Analyzing the Influence of Training Samples on Explanations
2406.03012
0
0
Abstract
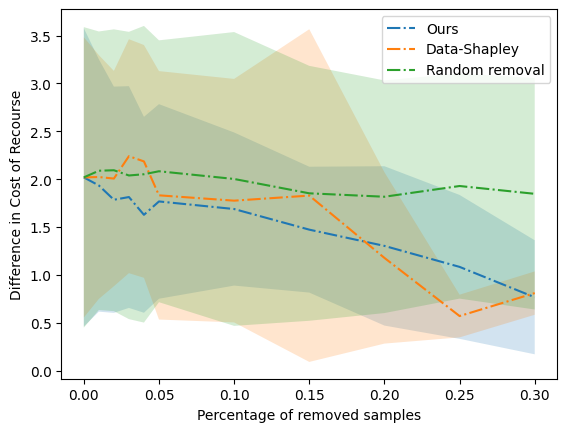
EXplainable AI (XAI) constitutes a popular method to analyze the reasoning of AI systems by explaining their decision-making, e.g. providing a counterfactual explanation of how to achieve recourse. However, in cases such as unexpected explanations, the user might be interested in learning about the cause of this explanation -- e.g. properties of the utilized training data that are responsible for the observed explanation. Under the umbrella of data valuation, first approaches have been proposed that estimate the influence of data samples on a given model. In this work, we take a slightly different stance, as we are interested in the influence of single samples on a model explanation rather than the model itself. Hence, we propose the novel problem of identifying training data samples that have a high influence on a given explanation (or related quantity) and investigate the particular case of differences in the cost of the recourse between protected groups. For this, we propose an algorithm that identifies such influential training samples.
Create account to get full access
Overview
- This paper analyzes how the choice of training samples can influence the explanations generated for machine learning models.
- The researchers explore the relationship between the training data and the resulting model explanations, a topic that has important implications for the transparency and interpretability of AI systems.
- The paper proposes a framework for quantifying the influence of training samples on explanations and demonstrates its application on several real-world datasets.
Plain English Explanation
Machine learning models are increasingly being used to make important decisions, from medical diagnoses to financial transactions. However, these models can be complex and opaque, making it difficult to understand how they arrive at their predictions. This has led to a growing emphasis on model interpretability and explainability.
One key aspect of model interpretability is the ability to generate explanations for the model's outputs. These explanations can take various forms, such as highlighting the most important features used by the model or illustrating the causal relationships between inputs and outputs. But the quality and reliability of these explanations can be influenced by the choice of training data used to build the model.
This paper explores how the training samples selected for a machine learning model can affect the resulting explanations. The researchers propose a framework for quantifying this influence, which can help developers and users better understand the limitations and potential biases in the explanations generated by their models. By understanding the connection between training data and explanations, they can create more transparent and trustworthy AI systems.
Technical Explanation
The paper introduces a framework for analyzing the influence of training samples on model explanations. The key components of this framework are:
-
Explanation Generation: The researchers use a model-agnostic explanation method, such as LIME or SHAP, to generate explanations for the model's predictions.
-
Influence Quantification: They then measure the extent to which the inclusion or exclusion of a particular training sample affects the generated explanations. This is done by comparing the explanations generated with and without the sample in question.
-
Influence Visualization: The results of the influence quantification are visualized to help identify the training samples that have the greatest impact on the explanations.
The framework is evaluated on several real-world datasets, including image classification and text classification tasks. The results show that the choice of training samples can significantly influence the generated explanations, with certain samples having a disproportionate impact.
The researchers also explore the relationship between model performance and explanation quality, finding that there is not always a direct correlation between the two. In some cases, improving model accuracy may come at the cost of less interpretable explanations.
Critical Analysis
The paper provides a valuable contribution to the field of AI interpretability and explainability, highlighting the important role that training data plays in shaping the explanations generated by machine learning models.
One potential limitation of the research is the reliance on existing explanation methods, such as LIME and SHAP, which have their own inherent biases and limitations. The authors acknowledge this and suggest that future work could explore the development of more robust and reliable explanation techniques.
Additionally, the paper focuses on the influence of individual training samples, but does not address the potential impact of broader dataset characteristics, such as distribution shifts or biases. Investigating these broader dataset-level influences could provide further insights into the relationship between training data and model explanations.
Overall, this research underscores the importance of carefully considering the training data used to build machine learning models, not just from the perspective of model performance, but also in terms of the transparency and interpretability of the resulting explanations. By understanding these relationships, developers can work towards creating AI systems that are more transparent and trustworthy.
Conclusion
This paper presents a framework for analyzing the influence of training samples on the explanations generated by machine learning models. The research highlights the important role that training data plays in shaping the transparency and interpretability of AI systems, and provides a valuable tool for developers and researchers to better understand and improve the quality of model explanations.
