End-to-End User-Defined Keyword Spotting using Shifted Delta Coefficients

0

Sign in to get full access
Overview
- The paper presents an end-to-end user-defined keyword spotting system using shifted delta coefficients (SDCs) as the audio feature representation.
- The proposed architecture utilizes a mel spectrogram encoder, a cross-attention module, and a classifier to enable users to define arbitrary keywords for spotting.
- The system is designed to be robust and capable of handling diverse audio signals, including various speaking styles, accents, and background noises.
Plain English Explanation
The paper describes a new system for keyword spotting, which is the task of detecting specific words or phrases in audio recordings. This system is unique because it allows users to define their own keywords, rather than being limited to a predefined set.
The core idea is to use a mel spectrogram as the input representation for the audio, and then apply a cross-attention mechanism to match the user-defined keyword with the audio signal. This allows the system to be flexible and adapt to a wide range of audio conditions, such as different speaking styles, accents, and background noises.
The system is designed to be "end-to-end," meaning that it can take raw audio as input and directly output whether the keyword was detected or not, without requiring any additional processing steps. This makes it easy to deploy and use in real-world applications.
Technical Explanation
The proposed architecture consists of three main components:
-
Mel Spectrogram Encoder: This module takes the raw audio waveform as input and generates a mel spectrogram representation. The mel spectrogram is a compact, frequency-domain representation of the audio that preserves the most relevant information for speech recognition tasks.
-
Cross-Attention Module: The cross-attention module is the key innovation of this system. It takes the mel spectrogram and the user-defined keyword as inputs, and learns to automatically align the keyword with the relevant parts of the audio signal. This allows the system to focus on the most important regions of the audio for detecting the keyword, making it more robust to noise and variation.
-
Classifier: The final component is a neural network classifier that takes the output of the cross-attention module and produces a binary prediction of whether the keyword was detected or not.
The authors train and evaluate the system on a dataset of audio recordings with various keywords, speaking styles, and background conditions. They show that their approach outperforms several baseline methods, demonstrating the effectiveness of the shifted delta coefficient (SDC) feature representation and the cross-attention mechanism for user-defined keyword spotting.
Critical Analysis
The paper presents a compelling approach to user-defined keyword spotting, addressing a real-world need for flexible and robust keyword detection systems. The use of SDC features and the cross-attention mechanism appear to be well-designed and effective, as demonstrated by the experimental results.
However, the paper does not discuss the limitations or potential drawbacks of the proposed system. For example, it would be important to understand the computational and memory requirements of the model, as well as its performance on long-form audio or in real-time applications. Additionally, the authors could have explored the semantic distance metric learning approach to further improve the system's ability to handle diverse keywords and audio conditions.
Overall, the paper presents a strong technical contribution to the field of keyword spotting, but could benefit from a more thorough discussion of the system's limitations and potential areas for future research.
Conclusion
The paper introduces an end-to-end user-defined keyword spotting system that leverages shifted delta coefficients, mel spectrograms, and cross-attention to enable flexible and robust keyword detection. The proposed architecture outperforms several baseline methods, demonstrating the effectiveness of the key design choices.
While the technical details are well-explained, the paper could be strengthened by a more comprehensive discussion of the system's limitations and potential areas for future work. Nevertheless, this research represents a significant step forward in the development of advanced keyword spotting systems that can adapt to the needs of diverse users and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
End-to-End User-Defined Keyword Spotting using Shifted Delta Coefficients
Kesavaraj V, Anuprabha M, Anil Kumar Vuppala
Identifying user-defined keywords is crucial for personalizing interactions with smart devices. Previous approaches of user-defined keyword spotting (UDKWS) have relied on short-term spectral features such as mel frequency cepstral coefficients (MFCC) to detect the spoken keyword. However, these features may face challenges in accurately identifying closely related pronunciation of audio-text pairs, due to their limited capability in capturing the temporal dynamics of the speech signal. To address this challenge, we propose to use shifted delta coefficients (SDC) which help in capturing pronunciation variability (transition between connecting phonemes) by incorporating long-term temporal information. The performance of the SDC feature is compared with various baseline features across four different datasets using a cross-attention based end-to-end system. Additionally, various configurations of SDC are explored to find the suitable temporal context for the UDKWS task. The experimental results reveal that the SDC feature outperforms the MFCC baseline feature, exhibiting an improvement of 8.32% in area under the curve (AUC) and 8.69% in terms of equal error rate (EER) on the challenging Libriphrase-hard dataset. Moreover, the proposed approach demonstrated superior performance when compared to state-of-the-art UDKWS techniques.
Read more5/24/2024

