Enabling Language Models to Implicitly Learn Self-Improvement

1
💬
Sign in to get full access
Overview
- Large language models (LLMs) have made remarkable progress in open-ended text generation tasks.
- However, there is always room for improvement in the quality of model responses.
- Researchers have proposed various approaches to enhance the performance of LLMs, including enabling them to self-improve their response quality.
- Prompting-based methods have been widely explored for self-improvement, but they often require explicitly written rubrics as inputs.
- Deriving and providing all necessary rubrics for complex real-world goals (e.g., being more helpful and less harmful) can be expensive and challenging.
Plain English Explanation
Large language models (LLMs) have demonstrated impressive abilities in generating open-ended text, such as writing stories or answering questions. However, even the best LLMs can sometimes produce responses that aren't as high-quality as they could be. Researchers have been looking for ways to help LLMs improve themselves, so they can generate even better responses without needing a lot of additional human effort.
One approach that has been explored is prompting-based methods, where the LLM is given specific instructions or "prompts" to guide its self-improvement. But these prompts often require carefully crafted rubrics (sets of rules or criteria) that can be hard and time-consuming for humans to create, especially for complex real-world goals like "being more helpful and less harmful."
To address this challenge, the researchers propose a new framework called "ImPlicit Self-ImprovemenT" (PIT). Instead of relying on explicit prompts, PIT learns the improvement goal implicitly from human preference data. This means the LLM can learn to generate better responses by analyzing examples of responses that humans prefer, without needing detailed instructions on how to improve.
Technical Explanation
The key idea behind the PIT framework is to reformulate the training objective of reinforcement learning from human feedback (RLHF). Rather than simply maximizing the quality of a response for a given input, PIT aims to maximize the quality gap between the generated response and a reference response.
This means the LLM is incentivized to produce responses that are significantly better than a baseline or reference response, rather than just generating a high-quality response in isolation. By learning to outperform a reference, the LLM can implicitly learn the improvement goal from the human preference data used to train the reward model.
The researchers evaluated PIT on two real-world datasets and one synthetic dataset, and found that it significantly outperformed prompting-based methods for self-improvement. This suggests that the implicit learning approach of PIT can be an effective way to enable LLMs to enhance their response quality without the need for extensive human-provided rubrics.
Critical Analysis
The PIT framework presents a promising approach to enabling LLMs to self-improve their response quality. By learning the improvement goal implicitly from human preferences, it avoids the challenges of manually deriving and providing detailed rubrics, which can be time-consuming and difficult, especially for complex real-world objectives.
However, the paper does not address some potential limitations of the approach. For example, the quality of the self-improvement may be heavily dependent on the quality and diversity of the human preference data used to train the reward model. If the data is biased or lacks certain perspectives, the LLM's self-improvement may also be biased or limited.
Additionally, the paper does not explore the interpretability or transparency of the self-improvement process. It's unclear how the LLM determines what specific aspects of its responses to improve, and whether the improvements align with human values and ethical considerations.
Further research could investigate ways to make the self-improvement process more interpretable and aligned with human preferences, as well as exploring the robustness of the approach to different types of human preference data and real-world deployment scenarios.
Conclusion
The PIT framework proposed in this paper represents an important step towards enabling large language models to self-improve their response quality in an implicit, data-driven way. By learning the improvement goal from human preferences, rather than relying on explicitly defined rubrics, PIT can potentially reduce the burden of extensive human annotation efforts.
If further developed and refined, approaches like PIT could help unlock the full potential of large language models, allowing them to continuously enhance their capabilities and better serve human needs, while also addressing concerns about safety and alignment. As the field of language model research continues to evolve, this type of self-improvement capability could be a key factor in ensuring that these powerful AI systems become increasingly beneficial and trustworthy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
1
New!Enabling Language Models to Implicitly Learn Self-Improvement
Ziqi Wang, Le Hou, Tianjian Lu, Yuexin Wu, Yunxuan Li, Hongkun Yu, Heng Ji
Large Language Models (LLMs) have demonstrated remarkable capabilities in open-ended text generation tasks. However, the inherent open-ended nature of these tasks implies that there is always room for improvement in the quality of model responses. To address this challenge, various approaches have been proposed to enhance the performance of LLMs. There has been a growing focus on enabling LLMs to self-improve their response quality, thereby reducing the reliance on extensive human annotation efforts for collecting diverse and high-quality training data. Recently, prompting-based methods have been widely explored among self-improvement methods owing to their effectiveness, efficiency, and convenience. However, those methods usually require explicitly and thoroughly written rubrics as inputs to LLMs. It is expensive and challenging to manually derive and provide all necessary rubrics with a real-world complex goal for improvement (e.g., being more helpful and less harmful). To this end, we propose an ImPlicit Self-ImprovemenT (PIT) framework that implicitly learns the improvement goal from human preference data. PIT only requires preference data that are used to train reward models without extra human efforts. Specifically, we reformulate the training objective of reinforcement learning from human feedback (RLHF) -- instead of maximizing response quality for a given input, we maximize the quality gap of the response conditioned on a reference response. In this way, PIT is implicitly trained with the improvement goal of better aligning with human preferences. Experiments on two real-world datasets and one synthetic dataset show that our method significantly outperforms prompting-based methods.
