Encourage or Inhibit Monosemanticity? Revisit Monosemanticity from a Feature Decorrelation Perspective

0
Sign in to get full access
Overview
- The paper explores the concept of monosemanticity, which refers to the idea that features in neural networks should have a single, well-defined meaning or interpretation.
- The authors revisit the topic of monosemanticity from a feature decorrelation perspective, investigating whether encouraging or inhibiting monosemanticity is more beneficial.
- The research examines the relationship between monosemanticity, feature decorrelation, and the performance of neural networks on various tasks.
Plain English Explanation
In machine learning, the concept of monosemanticity refers to the idea that the features in a neural network should have a single, well-defined meaning or interpretation. This is in contrast to polysemantic neurons, where a single neuron can represent multiple meanings.
The authors of this paper revisit the topic of monosemanticity, but from a different perspective - that of feature decorrelation. They investigate whether actively encouraging or inhibiting monosemanticity is more beneficial for the performance of neural networks on various tasks.
Feature decorrelation is the idea that the features in a neural network should be as independent from each other as possible, rather than being highly correlated. The researchers explore the relationship between monosemanticity, feature decorrelation, and how this impacts the network's ability to learn and generalize.
By taking this feature decorrelation approach, the authors hope to gain new insights into the role of monosemanticity in neural networks and whether it is something that should be actively promoted or avoided.
Technical Explanation
The paper examines the relationship between monosemanticity, feature decorrelation, and the performance of neural networks. The authors argue that the traditional view of monosemanticity as a desirable property may need to be revisited.
The researchers conducted experiments on various neural network architectures and tasks to investigate the impact of encouraging or inhibiting monosemanticity. They measured the degree of monosemanticity and feature decorrelation in the networks and assessed the corresponding task performance.
The results suggest that there is a complex interplay between monosemanticity, feature decorrelation, and network performance. In some cases, actively promoting monosemanticity may be beneficial, while in others, inhibiting monosemanticity and focusing on feature decorrelation may lead to better outcomes.
The authors also explore the potential mechanisms underlying these observations, such as the role of language-specific neurons and the trade-offs between prototypicality and nativelike selection in multilingual settings.
Critical Analysis
The paper presents a thought-provoking perspective on the role of monosemanticity in neural networks. The authors acknowledge that the relationship between monosemanticity, feature decorrelation, and network performance is complex and context-dependent.
One potential limitation of the study is the specific tasks and architectures used in the experiments. The findings may not generalize to all types of neural network models or problem domains. Additionally, the paper does not delve deeply into the cognitive and theoretical underpinnings of monosemanticity, which could provide further insights.
Further research is needed to fully understand the nuances of monosemanticity and its interplay with other network properties, such as interpretability, robustness, and transfer learning. Exploring the relationship between monosemanticity and domain-specific neuron interpretations could also be a fruitful direction for future work.
Conclusion
This paper challenges the traditional view of monosemanticity as a universally desirable property in neural networks. The authors demonstrate that the relationship between monosemanticity, feature decorrelation, and network performance is complex and context-dependent.
The findings suggest that a more nuanced approach to monosemanticity may be necessary, where the optimal balance between encouraging and inhibiting monosemanticity depends on the specific task, architecture, and desired network properties. This research opens up new avenues for exploring the role of interpretability and disentanglement in the design and optimization of neural networks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Encourage or Inhibit Monosemanticity? Revisit Monosemanticity from a Feature Decorrelation Perspective
Hanqi Yan, Yanzheng Xiang, Guangyi Chen, Yifei Wang, Lin Gui, Yulan He
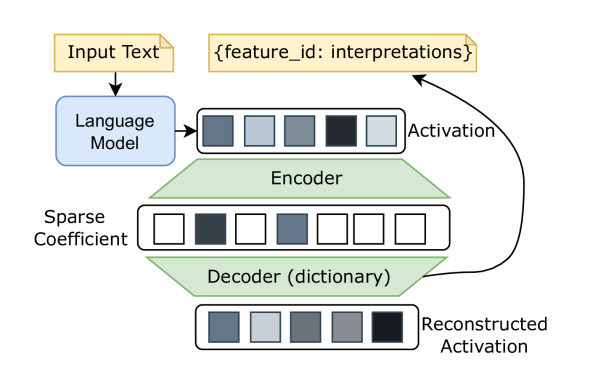
To better interpret the intrinsic mechanism of large language models (LLMs), recent studies focus on monosemanticity on its basic units. A monosemantic neuron is dedicated to a single and specific concept, which forms a one-to-one correlation between neurons and concepts. Despite extensive research in monosemanticity probing, it remains unclear whether monosemanticity is beneficial or harmful to model capacity. To explore this question, we revisit monosemanticity from the feature decorrelation perspective and advocate for its encouragement. We experimentally observe that the current conclusion by wang2024learning, which suggests that decreasing monosemanticity enhances model performance, does not hold when the model changes. Instead, we demonstrate that monosemanticity consistently exhibits a positive correlation with model capacity, in the preference alignment process. Consequently, we apply feature correlation as a proxy for monosemanticity and incorporate a feature decorrelation regularizer into the dynamic preference optimization process. The experiments show that our method not only enhances representation diversity and activation sparsity but also improves preference alignment performance.
