Empirical influence functions to understand the logic of fine-tuning
2406.00509
1
0

Abstract
Understanding the process of learning in neural networks is crucial for improving their performance and interpreting their behavior. This can be approximately understood by asking how a model's output is influenced when we fine-tune on a new training sample. There are desiderata for such influences, such as decreasing influence with semantic distance, sparseness, noise invariance, transitive causality, and logical consistency. Here we use the empirical influence measured using fine-tuning to demonstrate how individual training samples affect outputs. We show that these desiderata are violated for both for simple convolutional networks and for a modern LLM. We also illustrate how prompting can partially rescue this failure. Our paper presents an efficient and practical way of quantifying how well neural networks learn from fine-tuning stimuli. Our results suggest that popular models cannot generalize or perform logic in the way they appear to.
Create account to get full access
Overview
- This paper introduces a novel technique called "empirical influence functions" to better understand the logic behind fine-tuning in machine learning models.
- The authors demonstrate how this method can provide insights into how fine-tuning modifies the decision-making process of pre-trained models.
- They apply the technique to several example tasks, including text classification and image recognition, to illustrate its capabilities.
Plain English Explanation
Fine-tuning is a powerful technique in machine learning where a pre-trained model is further trained on a specific task or dataset. This allows the model to learn task-specific knowledge and often leads to improved performance. However, the inner workings of this fine-tuning process can be difficult to understand.
The researchers in this paper developed a new method called "empirical influence functions" to shed light on how fine-tuning modifies the decision-making logic of pre-trained models. This technique allows them to identify which parts of the original model were most significantly changed during fine-tuning, and how those changes affected the model's outputs.
For example, they might find that fine-tuning a image recognition model on medical X-ray images caused it to focus more on certain anatomical features when making its predictions, compared to the original model trained on general images. This type of insight can be very valuable for understanding the strengths and limitations of fine-tuned models, and for guiding future model development.
The authors demonstrate the influence function technique on several tasks, including text classification and image recognition. They show how it can reveal meaningful differences in the decision-making logic between the original and fine-tuned models, providing a deeper understanding of the fine-tuning process.
Technical Explanation
The core idea behind empirical influence functions is to measure how modifying the training data of a machine learning model affects its final predictions. This is done by approximating the gradients of the model's outputs with respect to the training data, which provides a quantitative measure of how sensitive the model is to changes in the training examples.
The authors apply this technique to the fine-tuning process, where a pre-trained model is further trained on a specific task or dataset. By comparing the influence functions of the original and fine-tuned models, they can identify which parts of the original model were most significantly altered during fine-tuning, and how those changes impacted the model's decision-making logic.
For example, in a text classification task, the influence functions may reveal that fine-tuning caused the model to rely more heavily on certain keywords or phrases when making its predictions, compared to the original model. In an image recognition task, the influence functions could show that fine-tuning led the model to focus more on specific visual features, such as certain anatomical structures in medical images.
The authors demonstrate the empirical influence function technique on several benchmark tasks, including sentiment analysis, named entity recognition, and image classification. They show how this method can provide valuable insights into the inner workings of fine-tuned models, and how it can be used to better understand the logic behind their decision-making processes.
Critical Analysis
The empirical influence function technique presented in this paper represents a promising approach for gaining a deeper understanding of fine-tuning in machine learning models. By quantifying how changes to the training data affect model outputs, the method can reveal meaningful insights about the specific modifications made during fine-tuning.
However, it's important to note that the technique relies on several assumptions and approximations, which could limit its accuracy or applicability in certain scenarios. For example, the authors acknowledge that the method may be less reliable when dealing with large, complex models or datasets with significant noise or imbalances.
Additionally, while the paper demonstrates the technique on several common machine learning tasks, it would be valuable to see it applied to a wider range of domains and model architectures. This could help establish the generalizability and limitations of the approach, and provide a clearer understanding of its practical utility.
Overall, the empirical influence function method represents an important step forward in our ability to interpret the inner workings of fine-tuned machine learning models. By shedding light on how the fine-tuning process modifies a model's decision-making logic, this technique could lead to more transparent and accountable AI systems, as well as inform the development of more robust and reliable models in the future.
