Embodied LLM Agents Learn to Cooperate in Organized Teams
2403.12482
0
0

Abstract
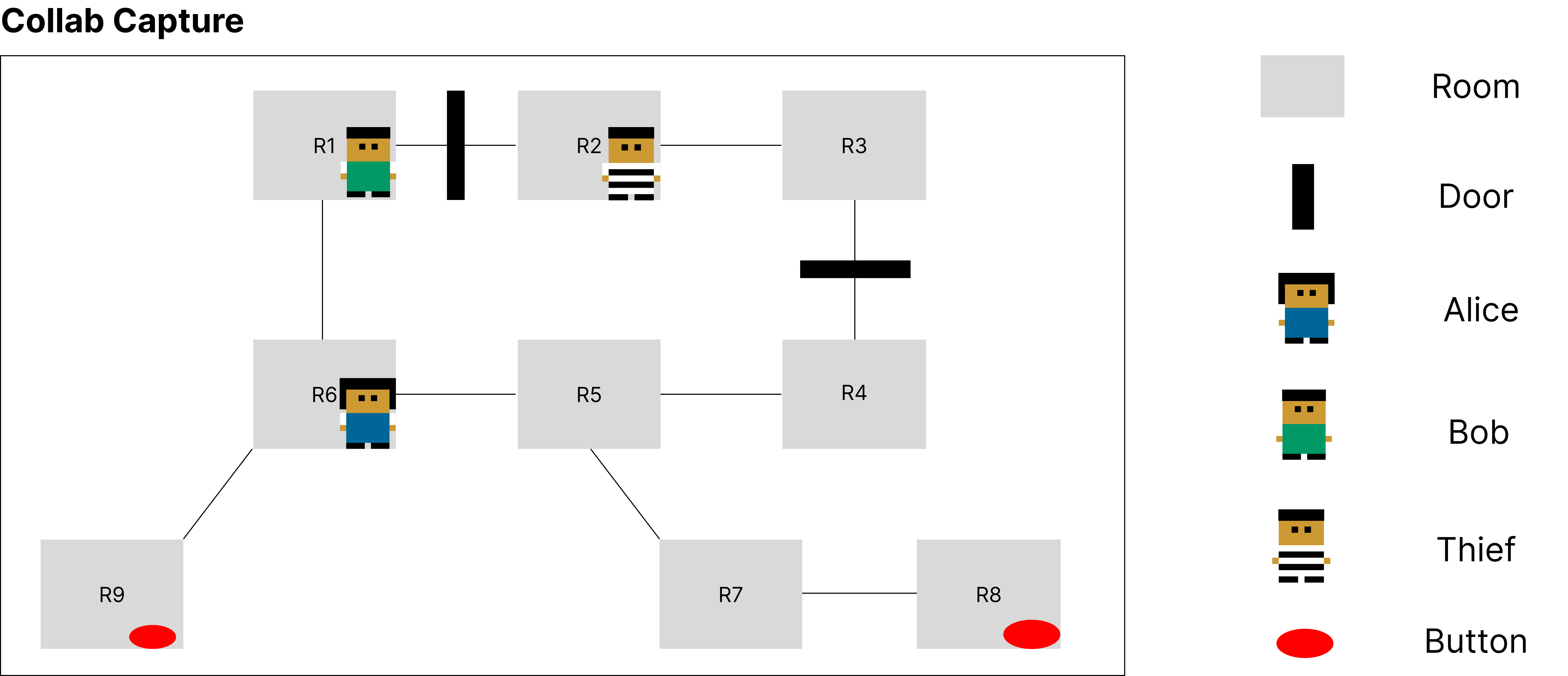
Large Language Models (LLMs) have emerged as integral tools for reasoning, planning, and decision-making, drawing upon their extensive world knowledge and proficiency in language-related tasks. LLMs thus hold tremendous potential for natural language interaction within multi-agent systems to foster cooperation. However, LLM agents tend to over-report and comply with any instruction, which may result in information redundancy and confusion in multi-agent cooperation. Inspired by human organizations, this paper introduces a framework that imposes prompt-based organization structures on LLM agents to mitigate these problems. Through a series of experiments with embodied LLM agents and human-agent collaboration, our results highlight the impact of designated leadership on team efficiency, shedding light on the leadership qualities displayed by LLM agents and their spontaneous cooperative behaviors. Further, we harness the potential of LLMs to propose enhanced organizational prompts, via a Criticize-Reflect process, resulting in novel organization structures that reduce communication costs and enhance team efficiency.
