ENet-21: An Optimized light CNN Structure for Lane Detection

0

Sign in to get full access
Introduction
The paper discusses the application of computer vision techniques for lane detection in autonomous vehicles. Two primary methods for lane detection are discussed: classical algorithms and machine learning-based algorithms. Classical algorithms rely on handmade feature selection and are dependent on the quality of input images. Machine learning-based algorithms, particularly Convolutional Neural Networks (CNNs), can perform automatic feature extraction and provide a more robust solution against fluctuating elements and variable environments.
Recent studies have implemented end-to-end approaches using CNNs without any initial preprocessing. The Spatial Convolutional Neural Network (SCNN) is introduced to address performance degradation caused by obstacles blocking lane markings. Multi-task CNNs are proposed to detect multiple lanes in one image by performing both segmentation and embedding branches.
The main challenge with deep learning-based approaches is the computational cost associated with the complexity of CNN structures. This can be addressed by running the algorithm on suitable hardware or reducing the network's complexity.
The contributions of the study include:
- Presenting a light CNN backbone with fewer FLOPs and parameters while achieving similar performance to existing architectures.
- Using affinity fields for segmentation to effectively group and link pixels belonging to shapeless entities like lane markings.
- Demonstrating performance comparable to or surpassing leading techniques in the TuSimple benchmark dataset without complicated post-processing.
The study employs a machine learning-based method using CNN for feature extraction on the TuSimple dataset and proposes a light CNN structure for lane detection problems.
Related Works
The provided section reviews recent advancements in lane detection using deep learning methods. Lane detection aims to accurately identify and differentiate lane shapes. Current deep learning-based methods can be categorized based on their lane modeling approach, including semantic and instance segmentation, key point detection, gridding, polynomial, and anchor-based methods.
The paper discusses several specific methods:
- Focus on Local uses key point detection and local geometry construction to rectify key point pixel locations.
- PINet utilizes the Stacked Hourglass Network for key point detection and predicts offsets in x and y directions.
- CondLaneNet's CNN is based on conditional instance segmentation and row anchor formulation but struggles with recognizing start points in complex scenarios.
- SCNN treats lane detection as multiclass semantic segmentation and uses a spatial CNN module to aggregate spatial information, but it is not real-time due to low inference speed.
- LaneNet employs an instance segmentation pipeline to handle a variable number of lanes but requires post-inference clustering.
- Line-CNN is an end-to-end lane detector based on Faster R-CNN but struggles with real-time performance due to high latency.
- LaneATT introduces a novel anchor-based attention technique that aggregates global information, achieving good performance, adequacy, and efficiency.
The section highlights the challenges and limitations of various methods, such as handling complex scenarios, real-time performance, and the need for post-processing steps.
Methodology
The paper presents a new methodology for lane marker detection using an end-to-end convolutional neural network (CNN). The approach treats lane prediction as a segmentation problem, training the model to predict semantic segmentation labels and pixel-wise affinity fields. These affinity fields are divided into horizontal (HAF) and vertical (VAF) components, which map 2D locations of the input image into 2D unit vectors. The VAF encodes lane pixel vector direction toward the next lane pixels in the above row, while the HAF points toward the center pixel of the lane in the current row. In a postprocessing step, the VAF, HAF, and semantic lane segmentation enable lane generation through foreground pixel clustering. The main focus is on developing a lighter CNN architecture, called the backbone, that maintains proper performance. The proposed architecture for binary segmentation and affinity fields, along with its training and inference procedure, will be discussed in the following subsections.
The paper proposes a lane detection model using an efficient neural network architecture called ENet as the backbone. The model predicts both a binary segmentation mask and affinity fields to cluster lane pixels horizontally and vertically.
The ENet architecture is divided into encoder and decoder stages, with bottleneck blocks containing projection, main, and expansion convolutional layers. Batch normalization and PReLU activation are used after each convolutional layer. The model has fewer parameters than other popular architectures like ResNet and ERFNet.