Read more9/16/2024

470
Meta-Rewarding Language Models: Self-Improving Alignment with LLM-as-a-Meta-Judge
Tianhao Wu, Weizhe Yuan, Olga Golovneva, Jing Xu, Yuandong Tian, Jiantao Jiao, Jason Weston, Sainbayar Sukhbaatar
Large Language Models (LLMs) are rapidly surpassing human knowledge in many domains. While improving these models traditionally relies on costly human data, recent self-rewarding mechanisms (Yuan et al., 2024) have shown that LLMs can improve by judging their own responses instead of relying on human labelers. However, existing methods have primarily focused on improving model responses rather than judgment capabilities, resulting in rapid saturation during iterative training. To address this issue, we introduce a novel Meta-Rewarding step to the self-improvement process, where the model judges its own judgements and uses that feedback to refine its judgment skills. Surprisingly, this unsupervised approach improves the model's ability to judge {em and} follow instructions, as demonstrated by a win rate improvement of Llama-3-8B-Instruct from 22.9% to 39.4% on AlpacaEval 2, and 20.6% to 29.1% on Arena-Hard. These results strongly suggest the potential for self-improving models without human supervision.
Read more7/31/2024
0
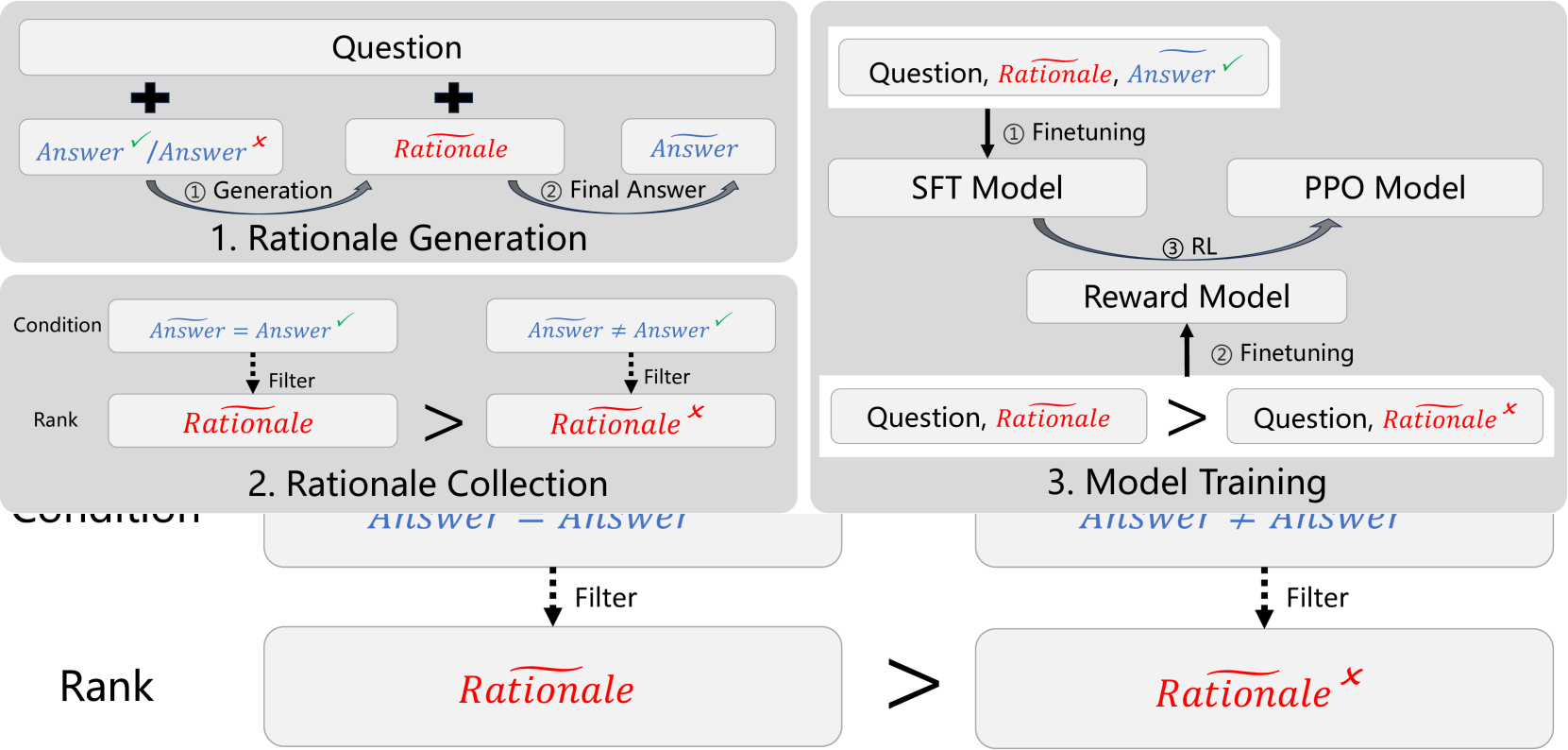
Improving Language Model Reasoning with Self-motivated Learning
Yunlong Feng, Yang Xu, Libo Qin, Yasheng Wang, Wanxiang Che
Large-scale high-quality training data is important for improving the performance of models. After trained with data that has rationales (reasoning steps), models gain reasoning capability. However, the dataset with high-quality rationales is relatively scarce due to the high annotation cost. To address this issue, we propose textit{Self-motivated Learning} framework. The framework motivates the model itself to automatically generate rationales on existing datasets. Based on the inherent rank from correctness across multiple rationales, the model learns to generate better rationales, leading to higher reasoning capability. Specifically, we train a reward model with the rank to evaluate the quality of rationales, and improve the performance of reasoning through reinforcement learning. Experiment results of Llama2 7B on multiple reasoning datasets show that our method significantly improves the reasoning ability of models, even outperforming text-davinci-002 in some datasets.
