An Empirical Analysis of Compute-Optimal Inference for Problem-Solving with Language Models

0
Sign in to get full access
Overview
- The paper examines the trade-offs between computation and performance for solving problems using large language models (LLMs).
- It explores how to optimize inference to find the "compute-optimal" point that balances model performance and computational cost.
- The researchers conduct extensive empirical analyses on various LLM-based problem-solving tasks to understand the nuances of this trade-off.
Plain English Explanation
Large language models (LLMs) have shown impressive capabilities in solving a wide range of problems, from answering questions to generating text. However, using these models for practical applications can be computationally expensive, as they often require significant computational resources to run their inference algorithms.
This paper investigates the balance between the computational cost and the performance of LLMs in solving problems. The researchers examine different techniques for optimizing the inference process, aiming to find the "compute-optimal" point where the model's performance is maximized while the computational resources required are minimized.
The researchers conduct extensive empirical studies on various problem-solving tasks, such as question answering, text generation, and code generation. They analyze how factors like the number of inference steps, the type of decoding algorithm, and the model size affect the trade-off between computational cost and model performance.
The findings from this research can help developers and researchers optimize the use of LLMs in real-world applications, ensuring that the models can deliver high-quality results while keeping the computational requirements manageable. This is particularly important as LLMs continue to grow in size and complexity, making efficient inference a critical challenge.
Technical Explanation
The paper presents an empirical analysis of the trade-off between computation and performance for solving problems using large language models (LLMs). The researchers investigate the concept of "compute-optimal" inference, which aims to find the sweet spot where the model's performance is maximized while the computational cost is minimized.
The study involves extensive experiments across a diverse set of problem-solving tasks, including question answering, text generation, and code generation. The researchers explore various factors that influence the computation-performance trade-off, such as the number of inference steps, the choice of decoding algorithm (e.g., greedy search, beam search), and the model size.
To quantify the computational cost, the researchers use metrics like the number of floating-point operations (FLOPs) and the inference latency. They then analyze how these computational measures relate to the model's performance on each task, as measured by appropriate evaluation metrics (e.g., BLEU score for text generation, F1 score for question answering).
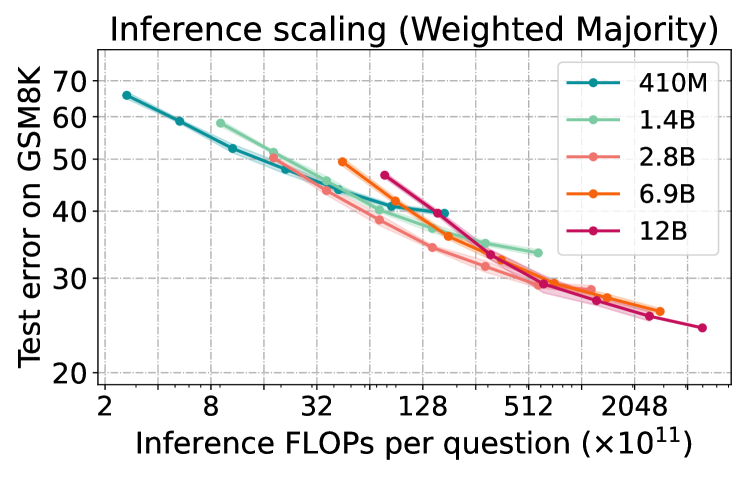
The findings from the empirical analysis provide insights into the nuances of this trade-off. For example, the researchers observe that increasing the number of inference steps can lead to diminishing returns in performance, while the computational cost continues to rise. They also explore the impact of different decoding strategies and model sizes on the computation-performance relationship.
These insights can inform the development of more efficient LLM-based systems, where the inference process is carefully optimized to deliver high-quality results while minimizing the computational burden. This is particularly relevant as LLMs continue to grow in size and complexity, making efficient inference a critical challenge for practical applications.
Critical Analysis
The paper presents a comprehensive and well-designed empirical study on the computation-performance trade-off in LLM-based problem-solving. The researchers have carefully considered a diverse set of tasks and explored various factors that influence this trade-off, providing a nuanced understanding of the problem.
One potential limitation of the study is the reliance on proxy metrics (e.g., FLOPs, inference latency) to quantify the computational cost. While these metrics are widely used, they may not fully capture the complexities of real-world deployment scenarios, where other factors like memory usage, energy consumption, and hardware-specific optimizations can also play a significant role.
Additionally, the paper focuses primarily on the inference process and does not delve into the costs associated with the model training or fine-tuning stages. In practical applications, the overall life cycle of the LLM, including training and deployment, must be considered to achieve true compute-optimal performance.