Conclusion
This paper introduces a novel technique called "empirical influence functions" that can provide valuable insights into the fine-tuning process in machine learning. By quantifying how changes to the training data affect a model's outputs, the method can reveal how fine-tuning modifies the decision-making logic of pre-trained models.
The authors demonstrate the technique on several benchmark tasks, showing how it can identify the specific parts of the original model that were most significantly altered during fine-tuning, and how those changes impacted the model's performance. This type of insight can be highly valuable for understanding the strengths and limitations of fine-tuned models, and for guiding future model development and deployment.
While the technique relies on several assumptions and may have some limitations, the empirical influence function method represents an important step forward in our ability to interpret and understand the inner workings of complex machine learning systems. As the field of AI continues to advance, tools like this will become increasingly crucial for building more transparent, accountable, and reliable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
Machine learning of network inference enhancement from noisy measurements
Kai Wu, Yuanyuan Li, Jing Liu
0
0
Inferring networks from observed time series data presents a clear glimpse into the interconnections among nodes. Network inference models, when dealing with real-world open cases, especially in the presence of observational noise, experience a sharp decline in performance, significantly undermining their practical applicability. We find that in real-world scenarios, noisy samples cause parameter updates in network inference models to deviate from the correct direction, leading to a degradation in performance. Here, we present an elegant and efficient model-agnostic framework tailored to amplify the capabilities of model-based and model-free network inference models for real-world cases. Extensive experiments across nonlinear dynamics, evolutionary games, and epidemic spreading, showcases substantial performance augmentation under varied noise types, particularly thriving in scenarios enriched with clean samples.
5/7/2024
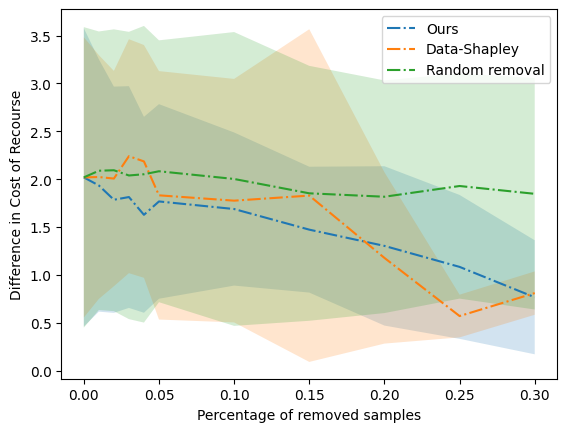
Analyzing the Influence of Training Samples on Explanations
Andr'e Artelt, Barbara Hammer
0
0
EXplainable AI (XAI) constitutes a popular method to analyze the reasoning of AI systems by explaining their decision-making, e.g. providing a counterfactual explanation of how to achieve recourse. However, in cases such as unexpected explanations, the user might be interested in learning about the cause of this explanation -- e.g. properties of the utilized training data that are responsible for the observed explanation. Under the umbrella of data valuation, first approaches have been proposed that estimate the influence of data samples on a given model. In this work, we take a slightly different stance, as we are interested in the influence of single samples on a model explanation rather than the model itself. Hence, we propose the novel problem of identifying training data samples that have a high influence on a given explanation (or related quantity) and investigate the particular case of differences in the cost of the recourse between protected groups. For this, we propose an algorithm that identifies such influential training samples.
