Enabling Regional Explainability by Automatic and Model-agnostic Rule Extraction
2406.17885
0
0

Abstract
In Explainable AI, rule extraction translates model knowledge into logical rules, such as IF-THEN statements, crucial for understanding patterns learned by black-box models. This could significantly aid in fields like disease diagnosis, disease progression estimation, or drug discovery. However, such application domains often contain imbalanced data, with the class of interest underrepresented. Existing methods inevitably compromise the performance of rules for the minor class to maximise the overall performance. As the first attempt in this field, we propose a model-agnostic approach for extracting rules from specific subgroups of data, featuring automatic rule generation for numerical features. This method enhances the regional explainability of machine learning models and offers wider applicability compared to existing methods. We additionally introduce a new method for selecting features to compose rules, reducing computational costs in high-dimensional spaces. Experiments across various datasets and models demonstrate the effectiveness of our methods.
Create account to get full access
Overview
- This paper introduces a new method for extracting explainable rules from machine learning models in an automatic and model-agnostic way.
- The proposed approach, called Automatic and Model-agnostic Rule Extraction (AMORE), aims to provide regional explainability by identifying important features and their interactions that contribute to a model's predictions.
- The method is designed to work with a variety of machine learning models, including black-box models, without requiring access to the model's internal structure or training process.
Plain English Explanation
Machine learning models are increasingly being used to make important decisions, but it can be challenging to understand how these models arrive at their predictions. Explainable AI (XAI) techniques aim to address this by providing insights into the inner workings of the models.
The AMORE method introduced in this paper is a new way to extract explainable rules from machine learning models. These rules describe the key factors and their interactions that influence the model's predictions. For example, a rule might be: "If the patient is over 65 and has a history of heart disease, then the model predicts a high risk of heart attack."
Unlike some existing XAI methods, AMORE works with any type of machine learning model, including complex "black-box" models whose inner workings are not easily understood. It does this by analyzing the model's inputs and outputs, without needing to know the details of how the model was trained or structured.
The ability to automatically extract these types of explanatory rules can help make machine learning models more transparent and trustworthy, which is important as they are increasingly used in high-stakes applications like healthcare and finance.
Technical Explanation
The AMORE method works by first identifying the most important features that contribute to the model's predictions. It does this using a technique called Causality-Aware Local Interpretable Model-Agnostic Explanations (LIME), which perturbs the input data and analyzes how the model's output changes.
Next, AMORE uses a rule induction algorithm to generate a set of rules that capture the key relationships between the important features and the model's predictions. This algorithm, called Automatic Extraction of Linguistic Descriptions from Fuzzy Rule-Based Systems (ADELFE), is designed to produce interpretable rules that can be easily understood by human users.
The authors evaluate AMORE on several benchmark datasets and demonstrate that it can extract compact and accurate rule sets that provide insights into the model's decision-making process. They also show that AMORE outperforms other state-of-the-art XAI methods in terms of both explanatory power and computational efficiency.
Critical Analysis
One potential limitation of the AMORE approach is that it relies on the LIME method to identify important features, which can be sensitive to the specific perturbations used. The authors acknowledge this and suggest that using alternative feature importance methods could be an area for future research.
Additionally, the paper does not extensively explore the impact of the extracted rules on end-users' understanding and trust of the machine learning models. Further user studies would be valuable to assess the practical benefits and usability of the AMORE approach in real-world applications.
While the authors demonstrate the effectiveness of AMORE on several datasets, it would be helpful to see how the method performs on a wider range of machine learning problems, including those with more complex feature interactions or non-linear relationships.
Conclusion
This paper presents a novel and promising approach for automatically extracting explainable rules from machine learning models in a model-agnostic way. The AMORE method has the potential to improve the transparency and interpretability of black-box models, which is crucial as they are increasingly used to make high-stakes decisions.