Furthermore, the paper does not explore the potential impact of more advanced inference techniques, such as using different types of decoding algorithms or incorporating additional optimization strategies (e.g., model distillation, sparse attention). Investigating the efficacy of these techniques in the context of the computation-performance trade-off could further enhance the practical implications of the research.
Despite these limitations, the paper makes a valuable contribution to the understanding of efficient LLM-based problem-solving. The insights and methodologies presented can serve as a foundation for future research and development in this important area.
Conclusion
This paper presents a comprehensive empirical analysis of the trade-off between computation and performance for solving problems using large language models (LLMs). The researchers explore the concept of "compute-optimal" inference, where the goal is to maximize the model's performance while minimizing the computational cost.
The findings from the extensive experiments across various problem-solving tasks provide valuable insights into the nuances of this trade-off. The researchers analyze how factors like the number of inference steps, the choice of decoding algorithm, and the model size impact the balance between computational cost and model performance.
These insights can inform the development of more efficient LLM-based systems, where the inference process is carefully optimized to deliver high-quality results while keeping the computational burden manageable. As LLMs continue to grow in size and complexity, the importance of such efficient inference techniques will only increase, making this research highly relevant for practical applications.
The paper's critical analysis highlights potential areas for further exploration, such as considering real-world deployment factors, incorporating advanced inference techniques, and exploring the costs associated with the entire LLM life cycle. Addressing these limitations can further strengthen the practical implications of this research and contribute to the ongoing efforts to make LLM-based problem-solving more accessible and efficient.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Empirical Analysis of Compute-Optimal Inference for Problem-Solving with Language Models
Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, Yiming Yang
The optimal training configurations of large language models (LLMs) with respect to model sizes and compute budgets have been extensively studied. But how to optimally configure LLMs during inference has not been explored in sufficient depth. We study compute-optimal inference: designing models and inference strategies that optimally trade off additional inference-time compute for improved performance. As a first step towards understanding and designing compute-optimal inference methods, we assessed the effectiveness and computational efficiency of multiple inference strategies such as Greedy Search, Majority Voting, Best-of-N, Weighted Voting, and their variants on two different Tree Search algorithms, involving different model sizes and computational budgets. We found that a smaller language model with a novel tree search algorithm typically achieves a Pareto-optimal trade-off. These results highlight the potential benefits of deploying smaller models equipped with more sophisticated decoding algorithms in budget-constrained scenarios, e.g., on end-devices, to enhance problem-solving accuracy. For instance, we show that the Llemma-7B model can achieve competitive accuracy to a Llemma-34B model on MATH500 while using $2times$ less FLOPs. Our findings could potentially apply to any generation task with a well-defined measure of success.
Read more8/2/2024
0
A Survey on Efficient Inference for Large Language Models
Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhihang Yuan, Xiuhong Li, Shengen Yan, Guohao Dai, Xiao-Ping Zhang, Yuhan Dong, Yu Wang
Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.
Read more7/22/2024
💬
1
From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models
Sean Welleck, Amanda Bertsch, Matthew Finlayson, Hailey Schoelkopf, Alex Xie, Graham Neubig, Ilia Kulikov, Zaid Harchaoui
One of the most striking findings in modern research on large language models (LLMs) is that scaling up compute during training leads to better results. However, less attention has been given to the benefits of scaling compute during inference. This survey focuses on these inference-time approaches. We explore three areas under a unified mathematical formalism: token-level generation algorithms, meta-generation algorithms, and efficient generation. Token-level generation algorithms, often called decoding algorithms, operate by sampling a single token at a time or constructing a token-level search space and then selecting an output. These methods typically assume access to a language model's logits, next-token distributions, or probability scores. Meta-generation algorithms work on partial or full sequences, incorporating domain knowledge, enabling backtracking, and integrating external information. Efficient generation methods aim to reduce token costs and improve the speed of generation. Our survey unifies perspectives from three research communities: traditional natural language processing, modern LLMs, and machine learning systems.
Read more6/26/2024
✅
0
More Compute Is What You Need
Zhen Guo
Large language model pre-training has become increasingly expensive, with most practitioners relying on scaling laws to allocate compute budgets for model size and training tokens, commonly referred to as Compute-Optimal or Chinchilla Optimal. In this paper, we hypothesize a new scaling law that suggests model performance depends mostly on the amount of compute spent for transformer-based models, independent of the specific allocation to model size and dataset size. Using this unified scaling law, we predict that (a) for inference efficiency, training should prioritize smaller model sizes and larger training datasets, and (b) assuming the exhaustion of available web datasets, scaling the model size might be the only way to further improve model performance.
Read more5/3/2024