Explaining Predictions by Characteristic Rules

0
Sign in to get full access
Overview
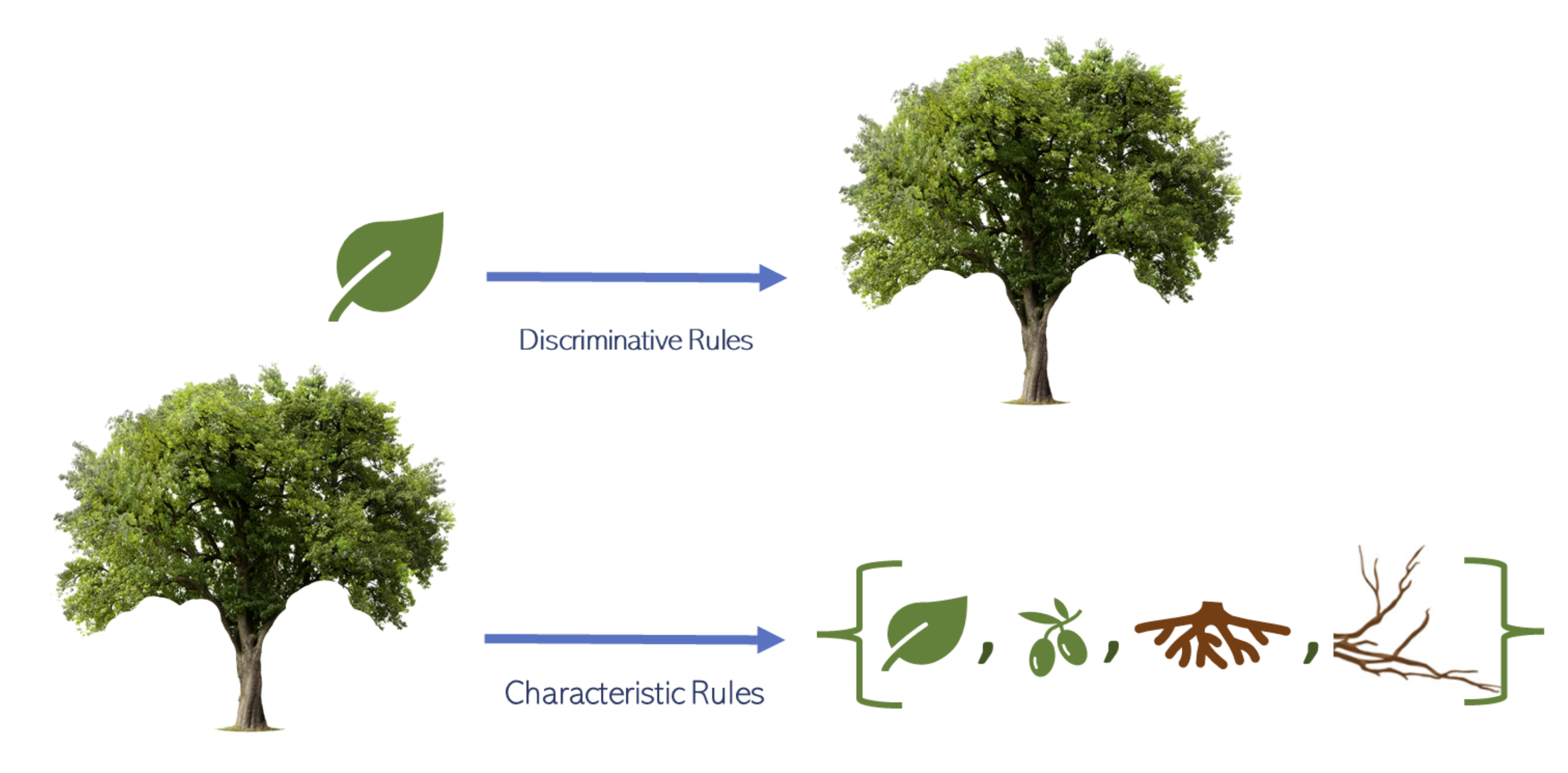
- This paper introduces a new method for explaining machine learning model predictions called "Explaining Predictions by Characteristic Rules."
- The method aims to generate human-interpretable rules that capture the key characteristics associated with a model's predictions.
- The paper compares the proposed method to other popular explainable AI techniques and demonstrates its effectiveness on several real-world datasets.
Plain English Explanation
When you use a machine learning model to make predictions, it's important to be able to explain how the model arrived at those predictions. This can help build trust in the model and ensure it is being used appropriately.
The researchers in this paper developed a new method for explaining machine learning model predictions. Their technique generates simple rules that capture the key characteristics associated with a model's predictions. For example, a rule might be "if the patient is over 65 and has high blood pressure, then the model predicts a high risk of heart attack."
These types of interpretable rules can be much easier for humans to understand than the complex mathematical models that power many machine learning systems. The researchers show that their method performs well compared to other popular explainable AI techniques, making it a promising approach for improving the transparency of black-box machine learning models.
By generating human-readable rules, this work aims to address a key challenge in making AI systems more interpretable and explainable. This can lead to increased trust in AI models and ensure they are being used responsibly.
Technical Explanation
The core of the proposed method is an algorithm that generates a set of "characteristic rules" to explain a machine learning model's predictions. These rules capture key patterns in the data that are predictive of the model's outputs.
The algorithm works by first identifying the most important features for the model's predictions. It then generates candidate rules that combine these features in different ways, evaluating each rule's coverage (how many instances it applies to) and fidelity (how well it matches the model's actual predictions).
The researchers test their method on several real-world datasets, comparing it to other popular explainable AI techniques like LIME and SHAP. They find that their characteristic rules are more human-interpretable while still providing accurate explanations of the model's behavior.
Critical Analysis
The paper provides a thoughtful approach to the challenge of model interpretability and transparency. By generating simple, human-readable rules, the method has the potential to make complex machine learning models more accessible and build greater trust in their predictions.
That said, the paper does not explore some important limitations of the technique. For example, the rules generated may not fully capture the nuance and context-dependence of the model's decision-making process. There are also open questions about how to handle cases where the model's predictions cannot be easily explained by a small set of rules.
Additionally, the paper focuses on post-hoc explanations of pre-trained models. An interesting direction for future work could be to integrate the rule generation process directly into the model training, potentially leading to more transparent and inherently interpretable models.
Overall, this paper represents a valuable contribution to the growing field of explainable artificial intelligence. While not a panacea, the characteristic rules approach is a promising technique for improving the interpretability of complex machine learning systems.
Conclusion
This paper introduces a new method for explaining the predictions of machine learning models using simple, human-interpretable rules. By identifying the key characteristics associated with a model's outputs, the technique can provide transparent and faithful explanations that build trust and ensure responsible use of AI systems.
While the paper demonstrates the effectiveness of the approach, it also highlights the need for continued research into making machine learning more interpretable and accountable. Integrating explainability directly into the model design, as well as handling the limitations of rule-based explanations, are important areas for future work.
Overall, this research represents an important step forward in the quest to make AI systems more transparent and aligned with human values. As machine learning becomes increasingly pervasive, techniques like this will be crucial for realizing the full potential of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Explaining Predictions by Characteristic Rules
Amr Alkhatib, Henrik Bostrom, Michalis Vazirgiannis
Characteristic rules have been advocated for their ability to improve interpretability over discriminative rules within the area of rule learning. However, the former type of rule has not yet been used by techniques for explaining predictions. A novel explanation technique, called CEGA (Characteristic Explanatory General Association rules), is proposed, which employs association rule mining to aggregate multiple explanations generated by any standard local explanation technique into a set of characteristic rules. An empirical investigation is presented, in which CEGA is compared to two state-of-the-art methods, Anchors and GLocalX, for producing local and aggregated explanations in the form of discriminative rules. The results suggest that the proposed approach provides a better trade-off between fidelity and complexity compared to the two state-of-the-art approaches; CEGA and Anchors significantly outperform GLocalX with respect to fidelity, while CEGA and GLocalX significantly outperform Anchors with respect to the number of generated rules. The effect of changing the format of the explanations of CEGA to discriminative rules and using LIME and SHAP as local explanation techniques instead of Anchors are also investigated. The results show that the characteristic explanatory rules still compete favorably with rules in the standard discriminative format. The results also indicate that using CEGA in combination with either SHAP or Anchors consistently leads to a higher fidelity compared to using LIME as the local explanation technique.
Read more6/3/2024