The affinity fields, consisting of a horizontal affinity field (HAF) and vertical affinity field (VAF), are generated using ground truth masks. The HAF assigns unit vectors pointing to the center of each lane in a row, while the VAF assigns unit vectors pointing to the center of each lane in the previous row. During testing, a decoding process clusters foreground pixels into lanes using the predicted affinity fields.
The model is trained using a loss function that combines weighted binary cross-entropy loss for semantic segmentation, intersection over union loss to handle the imbalanced dataset, and L1 regression loss for the affinity field heads. The general loss function is the sum of these individual losses.
Experimental Results
The paper evaluates a lane detection approach using the TuSimple dataset, which contains 6408 annotated highway images. The evaluation metrics used are accuracy (percentage of correctly predicted lane vertices), false positive rate, false negative rate, and F1-score.
The proposed method resizes input images to 640x352 and generates lane marker masks based on JSON labels. It uses an Adam optimizer with a learning rate of 0.0005, mini-batches of 8 images per GPU, and applies techniques like dropout, early stopping, and data augmentation to reduce overfitting.
Compared to state-of-the-art methods, the proposed architecture achieves competitive results on the TuSimple dataset, with a notable F1-score and low false positive rate. The model is lightweight, with only 0.25 million parameters and 3.14G FLOPs, making it faster than commonly used models while maintaining similar accuracy.
Ablation experiments were performed to validate configuration choices, investigating the impact of hyper-parameters, layer configurations, and noise types. The optimized architecture balances performance and efficiency for lane detection tasks.
Conclusion
The study introduces a new CNN architecture for end-to-end lane detection that uses semantic segmentation and affinity fields. The method employs binary segmentation outputs and affinity fields to perform instance segmentation of lane pixels, enabling the detection of varying numbers of lanes in post-processing. The proposed architecture has fewer parameters than most other models and outperforms them, achieving a low false positive rate on the TuSimple dataset. The model also has the lowest computational complexity, including FLOPs and number of parameters, among existing models. The work offers a promising solution for lane detection in autonomous driving applications.
The authors declare that they received no financial support during the preparation of the manuscript.
ompliance with ethical standards
The authors, Seyed Rasoul Hosseini and Mohammad Teshnehlab, state they have no conflicts of interest related to the study. No experiments involving humans or animals were conducted. The study obtained informed consent from all participants.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ENet-21: An Optimized light CNN Structure for Lane Detection
Seyed Rasoul Hosseini, Hamid Taheri, Mohammad Teshnehlab
Lane detection for autonomous vehicles is an important concept, yet it is a challenging issue of driver assistance systems in modern vehicles. The emergence of deep learning leads to significant progress in self-driving cars. Conventional deep learning-based methods handle lane detection problems as a binary segmentation task and determine whether a pixel belongs to a line. These methods rely on the assumption of a fixed number of lanes, which does not always work. This study aims to develop an optimal structure for the lane detection problem, offering a promising solution for driver assistance features in modern vehicles by utilizing a machine learning method consisting of binary segmentation and Affinity Fields that can manage varying numbers of lanes and lane change scenarios. In this approach, the Convolutional Neural Network (CNN), is selected as a feature extractor, and the final output is obtained through clustering of the semantic segmentation and Affinity Field outputs. Our method uses less complex CNN architecture than existing ones. Experiments on the TuSimple dataset support the effectiveness of the proposed method.