The ability to generate human-readable rules that describe the key factors influencing a model's predictions could help build trust and accountability in the use of AI systems. Further research and real-world deployment of the AMORE approach could lead to significant advancements in the field of explainable AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
Causality-Aware Local Interpretable Model-Agnostic Explanations
Martina Cinquini, Riccardo Guidotti
0
0
A main drawback of eXplainable Artificial Intelligence (XAI) approaches is the feature independence assumption, hindering the study of potential variable dependencies. This leads to approximating black box behaviors by analyzing the effects on randomly generated feature values that may rarely occur in the original samples. This paper addresses this issue by integrating causal knowledge in an XAI method to enhance transparency and enable users to assess the quality of the generated explanations. Specifically, we propose a novel extension to a widely used local and model-agnostic explainer, which encodes explicit causal relationships within the data surrounding the instance being explained. Extensive experiments show that our approach overcomes the original method in terms of faithfully replicating the black-box model's mechanism and the consistency and reliability of the generated explanations.
4/16/2024
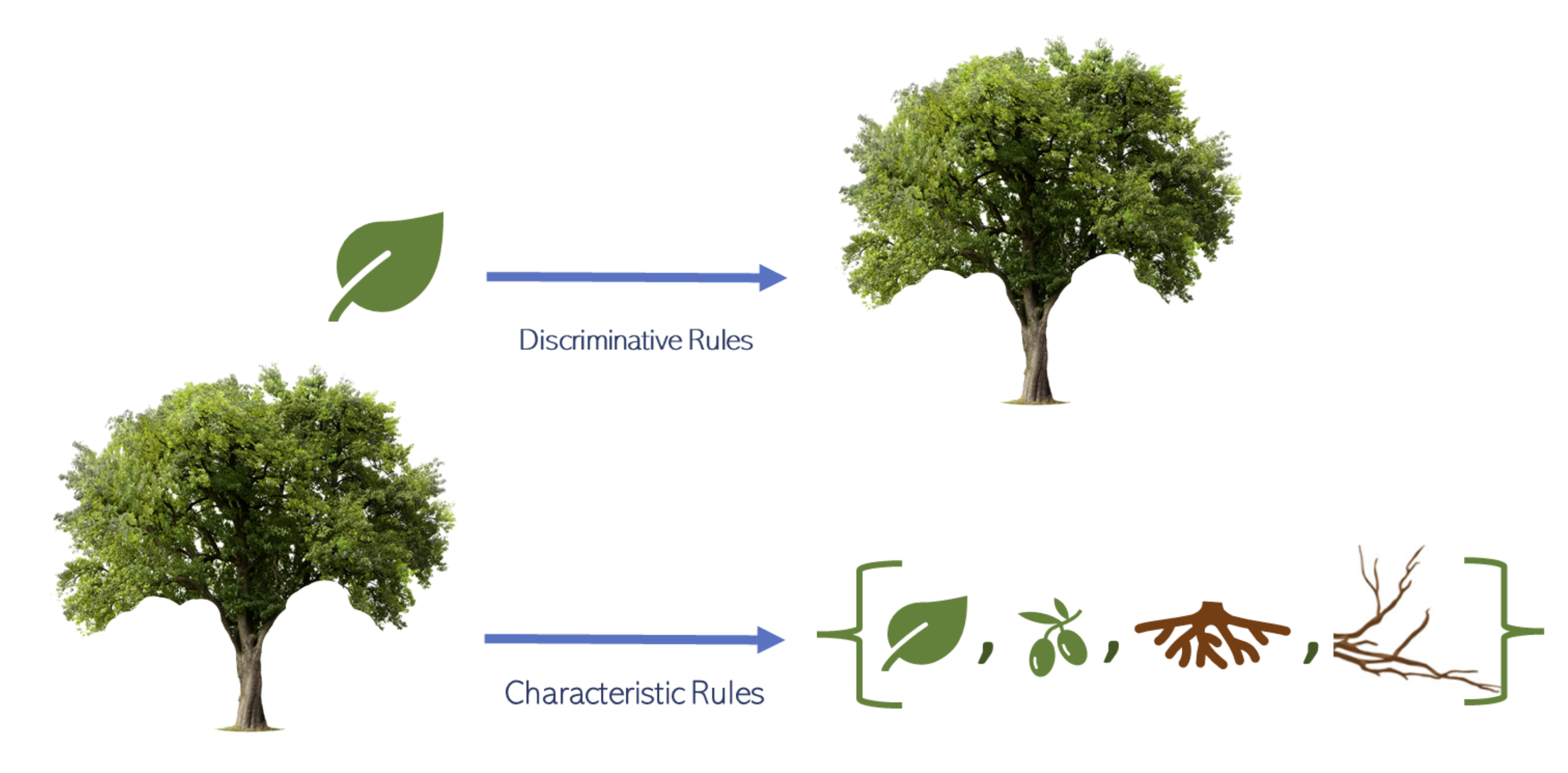
Explaining Predictions by Characteristic Rules
Amr Alkhatib, Henrik Bostrom, Michalis Vazirgiannis
0
0
Characteristic rules have been advocated for their ability to improve interpretability over discriminative rules within the area of rule learning. However, the former type of rule has not yet been used by techniques for explaining predictions. A novel explanation technique, called CEGA (Characteristic Explanatory General Association rules), is proposed, which employs association rule mining to aggregate multiple explanations generated by any standard local explanation technique into a set of