Read more6/27/2024
0
Learning from Emergence: A Study on Proactively Inhibiting the Monosemantic Neurons of Artificial Neural Networks
Jiachuan Wang, Shimin Di, Lei Chen, Charles Wang Wai Ng
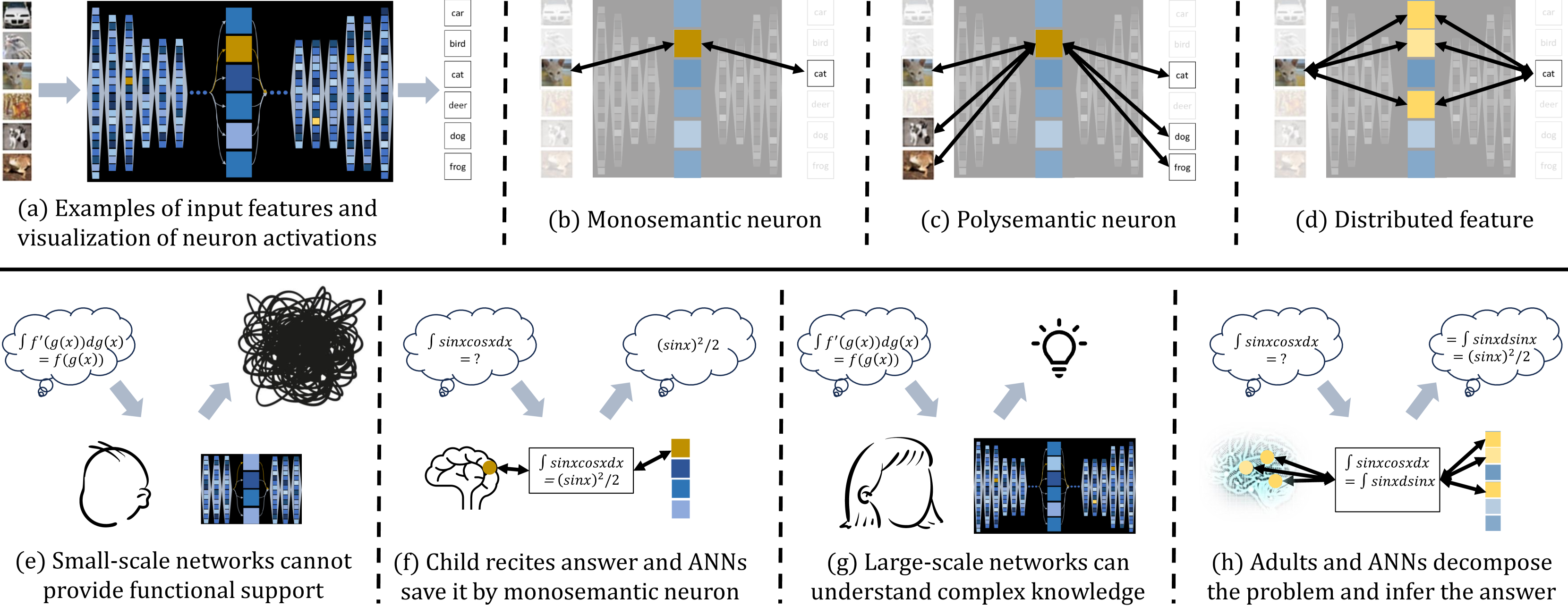
Recently, emergence has received widespread attention from the research community along with the success of large-scale models. Different from the literature, we hypothesize a key factor that promotes the performance during the increase of scale: the reduction of monosemantic neurons that can only form one-to-one correlations with specific features. Monosemantic neurons tend to be sparser and have negative impacts on the performance in large models. Inspired by this insight, we propose an intuitive idea to identify monosemantic neurons and inhibit them. However, achieving this goal is a non-trivial task as there is no unified quantitative evaluation metric and simply banning monosemantic neurons does not promote polysemanticity in neural networks. Therefore, we first propose a new metric to measure the monosemanticity of neurons with the guarantee of efficiency for online computation, then introduce a theoretically supported method to suppress monosemantic neurons and proactively promote the ratios of polysemantic neurons in training neural networks. We validate our conjecture that monosemanticity brings about performance change at different model scales on a variety of neural networks and benchmark datasets in different areas, including language, image, and physics simulation tasks. Further experiments validate our analysis and theory regarding the inhibition of monosemanticity.
Read more6/21/2024

0
PURE: Turning Polysemantic Neurons Into Pure Features by Identifying Relevant Circuits
Maximilian Dreyer, Erblina Purelku, Johanna Vielhaben, Wojciech Samek, Sebastian Lapuschkin
The field of mechanistic interpretability aims to study the role of individual neurons in Deep Neural Networks. Single neurons, however, have the capability to act polysemantically and encode for multiple (unrelated) features, which renders their interpretation difficult. We present a method for disentangling polysemanticity of any Deep Neural Network by decomposing a polysemantic neuron into multiple monosemantic virtual neurons. This is achieved by identifying the relevant sub-graph (circuit) for each pure feature. We demonstrate how our approach allows us to find and disentangle various polysemantic units of ResNet models trained on ImageNet. While evaluating feature visualizations using CLIP, our method effectively disentangles representations, improving upon methods based on neuron activations. Our code is available at https://github.com/maxdreyer/PURE.