Create account to get full access
Overview
- This paper explores how large language model (LLM) agents can learn to cooperate effectively in organized teams through multi-agent reinforcement learning.
- The researchers developed a simulation environment where LLM agents must work together to complete tasks and navigate complex scenarios.
- Key findings include the agents' ability to develop coordination strategies, communicate, and adapt to changing conditions - insights that could inform the development of more cooperative and intelligent multi-agent systems.
Plain English Explanation
In this research, the scientists created a virtual environment where artificial intelligence (AI) agents powered by large language models (LLMs) had to work together as a team to accomplish various tasks. LLMs are a type of advanced AI that can understand and generate human-like language.
The goal was to see if these AI agents could learn how to cooperate effectively, communicate with each other, and coordinate their actions - even though they weren't originally designed to work together. This is an important challenge because in the real world, we often need AI systems to collaborate, not just act independently.
The researchers set up different scenarios where the agents had to navigate obstacles, gather resources, or complete other objectives as a group. Over time, the agents were able to develop their own strategies for working together. They learned how to share information, divide up responsibilities, and adjust their behavior based on what the others were doing.
These findings suggest that it's possible to train LLM-based AI agents to be more collaborative and "team-oriented," rather than just focusing on individual goals. This could be valuable for applications like robotics, logistics, or even virtual assistant systems, where coordination and cooperation between AI agents is crucial.
Of course, there are still many open questions and challenges to address, such as how to scale these techniques to larger teams, or how to ensure the agents behave ethically and avoid unintended consequences. But this research represents an important step forward in the development of more sophisticated, socially-aware AI systems.
Technical Explanation
The paper presents a novel framework for training embodied LLM agents to cooperate effectively in multi-agent environments. The researchers developed a simulation environment where LLM-based agents must navigate, gather resources, and complete tasks as a team.
Through a series of experiments, the authors demonstrate the agents' ability to:
- Develop effective coordination strategies to accomplish shared objectives.
- Communicate and share information with one another to improve team performance.
- Adapt their behavior in response to changing environmental conditions or the actions of other agents.
The agents were trained using a multi-agent reinforcement learning approach, where they received rewards based on the team's collective performance. This incentivized the development of cooperative behaviors, rather than purely selfish actions.
The paper also includes an analysis of the agents' communication patterns and decision-making processes, providing insight into how the LLM-based agents are able to coordinate their actions.
Critical Analysis
The research presented in this paper represents an important step forward in the development of multi-agent systems powered by large language models. The ability of the agents to cooperate, communicate, and adapt to changing conditions is a significant achievement.
However, the authors acknowledge several limitations and areas for further research:
- The simulation environment, while complex, may not fully capture the nuances of real-world multi-agent scenarios. More work is needed to validate the findings in physical or more realistic virtual settings.
- The scalability of the approach to larger teams with more agents is unclear and requires additional investigation.
- The ethical implications of deploying such systems in the real world, particularly around issues of transparency, accountability, and potential for misuse, need to be carefully considered.
Additionally, while the paper provides a thorough technical explanation, there may be room for further exploration of the broader societal implications of this research. For example, how might these techniques be applied to improve human-AI collaboration, or to foster cooperation in areas like disaster response or supply chain management?
Overall, this paper represents an important contribution to the field of multi-agent systems and the ongoing development of more collaborative and intelligent AI agents. However, continued research and careful consideration of the ethical and societal impacts will be essential as these technologies continue to advance.
Conclusion
This paper presents a novel approach for training large language model (LLM) agents to cooperate effectively in multi-agent environments. Through a combination of reinforcement learning and communication strategies, the agents were able to develop coordination tactics, share information, and adapt to changing conditions - all crucial capabilities for intelligent, collaborative systems.
The findings of this research could have significant implications for the development of more sophisticated and socially-aware AI agents, with potential applications in areas like robotics, logistics, and virtual assistant systems. However, the authors also highlight the need for further validation, scalability testing, and ethical considerations as these technologies continue to evolve.