By exploring the connection between training data and explanations, this work contributes to the ongoing efforts to create more trustworthy and accountable AI systems that can be reliably used in high-stakes decision-making scenarios. The findings and techniques presented in this paper can serve as a foundation for future research and development in the field of AI interpretability and explainability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Privacy Implications of Explainable AI in Data-Driven Systems
Fatima Ezzeddine
0
0
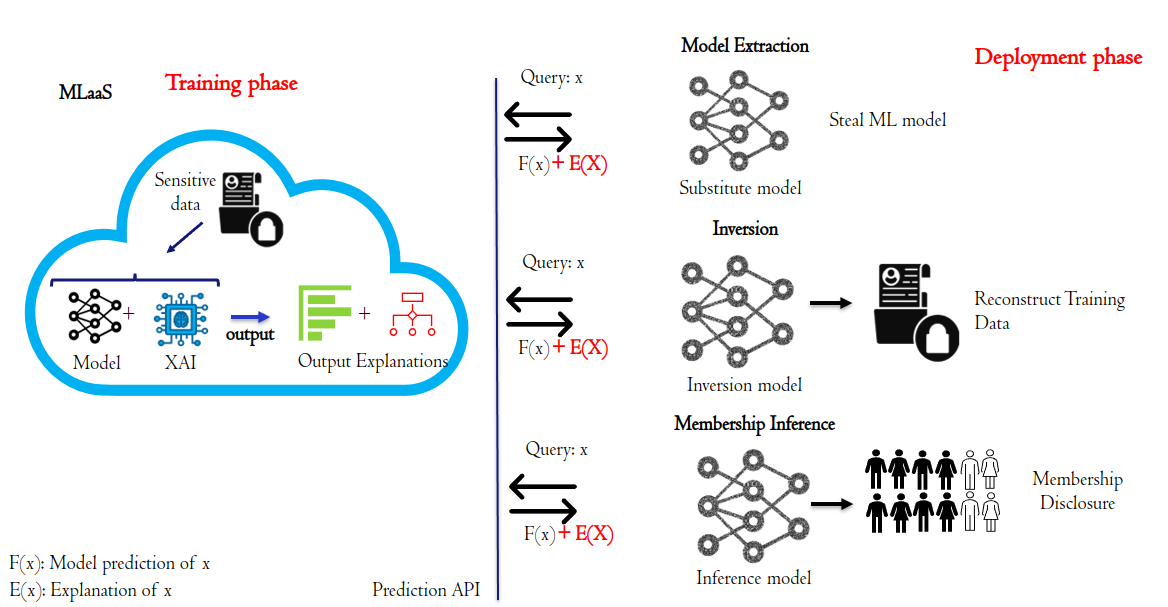
Machine learning (ML) models, demonstrably powerful, suffer from a lack of interpretability. The absence of transparency, often referred to as the black box nature of ML models, undermines trust and urges the need for efforts to enhance their explainability. Explainable AI (XAI) techniques address this challenge by providing frameworks and methods to explain the internal decision-making processes of these complex models. Techniques like Counterfactual Explanations (CF) and Feature Importance play a crucial role in achieving this goal. Furthermore, high-quality and diverse data remains the foundational element for robust and trustworthy ML applications. In many applications, the data used to train ML and XAI explainers contain sensitive information. In this context, numerous privacy-preserving techniques can be employed to safeguard sensitive information in the data, such as differential privacy. Subsequently, a conflict between XAI and privacy solutions emerges due to their opposing goals. Since XAI techniques provide reasoning for the model behavior, they reveal information relative to ML models, such as their decision boundaries, the values of features, or the gradients of deep learning models when explanations are exposed to a third entity. Attackers can initiate privacy breaching attacks using these explanations, to perform model extraction, inference, and membership attacks. This dilemma underscores the challenge of finding the right equilibrium between understanding ML decision-making and safeguarding privacy.
6/26/2024

Unified Explanations in Machine Learning Models: A Perturbation Approach
Jacob Dineen, Don Kridel, Daniel Dolk, David Castillo
0
0
A high-velocity paradigm shift towards Explainable Artificial Intelligence (XAI) has emerged in recent years. Highly complex Machine Learning (ML) models have flourished in many tasks of intelligence, and the questions have started to shift away from traditional metrics of validity towards something deeper: What is this model telling me about my data, and how is it arriving at these conclusions? Inconsistencies between XAI and modeling techniques can have the undesirable effect of casting doubt upon the efficacy of these explainability approaches. To address these problems, we propose a systematic, perturbation-based analysis against a popular, model-agnostic method in XAI, SHapley Additive exPlanations (Shap). We devise algorithms to generate relative feature importance in settings of dynamic inference amongst a suite of popular machine learning and deep learning methods, and metrics that allow us to quantify how well explanations generated under the static case hold. We propose a taxonomy for feature importance methodology, measure alignment, and observe quantifiable similarity amongst explanation models across several datasets.
5/31/2024
🗣️
Causality-Aware Local Interpretable Model-Agnostic Explanations
Martina Cinquini, Riccardo Guidotti
0
0
A main drawback of eXplainable Artificial Intelligence (XAI) approaches is the feature independence assumption, hindering the study of potential variable dependencies. This leads to approximating black box behaviors by analyzing the effects on randomly generated feature values that may rarely occur in the original samples. This paper addresses this issue by integrating causal knowledge in an XAI method to enhance transparency and enable users to assess the quality of the generated explanations. Specifically, we propose a novel extension to a widely used local and model-agnostic explainer, which encodes explicit causal relationships within the data surrounding the instance being explained. Extensive experiments show that our approach overcomes the original method in terms of faithfully replicating the black-box model's mechanism and the consistency and reliability of the generated explanations.
4/16/2024
📈
Model Interpretation and Explainability: Towards Creating Transparency in Prediction Models
Donald Kridel, Jacob Dineen, Daniel Dolk, David Castillo
0
0
Explainable AI (XAI) has a counterpart in analytical modeling which we refer to as model explainability. We tackle the issue of model explainability in the context of prediction models. We analyze a dataset of loans from a credit card company and apply three stages: execute and compare four different prediction methods, apply the best known explainability techniques in the current literature to the model training sets to identify feature importance (FI) (static case), and finally to cross-check whether the FI set holds up under what if prediction scenarios for continuous and categorical variables (dynamic case). We found inconsistency in FI identification between the static and dynamic cases. We summarize the state of the art in model explainability and suggest further research to advance the field.
6/3/2024