achieve these efficiency gains.
Plain English Explanation
The paper addresses a common challenge in machine learning - how to efficiently choose the best model for a given task from a large set of candidate models. This is known as the "model selection" problem, and it's important because the choice of model can significantly impact the performance of the final system.
Traditional model selection approaches can become extremely slow and computationally intensive as the number of candidate models grows. The authors of this paper have developed a new technique that can update and select models much faster, especially for large-scale problems.
The key insight is to exploit the specific structure of the model selection problem. By leveraging certain mathematical properties, the authors are able to devise a method that can rapidly update the performance estimates of candidate models and quickly identify the best one. This is in contrast to more brute-force approaches that may need to re-evaluate every candidate model from scratch every time a new data point is added.
The proposed technique could be particularly useful in domains like speech recognition or recommendation systems, where the model selection problem can involve thousands or even millions of candidate models. By speeding up this process, the authors hope to enable more efficient and scalable machine learning applications.
Technical Explanation
The paper introduces a new approach for efficient model selection that can handle large-scale machine learning problems. The key technical contributions are:
-
Asymptotically Fast Update and Selection: The authors develop a method that can update and select models much faster than traditional approaches, especially as the problem size grows. This is achieved by leveraging the specific structure of the model selection problem.
-
Leveraging the Structure of the Problem: The authors show that by exploiting certain mathematical properties of the model selection problem, they can devise a computationally efficient technique for updating and selecting models.
Specifically, the authors consider a setup where there is a set of candidate models, and the goal is to choose the best-performing model based on some evaluation metric (e.g., prediction accuracy on a held-out dataset). Traditional approaches may need to re-evaluate every candidate model from scratch every time a new data point is added, which can become prohibitively slow for large-scale problems.
In contrast, the proposed method leverages the fact that the updates to the evaluation metric (e.g., model performance) can be computed efficiently by exploiting the specific structure of the problem. This allows for much faster updates and selection of the best model, particularly as the problem size increases.
The authors demonstrate the effectiveness of their approach through theoretical analysis and empirical evaluations on several benchmark datasets. They show that their method can achieve significant speedups compared to traditional model selection techniques, without compromising the quality of the final selected model.
Critical Analysis
The paper presents a promising approach for efficient model selection, but there are a few potential limitations and areas for further research:
-
Assumptions and Applicability: The authors make certain assumptions about the structure of the model selection problem, such as the availability of efficient update rules for the evaluation metric. While these assumptions may hold in many practical scenarios, it would be valuable to understand the limitations of the approach and explore its applicability to a wider range of model selection problems.
-
Robustness and Stability: The paper focuses on the computational efficiency of the proposed method, but it would be important to also investigate its robustness and stability, especially in the presence of noisy or adversarial data. Neuro-symbolic approaches may offer potential benefits in this regard.
-
Scalability to Extremely Large-Scale Problems: While the method is shown to be scalable, it would be interesting to explore its performance on truly massive-scale problems involving millions or even billions of candidate models. Potential bottlenecks or limitations may emerge at such scales, warranting further investigation.
-
Practical Considerations and Implementation Details: The paper provides a high-level theoretical framework, but more work may be needed to develop practical guidelines and best practices for implementing the proposed technique in real-world machine learning pipelines.
Overall, the paper presents a compelling approach that could have significant implications for the scalability and efficiency of model selection in large-scale machine learning applications. Further research and practical validation would be valuable to fully assess the method's potential and limitations.
Conclusion
This paper introduces a new technique for efficient model selection that can significantly speed up the process of identifying the best-performing model, especially for large-scale machine learning problems. By exploiting the structure of the model selection problem, the authors have developed a method that can rapidly update and select models without the need to re-evaluate every candidate from scratch.
The proposed approach could have important implications for a wide range of applications, from speech recognition to recommendation systems, where the model selection problem can involve a vast number of candidate models. By enabling more efficient and scalable model selection, the authors hope to contribute to the development of more powerful and practical machine learning systems.