characteristic rules. An empirical investigation is presented, in which CEGA is compared to two state-of-the-art methods, Anchors and GLocalX, for producing local and aggregated explanations in the form of discriminative rules. The results suggest that the proposed approach provides a better trade-off between fidelity and complexity compared to the two state-of-the-art approaches; CEGA and Anchors significantly outperform GLocalX with respect to fidelity, while CEGA and GLocalX significantly outperform Anchors with respect to the number of generated rules. The effect of changing the format of the explanations of CEGA to discriminative rules and using LIME and SHAP as local explanation techniques instead of Anchors are also investigated. The results show that the characteristic explanatory rules still compete favorably with rules in the standard discriminative format. The results also indicate that using CEGA in combination with either SHAP or Anchors consistently leads to a higher fidelity compared to using LIME as the local explanation technique.
6/3/2024
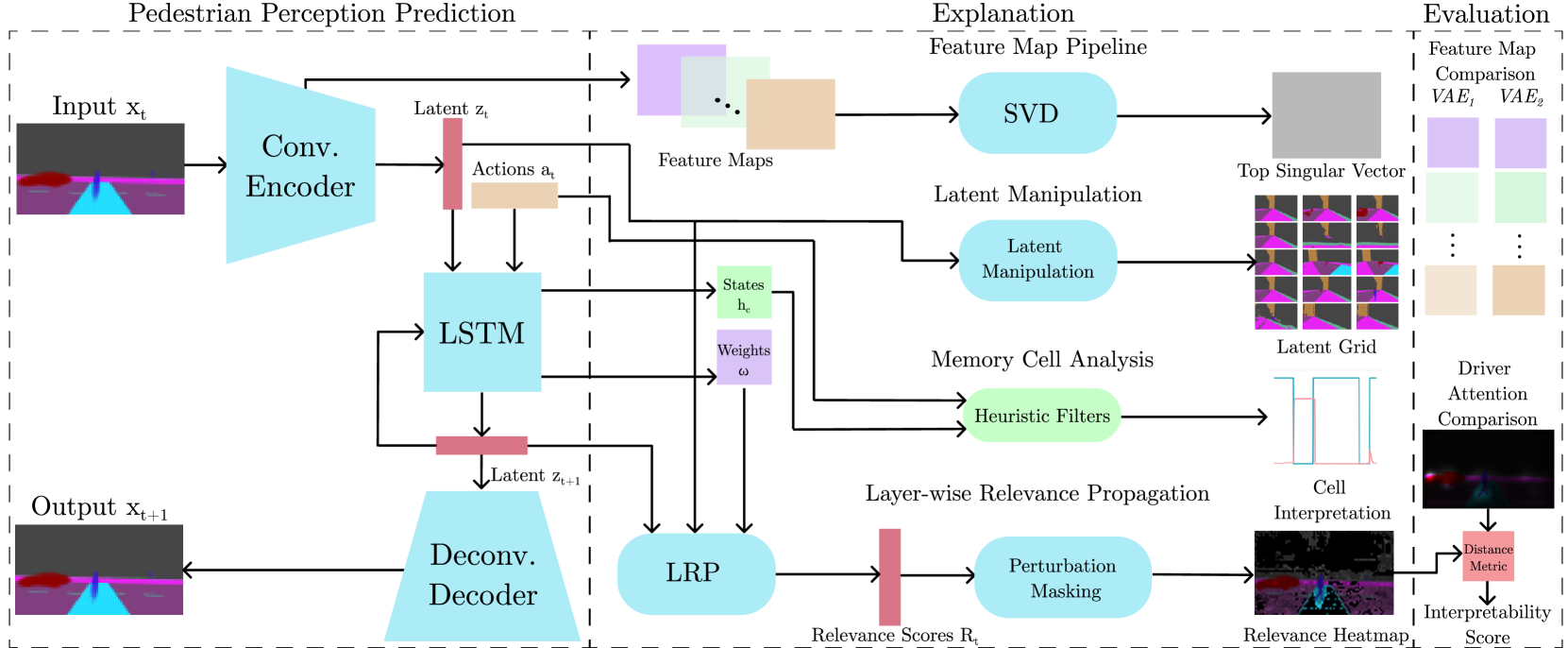
On the Road to Clarity: Exploring Explainable AI for World Models in a Driver Assistance System
Mohamed Roshdi, Julian Petzold, Mostafa Wahby, Hussein Ebrahim, Mladen Berekovic, Heiko Hamann
0
0
In Autonomous Driving (AD) transparency and safety are paramount, as mistakes are costly. However, neural networks used in AD systems are generally considered black boxes. As a countermeasure, we have methods of explainable AI (XAI), such as feature relevance estimation and dimensionality reduction. Coarse graining techniques can also help reduce dimensionality and find interpretable global patterns. A specific coarse graining method is Renormalization Groups from statistical physics. It has previously been applied to Restricted Boltzmann Machines (RBMs) to interpret unsupervised learning. We refine this technique by building a transparent backbone model for convolutional variational autoencoders (VAE) that