6/6/2024
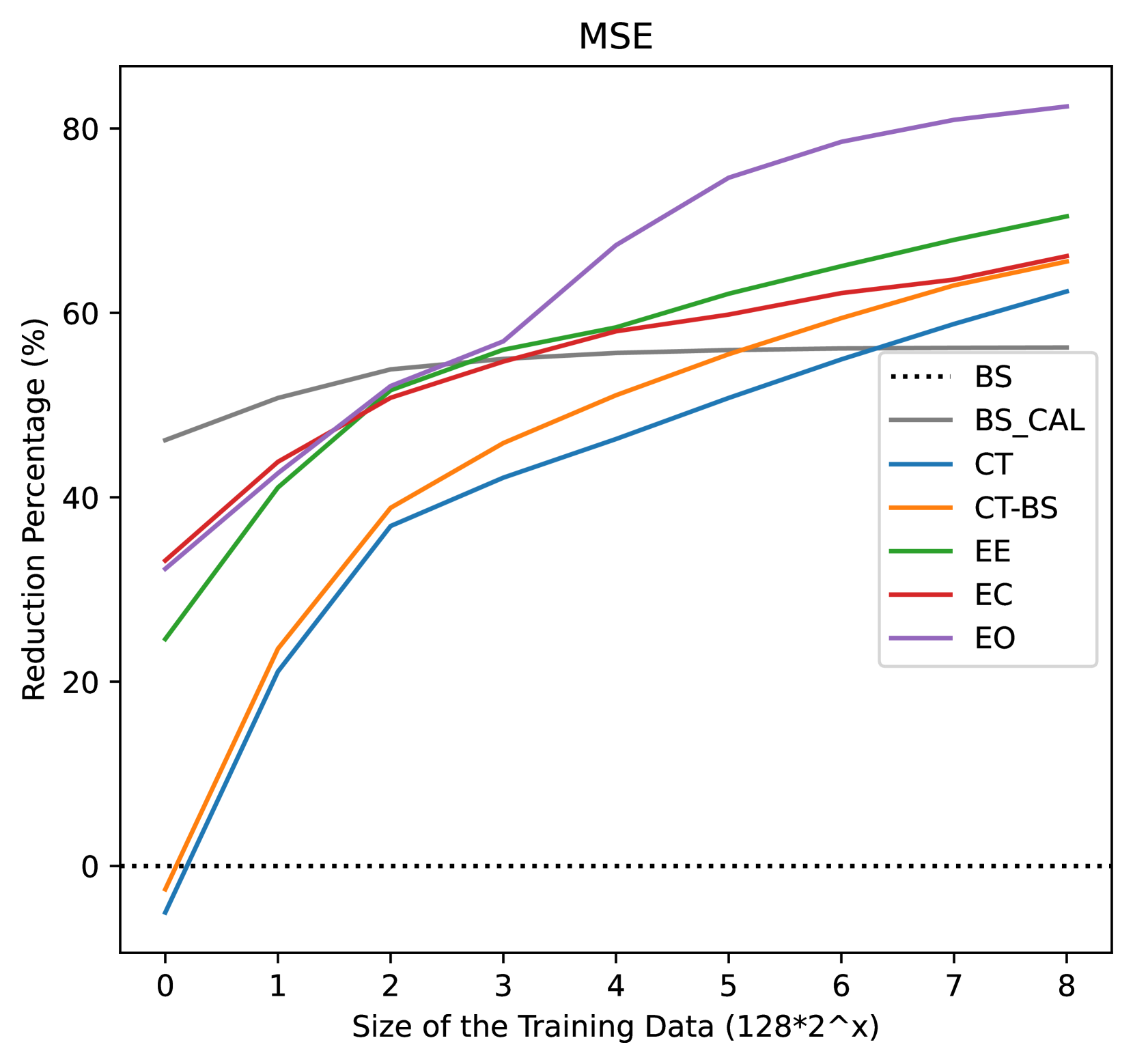
Causal Fine-Tuning and Effect Calibration of Non-Causal Predictive Models
Carlos Fern'andez-Lor'ia, Yanfang Hou, Foster Provost, Jennifer Hill
0
0
This paper proposes techniques to enhance the performance of non-causal models for causal inference using data from randomized experiments. In domains like advertising, customer retention, and precision medicine, non-causal models that predict outcomes under no intervention are often used to score individuals and rank them according to the expected effectiveness of an intervention (e.g, an ad, a retention incentive, a nudge). However, these scores may not perfectly correspond to intervention effects due to the inherent non-causal nature of the models. To address this limitation, we propose causal fine-tuning and effect calibration, two techniques that leverage experimental data to refine the output of non-causal models for different causal tasks, including effect estimation, effect ordering, and effect classification. They are underpinned by two key advantages. First, they can effectively integrate the predictive capabilities of general non-causal models with the requirements of a causal task in a specific context, allowing decision makers to support diverse causal applications with a foundational scoring model. Second, through simulations and an empirical example, we demonstrate that they can outperform the alternative of building a causal-effect model from scratch, particularly when the available experimental data is limited and the non-causal scores already capture substantial information about the relative sizes of causal effects. Overall, this research underscores the practical advantages of combining experimental data with non-causal models to support causal applications.