0
Enabling Regional Explainability by Automatic and Model-agnostic Rule Extraction
Yu Chen, Tianyu Cui, Alexander Capstick, Nan Fletcher-Loyd, Payam Barnaghi
In Explainable AI, rule extraction translates model knowledge into logical rules, such as IF-THEN statements, crucial for understanding patterns learned by black-box models. This could significantly aid in fields like disease diagnosis, disease progression estimation, or drug discovery. However, such application domains often contain imbalanced data, with the class of interest underrepresented. Existing methods inevitably compromise the performance of rules for the minor class to maximise the overall performance. As the first attempt in this field, we propose a model-agnostic approach for extracting rules from specific subgroups of data, featuring automatic rule generation for numerical features. This method enhances the regional explainability of machine learning models and offers wider applicability compared to existing methods. We additionally introduce a new method for selecting features to compose rules, reducing computational costs in high-dimensional spaces. Experiments across various datasets and models demonstrate the effectiveness of our methods.
Read more8/16/2024
🗣️
0
Causality-Aware Local Interpretable Model-Agnostic Explanations
Martina Cinquini, Riccardo Guidotti
A main drawback of eXplainable Artificial Intelligence (XAI) approaches is the feature independence assumption, hindering the study of potential variable dependencies. This leads to approximating black box behaviors by analyzing the effects on randomly generated feature values that may rarely occur in the original samples. This paper addresses this issue by integrating causal knowledge in an XAI method to enhance transparency and enable users to assess the quality of the generated explanations. Specifically, we propose a novel extension to a widely used local and model-agnostic explainer, which encodes explicit causal relationships within the data surrounding the instance being explained. Extensive experiments show that our approach overcomes the original method in terms of faithfully replicating the black-box model's mechanism and the consistency and reliability of the generated explanations.
Read more4/16/2024

0
An Evaluation of Explanation Methods for Black-Box Detectors of Machine-Generated Text
Loris Schoenegger, Yuxi Xia, Benjamin Roth
The increasing difficulty to distinguish language-model-generated from human-written text has led to the development of detectors of machine-generated text (MGT). However, in many contexts, a black-box prediction is not sufficient, it is equally important to know on what grounds a detector made that prediction. Explanation methods that estimate feature importance promise to provide indications of which parts of an input are used by classifiers for prediction. However, the quality of different explanation methods has not previously been assessed for detectors of MGT. This study conducts the first systematic evaluation of explanation quality for this task. The dimensions of faithfulness and stability are assessed with five automated experiments, and usefulness is evaluated in a user study. We use a dataset of ChatGPT-generated and human-written documents, and pair predictions of three existing language-model-based detectors with the corresponding SHAP, LIME, and Anchor explanations. We find that SHAP performs best in terms of faithfulness, stability, and in helping users to predict the detector's behavior. In contrast, LIME, perceived as most useful by users, scores the worst in terms of user performance at predicting the detectors' behavior.
Read more8/27/2024