Read more8/9/2024
0
LaneSegNet Design Study
William Stevens, Vishal Urs, Karthik Selvaraj, Gabriel Torres, Gaurish Lakhanpal
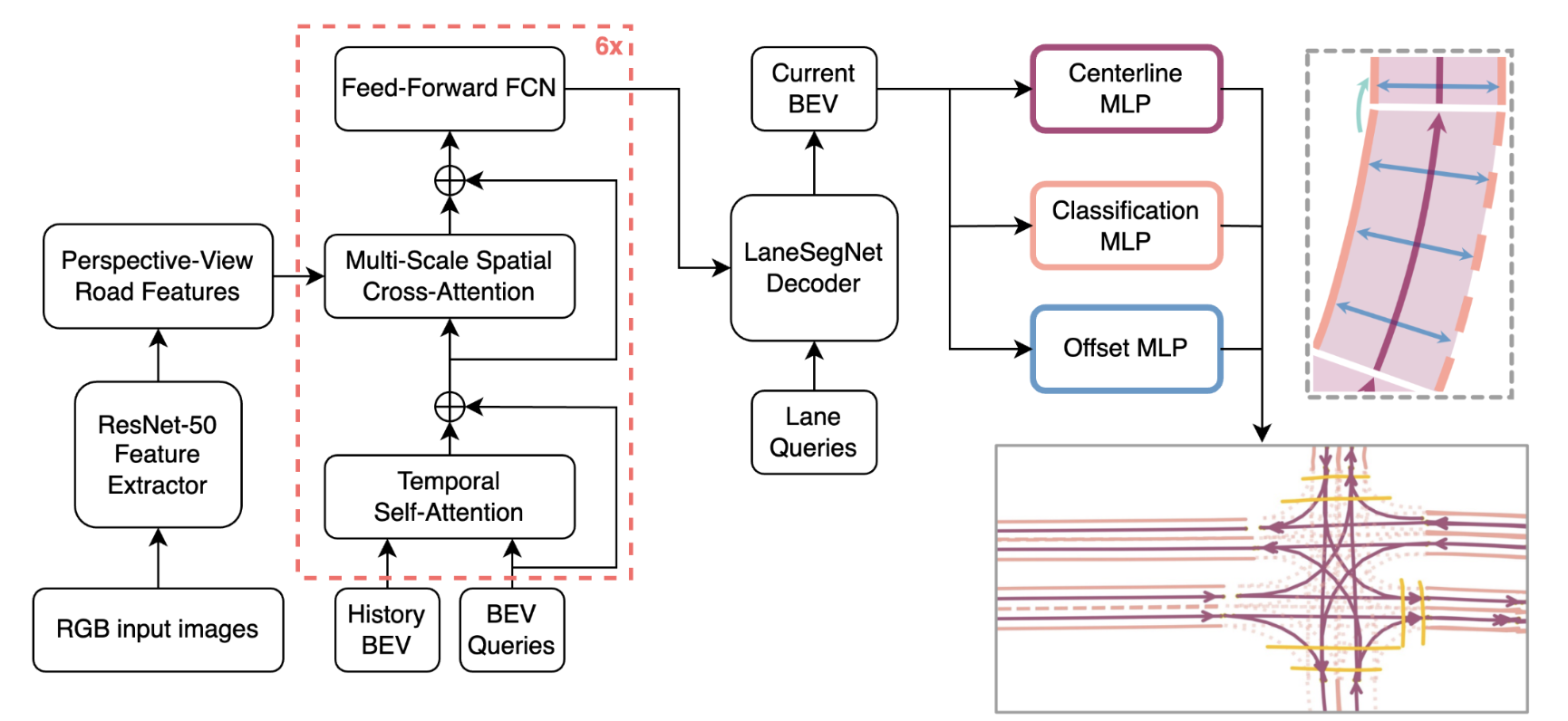
With the increasing prevalence of autonomous vehicles, it is essential for computer vision algorithms to accurately assess road features in real-time. This study explores the LaneSegNet architecture, a new approach to lane topology prediction which integrates topological information with lane-line data to provide a more contextual understanding of road environments. The LaneSegNet architecture includes a feature extractor, lane encoder, lane decoder, and prediction head, leveraging components from ResNet-50, BEVFormer, and various attention mechanisms. We experimented with optimizations to the LaneSegNet architecture through feature extractor modification and transformer encoder-decoder stack modification. We found that modifying the encoder and decoder stacks offered an interesting tradeoff between training time and prediction accuracy, with certain combinations showing promising results. Our implementation, trained on a single NVIDIA Tesla A100 GPU, found that a 2:4 ratio reduced training time by 22.3% with only a 7.1% drop in mean average precision, while a 4:8 ratio increased training time by only 11.1% but improved mean average precision by a significant 23.7%. These results indicate that strategic hyperparameter tuning can yield substantial improvements depending on the resources of the user. This study provides valuable insights for optimizing LaneSegNet according to available computation power, making it more accessible for users with limited resources and increasing the capabilities for users with more powerful resources.