Overall, this work represents an important step forward in the quest to create AI systems that can work together seamlessly, much like human teams, to tackle complex challenges and achieve shared goals. As the field of multi-agent systems continues to advance, the insights and techniques presented in this paper will undoubtedly inform and inspire future research in this exciting and rapidly-evolving domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View
Jintian Zhang, Xin Xu, Ningyu Zhang, Ruibo Liu, Bryan Hooi, Shumin Deng
0
0
As Natural Language Processing (NLP) systems are increasingly employed in intricate social environments, a pressing query emerges: Can these NLP systems mirror human-esque collaborative intelligence, in a multi-agent society consisting of multiple large language models (LLMs)? This paper probes the collaboration mechanisms among contemporary NLP systems by melding practical experiments with theoretical insights. We fabricate four unique `societies' comprised of LLM agents, where each agent is characterized by a specific `trait' (easy-going or overconfident) and engages in collaboration with a distinct `thinking pattern' (debate or reflection). Through evaluating these multi-agent societies on three benchmark datasets, we discern that certain collaborative strategies not only outshine previous top-tier approaches, but also optimize efficiency (using fewer API tokens). Moreover, our results further illustrate that LLM agents manifest human-like social behaviors, such as conformity and consensus reaching, mirroring foundational social psychology theories. In conclusion, we integrate insights from social psychology to contextualize the collaboration of LLM agents, inspiring further investigations into the collaboration mechanism for LLMs. We commit to sharing our code and datasetsfootnote{url{https://github.com/zjunlp/MachineSoM}.}, hoping to catalyze further research in this promising avenue.
5/28/2024
LLM-Coordination: Evaluating and Analyzing Multi-agent Coordination Abilities in Large Language Models
Saaket Agashe, Yue Fan, Anthony Reyna, Xin Eric Wang
0
0
The emergent reasoning and Theory of Mind (ToM) abilities demonstrated by Large Language Models (LLMs) make them promising candidates for developing coordination agents. In this study, we introduce a new LLM-Coordination Benchmark aimed at a detailed analysis of LLMs within the context of Pure Coordination Games, where participating agents need to cooperate for the most gain. This benchmark evaluates LLMs through two distinct tasks: (1) emph{Agentic Coordination}, where LLMs act as proactive participants for cooperation in 4 pure coordination games; (2) emph{Coordination Question Answering (QA)}, where LLMs are prompted to answer 198 multiple-choice questions from the 4 games for evaluation of three key reasoning abilities: Environment Comprehension, ToM Reasoning, and Joint Planning. Furthermore, to enable LLMs for multi-agent coordination, we introduce a Cognitive Architecture for Coordination (CAC) framework that can easily integrate different LLMs as plug-and-play modules for pure coordination games. Our findings indicate that LLM agents equipped with GPT-4-turbo achieve comparable performance to state-of-the-art reinforcement learning methods in games that require commonsense actions based on the environment. Besides, zero-shot coordination experiments reveal that, unlike RL methods, LLM agents are robust to new unseen partners. However, results on Coordination QA show a large room for improvement in the Theory of Mind reasoning and joint planning abilities of LLMs. The analysis also sheds light on how the ability of LLMs to understand their environment and their partner's beliefs and intentions plays a part in their ability to plan for coordination. Our code is available at url{https://github.com/eric-ai-lab/llm_coordination}.