allows mapping latent values to input features and has performance comparable to trained black box VAEs. Moreover, we propose a custom feature map visualization technique to analyze the internal convolutional layers in the VAE to explain internal causes of poor reconstruction that may lead to dangerous traffic scenarios in AD applications. In a second key contribution, we propose explanation and evaluation techniques for the internal dynamics and feature relevance of prediction networks. We test a long short-term memory (LSTM) network in the computer vision domain to evaluate the predictability and in future applications potentially safety of prediction models. We showcase our methods by analyzing a VAE-LSTM world model that predicts pedestrian perception in an urban traffic situation.
4/29/2024
🛸
Rule Generation for Classification: Scalability, Interpretability, and Fairness
Tabea E. Rober, Adia C. Lumadjeng, M. Hakan Akyuz, c{S}. .Ilker Birbil
0
0
We introduce a new rule-based optimization method for classification with constraints. The proposed method leverages column generation for linear programming, and hence, is scalable to large datasets. The resulting pricing subproblem is shown to be NP-Hard. We recourse to a decision tree-based heuristic and solve a proxy pricing subproblem for acceleration. The method returns a set of rules along with their optimal weights indicating the importance of each rule for learning. We address interpretability and fairness by assigning cost coefficients to the rules and introducing additional constraints. In particular, we focus on local interpretability and generalize separation criterion in fairness to multiple sensitive attributes and classes. We test the performance of the proposed methodology on a collection of datasets and present a case study to elaborate on its different aspects. The proposed rule-based learning method exhibits a good compromise between local interpretability and fairness on the one side, and accuracy on the other side.
5/14/2024