Read more5/1/2024
24
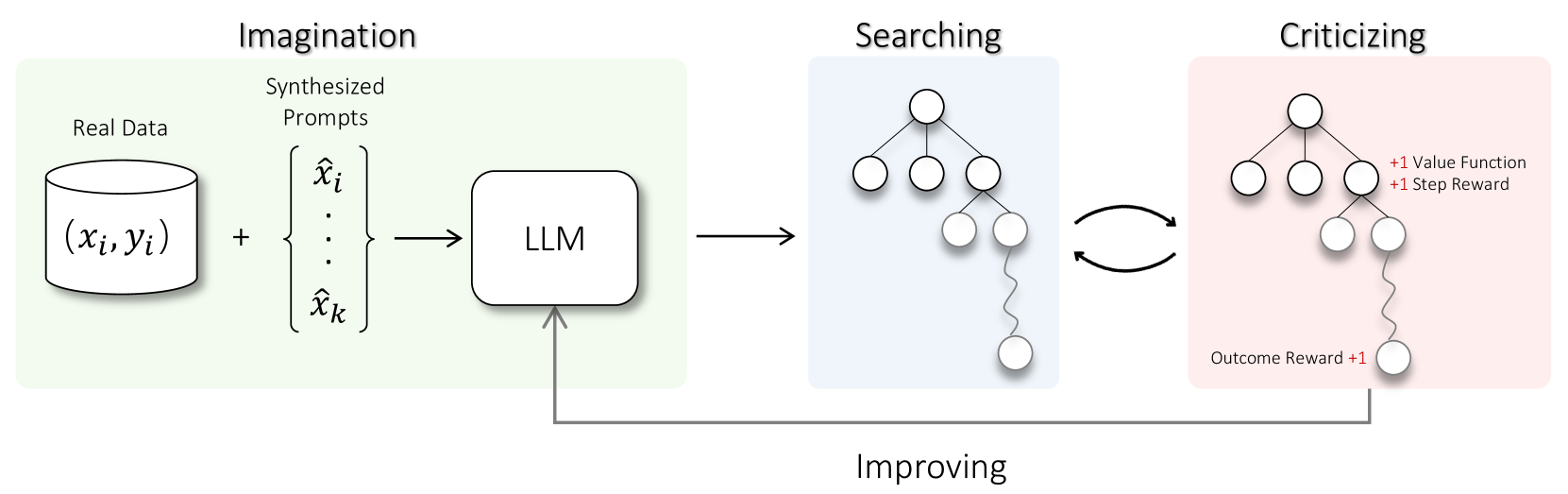
Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao Mi, Dong Yu
Despite the impressive capabilities of Large Language Models (LLMs) on various tasks, they still struggle with scenarios that involves complex reasoning and planning. Recent work proposed advanced prompting techniques and the necessity of fine-tuning with high-quality data to augment LLMs' reasoning abilities. However, these approaches are inherently constrained by data availability and quality. In light of this, self-correction and self-learning emerge as viable solutions, employing strategies that allow LLMs to refine their outputs and learn from self-assessed rewards. Yet, the efficacy of LLMs in self-refining its response, particularly in complex reasoning and planning task, remains dubious. In this paper, we introduce AlphaLLM for the self-improvements of LLMs, which integrates Monte Carlo Tree Search (MCTS) with LLMs to establish a self-improving loop, thereby enhancing the capabilities of LLMs without additional annotations. Drawing inspiration from the success of AlphaGo, AlphaLLM addresses the unique challenges of combining MCTS with LLM for self-improvement, including data scarcity, the vastness search spaces of language tasks, and the subjective nature of feedback in language tasks. AlphaLLM is comprised of prompt synthesis component, an efficient MCTS approach tailored for language tasks, and a trio of critic models for precise feedback. Our experimental results in mathematical reasoning tasks demonstrate that AlphaLLM significantly enhances the performance of LLMs without additional annotations, showing the potential for self-improvement in LLMs.
Read more4/19/2024