4/4/2024
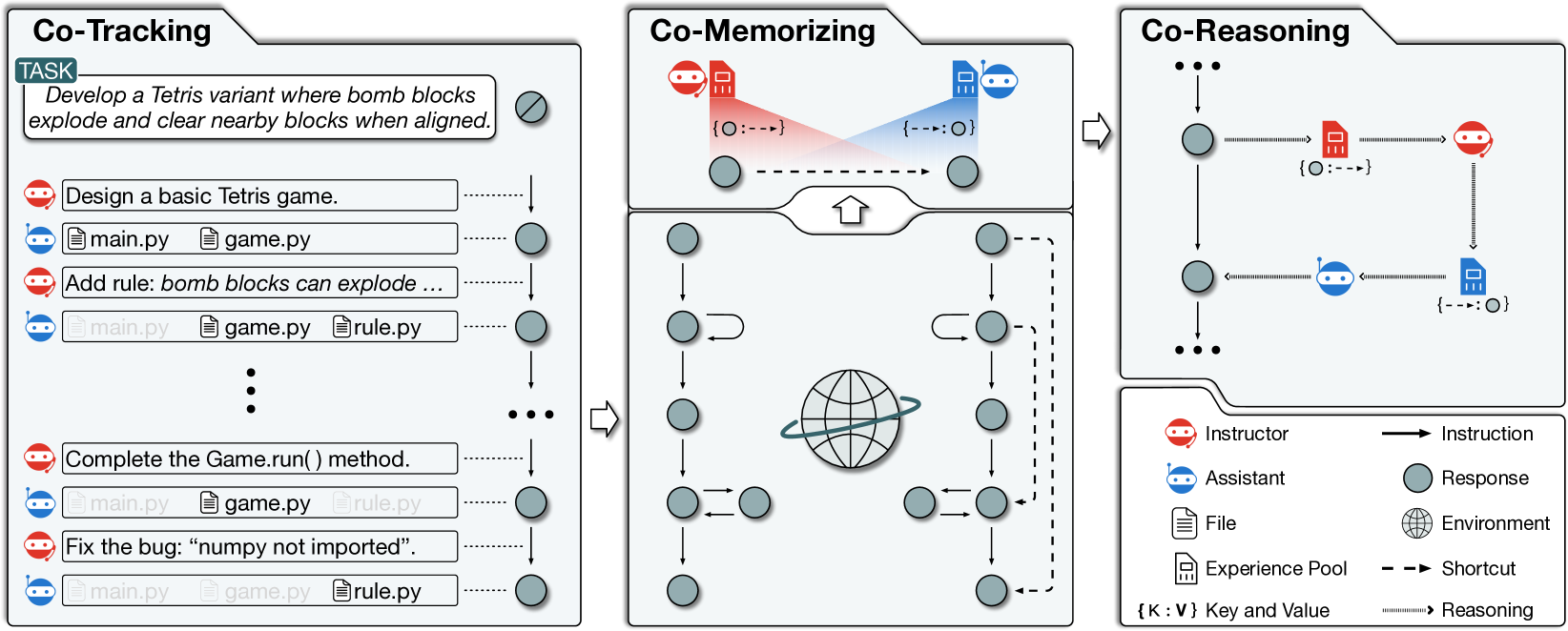
Experiential Co-Learning of Software-Developing Agents
Chen Qian, Yufan Dang, Jiahao Li, Wei Liu, Zihao Xie, Yifei Wang, Weize Chen, Cheng Yang, Xin Cong, Xiaoyin Che, Zhiyuan Liu, Maosong Sun
0
0
Recent advancements in large language models (LLMs) have brought significant changes to various domains, especially through LLM-driven autonomous agents. A representative scenario is in software development, where LLM agents demonstrate efficient collaboration, task division, and assurance of software quality, markedly reducing the need for manual involvement. However, these agents frequently perform a variety of tasks independently, without benefiting from past experiences, which leads to repeated mistakes and inefficient attempts in multi-step task execution. To this end, we introduce Experiential Co-Learning, a novel LLM-agent learning framework in which instructor and assistant agents gather shortcut-oriented experiences from their historical trajectories and use these past experiences for future task execution. The extensive experiments demonstrate that the framework enables agents to tackle unseen software-developing tasks more effectively. We anticipate that our insights will guide LLM agents towards enhanced autonomy and contribute to their evolutionary growth in cooperative learning. The code and data are available at https://github.com/OpenBMB/ChatDev.
6/6/2024
🏅
LLM-based Multi-Agent Reinforcement Learning: Current and Future Directions
Chuanneng Sun, Songjun Huang, Dario Pompili
0
0
In recent years, Large Language Models (LLMs) have shown great abilities in various tasks, including question answering, arithmetic problem solving, and poem writing, among others. Although research on LLM-as-an-agent has shown that LLM can be applied to Reinforcement Learning (RL) and achieve decent results, the extension of LLM-based RL to Multi-Agent System (MAS) is not trivial, as many aspects, such as coordination and communication between agents, are not considered in the RL frameworks of a single agent. To inspire more research on LLM-based MARL, in this letter, we survey the existing LLM-based single-agent and multi-agent RL frameworks and provide potential research directions for future research. In particular, we focus on the cooperative tasks of multiple agents with a common goal and communication among them. We also consider human-in/on-the-loop scenarios enabled by the language component in the framework.
5/21/2024