6/17/2024
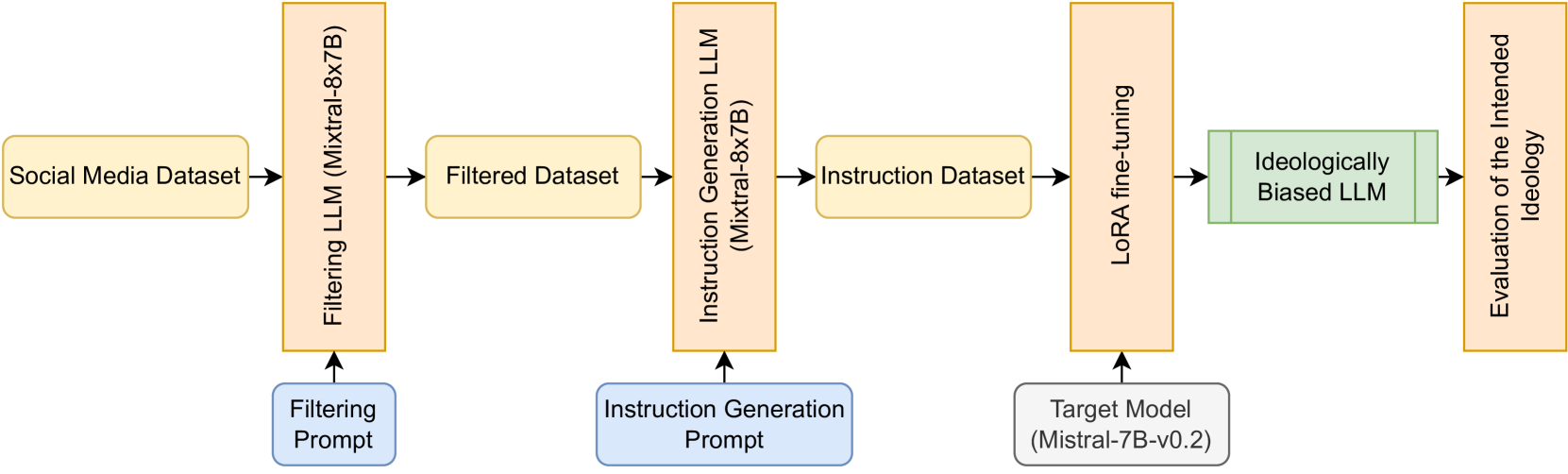
Analyzing the Impact of Data Selection and Fine-Tuning on Economic and Political Biases in LLMs
Ahmed Agiza, Mohamed Mostagir, Sherief Reda
0
0
In an era where language models are increasingly integrated into decision-making and communication, understanding the biases within Large Language Models (LLMs) becomes imperative, especially when these models are applied in the economic and political domains. This work investigates the impact of fine-tuning and data selection on economic and political biases in LLM. We explore the methodological aspects of biasing LLMs towards specific ideologies, mindful of the biases that arise from their extensive training on diverse datasets. Our approach, distinct from earlier efforts that either focus on smaller models or entail resource-intensive pre-training, employs Parameter-Efficient Fine-Tuning (PEFT) techniques. These techniques allow for the alignment of LLMs with targeted ideologies by modifying a small subset of parameters. We introduce a systematic method for dataset selection, annotation, and instruction tuning, and we assess its effectiveness through both quantitative and qualitative evaluations. Our work analyzes the potential of embedding specific biases into LLMs and contributes to the dialogue on the ethical application of AI, highlighting the importance of deploying AI in a manner that aligns with societal values.
4/23/2024