Read more8/1/2024
0
New!Cross Dataset Analysis and Network Architecture Repair for Autonomous Car Lane Detection
Parth Ganeriwala, Siddhartha Bhattacharyya, Raja Muthalagu
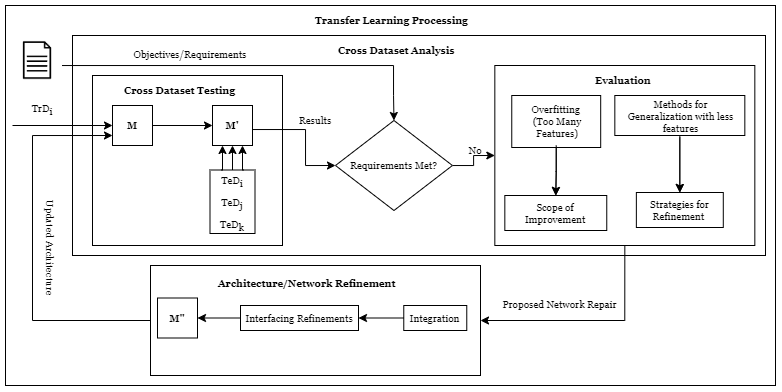
Transfer Learning has become one of the standard methods to solve problems to overcome the isolated learning paradigm by utilizing knowledge acquired for one task to solve another related one. However, research needs to be done, to identify the initial steps before inducing transfer learning to applications for further verification and explainablity. In this research, we have performed cross dataset analysis and network architecture repair for the lane detection application in autonomous vehicles. Lane detection is an important aspect of autonomous vehicles driving assistance system. In most circumstances, modern deep-learning-based lane recognition systems are successful, but they struggle with lanes with complex topologies. The proposed architecture, ERFCondLaneNet is an enhancement to the CondlaneNet used for lane identification framework to solve the difficulty of detecting lane lines with complex topologies like dense, curved and fork lines. The newly proposed technique was tested on two common lane detecting benchmarks, CULane and CurveLanes respectively, and two different backbones, ResNet and ERFNet. The researched technique with ERFCondLaneNet, exhibited similar performance in comparison to ResnetCondLaneNet, while using 33% less features, resulting in a reduction of model size by 46%.
Read more9/27/2024

0
FENet: Focusing Enhanced Network for Lane Detection
Liman Wang, Hanyang Zhong
Inspired by human driving focus, this research pioneers networks augmented with Focusing Sampling, Partial Field of View Evaluation, Enhanced FPN architecture and Directional IoU Loss - targeted innovations addressing obstacles to precise lane detection for autonomous driving. Experiments demonstrate our Focusing Sampling strategy, emphasizing vital distant details unlike uniform approaches, significantly boosts both benchmark and practical curved/distant lane recognition accuracy essential for safety. While FENetV1 achieves state-of-the-art conventional metric performance via enhancements isolating perspective-aware contexts mimicking driver vision, FENetV2 proves most reliable on the proposed Partial Field analysis. Hence we specifically recommend V2 for practical lane navigation despite fractional degradation on standard entire-image measures. Future directions include collecting on-road data and integrating complementary dual frameworks to further breakthroughs guided by human perception principles. The Code is available at https://github.com/HanyangZhong/FENet.
Read more4/29/2024