While the paper presents a promising solution, further research is needed to fully understand the method's limitations, robustness, and practical implementation details. Nonetheless, the core ideas introduced in this work represent an important step towards fundamentally scalable model selection in the field of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Fundamentally Scalable Model Selection: Asymptotically Fast Update and Selection
Wenxiao Wang, Weiming Zhuang, Lingjuan Lyu
The advancement of deep learning technologies is bringing new models every day, motivating the study of scalable model selection. An ideal model selection scheme should minimally support two operations efficiently over a large pool of candidate models: update, which involves either adding a new candidate model or removing an existing candidate model, and selection, which involves locating highly performing models for a given task. However, previous solutions to model selection require high computational complexity for at least one of these two operations. In this work, we target fundamentally (more) scalable model selection that supports asymptotically fast update and asymptotically fast selection at the same time. Firstly, we define isolated model embedding, a family of model selection schemes supporting asymptotically fast update and selection: With respect to the number of candidate models $m$, the update complexity is O(1) and the selection consists of a single sweep over $m$ vectors in addition to O(1) model operations. Isolated model embedding also implies several desirable properties for applications. Secondly, we present Standardized Embedder, an empirical realization of isolated model embedding. We assess its effectiveness by using it to select representations from a pool of 100 pre-trained vision models for classification tasks and measuring the performance gaps between the selected models and the best candidates with a linear probing protocol. Experiments suggest our realization is effective in selecting models with competitive performances and highlight isolated model embedding as a promising direction towards model selection that is fundamentally (more) scalable.
Read more6/12/2024

0
On the Embedding Collapse when Scaling up Recommendation Models
Xingzhuo Guo, Junwei Pan, Ximei Wang, Baixu Chen, Jie Jiang, Mingsheng Long
Recent advances in foundation models have led to a promising trend of developing large recommendation models to leverage vast amounts of available data. Still, mainstream models remain embarrassingly small in size and naive enlarging does not lead to sufficient performance gain, suggesting a deficiency in the model scalability. In this paper, we identify the embedding collapse phenomenon as the inhibition of scalability, wherein the embedding matrix tends to occupy a low-dimensional subspace. Through empirical and theoretical analysis, we demonstrate a emph{two-sided effect} of feature interaction specific to recommendation models. On the one hand, interacting with collapsed embeddings restricts embedding learning and exacerbates the collapse issue. On the other hand, interaction is crucial in mitigating the fitting of spurious features as a scalability guarantee. Based on our analysis, we propose a simple yet effective multi-embedding design incorporating embedding-set-specific interaction modules to learn embedding sets with large diversity and thus reduce collapse. Extensive experiments demonstrate that this proposed design provides consistent scalability and effective collapse mitigation for various recommendation models. Code is available at this repository: https://github.com/thuml/Multi-Embedding.