Read more4/10/2024
0
Improving Multilingual Neural Machine Translation by Utilizing Semantic and Linguistic Features
Mengyu Bu, Shuhao Gu, Yang Feng
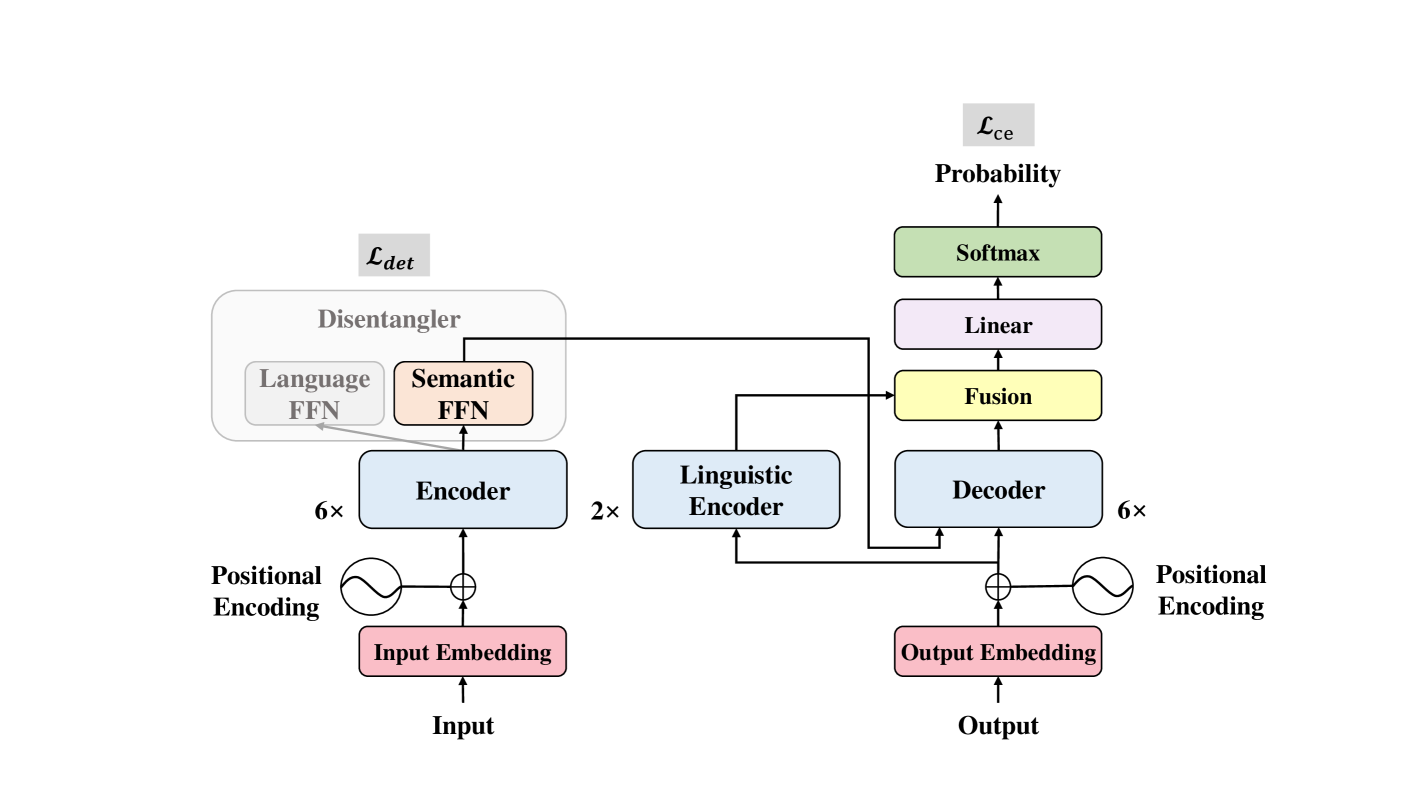
The many-to-many multilingual neural machine translation can be regarded as the process of integrating semantic features from the source sentences and linguistic features from the target sentences. To enhance zero-shot translation, models need to share knowledge across languages, which can be achieved through auxiliary tasks for learning a universal representation or cross-lingual mapping. To this end, we propose to exploit both semantic and linguistic features between multiple languages to enhance multilingual translation. On the encoder side, we introduce a disentangling learning task that aligns encoder representations by disentangling semantic and linguistic features, thus facilitating knowledge transfer while preserving complete information. On the decoder side, we leverage a linguistic encoder to integrate low-level linguistic features to assist in the target language generation. Experimental results on multilingual datasets demonstrate significant improvement in zero-shot translation compared to the baseline system, while maintaining performance in supervised translation. Further analysis validates the effectiveness of our method in leveraging both semantic and linguistic features. The code is available at https://github.com/ictnlp/SemLing-MNMT.
Read more8/6/2024