0
Open vocabulary keyword spotting through transfer learning from speech synthesis
Kesavaraj V, Anil Kumar Vuppala
Identifying keywords in an open-vocabulary context is crucial for personalizing interactions with smart devices. Previous approaches to open vocabulary keyword spotting dependon a shared embedding space created by audio and text encoders. However, these approaches suffer from heterogeneous modality representations (i.e., audio-text mismatch). To address this issue, our proposed framework leverages knowledge acquired from a pre-trained text-to-speech (TTS) system. This knowledge transfer allows for the incorporation of awareness of audio projections into the text representations derived from the text encoder. The performance of the proposed approach is compared with various baseline methods across four different datasets. The robustness of our proposed model is evaluated by assessing its performance across different word lengths and in an Out-of-Vocabulary (OOV) scenario. Additionally, the effectiveness of transfer learning from the TTS system is investigated by analyzing its different intermediate representations. The experimental results indicate that, in the challenging LibriPhrase Hard dataset, the proposed approach outperformed the cross-modality correspondence detector (CMCD) method by a significant improvement of 8.22% in area under the curve (AUC) and 12.56% in equal error rate (EER).
Read more4/19/2024
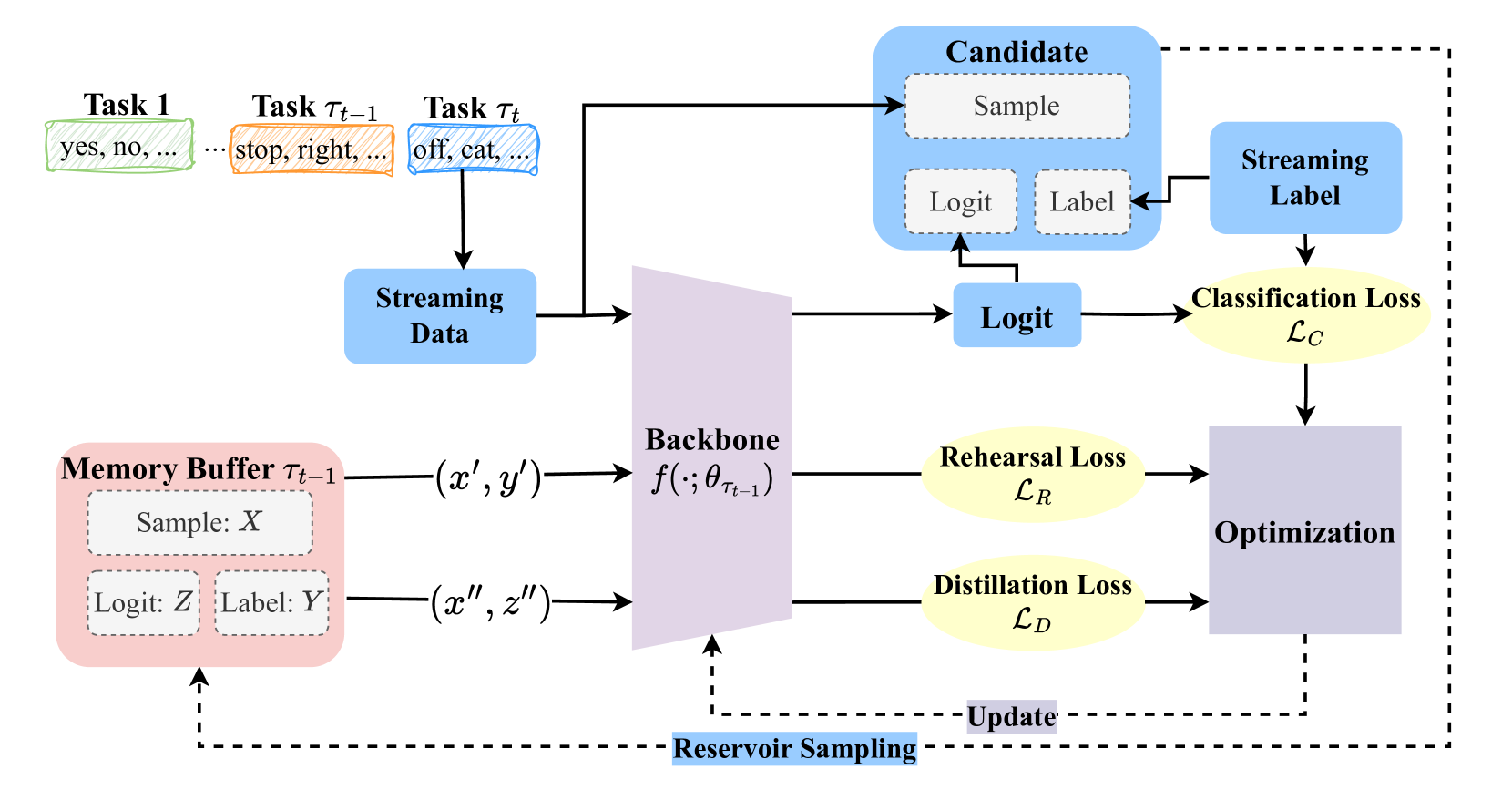
0
Dark Experience for Incremental Keyword Spotting
Tianyi Peng, Yang Xiao
Spoken keyword spotting (KWS) is crucial for identifying keywords within audio inputs and is widely used in applications like Apple Siri and Google Home, particularly on edge devices. Current deep learning-based KWS systems, which are typically trained on a limited set of keywords, can suffer from performance degradation when encountering new domains, a challenge often addressed through few-shot fine-tuning. However, this adaptation frequently leads to catastrophic forgetting, where the model's performance on original data deteriorates. Progressive continual learning (CL) strategies have been proposed to overcome this, but they face limitations such as the need for task-ID information and increased storage, making them less practical for lightweight devices. To address these challenges, we introduce Dark Experience for Keyword Spotting (DE-KWS), a novel CL approach that leverages dark knowledge to distill past experiences throughout the training process. DE-KWS combines rehearsal and distillation, using both ground truth labels and logits stored in a memory buffer to maintain model performance across tasks. Evaluations on the Google Speech Command dataset show that DE-KWS outperforms existing CL baselines in average accuracy without increasing model size, offering an effective solution for resource-constrained edge devices. The scripts are available on GitHub for the future research.
Read more9/16/2024

0
Multitaper mel-spectrograms for keyword spotting
Douglas Baptista de Souza, Khaled Jamal Bakri, Fernanda Ferreira, Juliana Inacio
Keyword spotting (KWS) is one of the speech recognition tasks most sensitive to the quality of the feature representation. However, the research on KWS has traditionally focused on new model topologies, putting little emphasis on other aspects like feature extraction. This paper investigates the use of the multitaper technique to create improved features for KWS. The experimental study is carried out for different test scenarios, windows and parameters, datasets, and neural networks commonly used in embedded KWS applications. Experiment results confirm the advantages of using the proposed improved features.
Read more7/8/2024