Read more6/7/2024
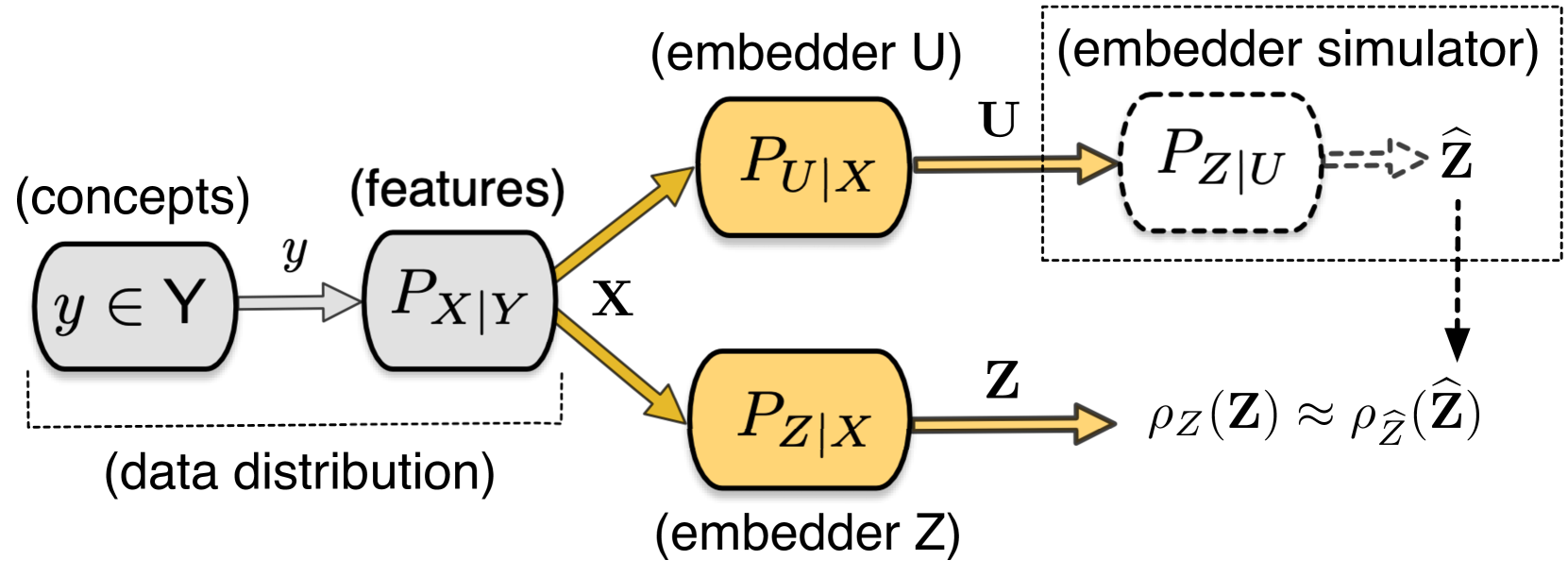
0
When is an Embedding Model More Promising than Another?
Maxime Darrin, Philippe Formont, Ismail Ben Ayed, Jackie CK Cheung, Pablo Piantanida
Embedders play a central role in machine learning, projecting any object into numerical representations that can, in turn, be leveraged to perform various downstream tasks. The evaluation of embedding models typically depends on domain-specific empirical approaches utilizing downstream tasks, primarily because of the lack of a standardized framework for comparison. However, acquiring adequately large and representative datasets for conducting these assessments is not always viable and can prove to be prohibitively expensive and time-consuming. In this paper, we present a unified approach to evaluate embedders. First, we establish theoretical foundations for comparing embedding models, drawing upon the concepts of sufficiency and informativeness. We then leverage these concepts to devise a tractable comparison criterion (information sufficiency), leading to a task-agnostic and self-supervised ranking procedure. We demonstrate experimentally that our approach aligns closely with the capability of embedding models to facilitate various downstream tasks in both natural language processing and molecular biology. This effectively offers practitioners a valuable tool for prioritizing model trials.
Read more6/13/2024
🤿
0
Deep Neural Network Benchmarks for Selective Classification
Andrea Pugnana, Lorenzo Perini, Jesse Davis, Salvatore Ruggieri
With the increasing deployment of machine learning models in many socially sensitive tasks, there is a growing demand for reliable and trustworthy predictions. One way to accomplish these requirements is to allow a model to abstain from making a prediction when there is a high risk of making an error. This requires adding a selection mechanism to the model, which selects those examples for which the model will provide a prediction. The selective classification framework aims to design a mechanism that balances the fraction of rejected predictions (i.e., the proportion of examples for which the model does not make a prediction) versus the improvement in predictive performance on the selected predictions. Multiple selective classification frameworks exist, most of which rely on deep neural network architectures. However, the empirical evaluation of the existing approaches is still limited to partial comparisons among methods and settings, providing practitioners with little insight into their relative merits. We fill this gap by benchmarking 18 baselines on a diverse set of 44 datasets that includes both image and tabular data. Moreover, there is a mix of binary and multiclass tasks. We evaluate these approaches using several criteria, including selective error rate, empirical coverage, distribution of rejected instance's classes, and performance on out-of-distribution instances. The results indicate that there is not a single clear winner among the surveyed baselines, and the best method depends on the users' objectives.
Read more9/19/2024