FENet: Focusing Enhanced Network for Lane Detection

0

Sign in to get full access
Overview
- This paper presents FENet, a Focusing Enhanced Network for lane detection in autonomous driving applications.
- FENet introduces a novel "Focusing Sampling" mechanism to concentrate the network's attention on relevant regions of the input image, improving lane detection accuracy.
- The paper also proposes a "Focusing Enhanced Encoder-Decoder" architecture that leverages the Focusing Sampling module to enhance feature extraction and reconstruction.
- Experiments on popular lane detection benchmarks demonstrate that FENet outperforms state-of-the-art lane detection models in terms of accuracy and efficiency.
Plain English Explanation
The goal of this research is to improve the performance of lane detection systems used in self-driving cars. Lane detection is a crucial component of autonomous driving, as it allows the vehicle to stay centered in its lane and navigate the road safely.
The researchers developed a neural network called FENet that is specifically designed for lane detection tasks. The key innovation in FENet is a "Focusing Sampling" mechanism, which helps the network focus its attention on the most relevant regions of the input image. This allows FENet to more accurately identify and segment the lane markings, rather than getting distracted by irrelevant parts of the scene.
Additionally, FENet uses a specialized "Focusing Enhanced Encoder-Decoder" architecture that further leverages the Focusing Sampling module to extract and reconstruct features more effectively. This results in improved lane detection accuracy and efficiency compared to other state-of-the-art models.
The researchers evaluated FENet on popular lane detection benchmarks and showed that it outperforms existing approaches. This suggests that the Focusing Sampling and Focusing Enhanced Encoder-Decoder techniques developed in this paper could be valuable contributions to the field of autonomous driving and computer vision more broadly.
Technical Explanation
The paper proposes a novel "Focusing Enhanced Network" (FENet) for lane detection in autonomous driving applications. The key innovation is a "Focusing Sampling" mechanism that helps the network concentrate its attention on the most relevant regions of the input image.
The Focusing Sampling module is integrated into a "Focusing Enhanced Encoder-Decoder" architecture, which leverages the focused features to improve both the encoding and decoding stages of the lane detection pipeline. This allows FENet to more accurately identify and segment the lane markings compared to existing approaches.
The paper also introduces several other technical contributions, including:
- A multi-task learning framework that jointly optimizes lane detection and segmentation tasks to improve overall performance.
- A novel loss function that combines lane geometry and pixel-wise loss terms to better capture the structure of lane markings.
- An efficient network design with a lightweight backbone and carefully-tuned hyperparameters to enable real-time inference on embedded platforms.
The researchers evaluate FENet on popular lane detection benchmarks, such as CULane, Tusimple, and BDD100K. The results demonstrate that FENet outperforms state-of-the-art lane detection models in terms of both accuracy and efficiency, making it a promising candidate for deployment in real-world autonomous driving systems.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach to lane detection, addressing several key challenges in the field. The Focusing Sampling mechanism and Focusing Enhanced Encoder-Decoder architecture are novel and appear to be effective contributions.
However, the paper does not provide a deep analysis of the limitations or failure cases of FENet. It would be valuable to understand the scenarios where the model struggles, such as in poor lighting conditions, adverse weather, or complex road layouts. Additionally, the paper could have explored the transferability of the Focusing Sampling technique to other computer vision tasks beyond lane detection.
Further research could also investigate the interpretability of the Focusing Sampling mechanism, as understanding how the network determines the most relevant regions could lead to additional insights and improvements. Lastly, a more comprehensive comparison to a broader range of state-of-the-art lane detection models, including ElasticLaneNet and FisheyeDetNet, could strengthen the claims of FENet's superiority.
Overall, the paper presents a promising approach to lane detection that could have significant practical implications for the development of safer and more reliable autonomous driving systems.
Conclusion
The FENet paper introduces a novel Focusing Enhanced Network for lane detection in autonomous driving applications. The key contributions are a Focusing Sampling mechanism and a Focusing Enhanced Encoder-Decoder architecture, which together allow the network to concentrate its attention on the most relevant regions of the input image, leading to improved lane detection accuracy and efficiency.
The experimental results demonstrate that FENet outperforms state-of-the-art lane detection models on popular benchmarks, suggesting that the techniques developed in this work could be valuable for advancing the state of the art in autonomous driving and computer vision more broadly. While the paper could have provided deeper analysis of the model's limitations and explored further applications of the Focusing Sampling approach, it nonetheless presents an important step forward in the quest for reliable and safe self-driving car technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FENet: Focusing Enhanced Network for Lane Detection
Liman Wang, Hanyang Zhong
Inspired by human driving focus, this research pioneers networks augmented with Focusing Sampling, Partial Field of View Evaluation, Enhanced FPN architecture and Directional IoU Loss - targeted innovations addressing obstacles to precise lane detection for autonomous driving. Experiments demonstrate our Focusing Sampling strategy, emphasizing vital distant details unlike uniform approaches, significantly boosts both benchmark and practical curved/distant lane recognition accuracy essential for safety. While FENetV1 achieves state-of-the-art conventional metric performance via enhancements isolating perspective-aware contexts mimicking driver vision, FENetV2 proves most reliable on the proposed Partial Field analysis. Hence we specifically recommend V2 for practical lane navigation despite fractional degradation on standard entire-image measures. Future directions include collecting on-road data and integrating complementary dual frameworks to further breakthroughs guided by human perception principles. The Code is available at https://github.com/HanyangZhong/FENet.
Read more4/29/2024

0
ENet-21: An Optimized light CNN Structure for Lane Detection
Seyed Rasoul Hosseini, Hamid Taheri, Mohammad Teshnehlab
Lane detection for autonomous vehicles is an important concept, yet it is a challenging issue of driver assistance systems in modern vehicles. The emergence of deep learning leads to significant progress in self-driving cars. Conventional deep learning-based methods handle lane detection problems as a binary segmentation task and determine whether a pixel belongs to a line. These methods rely on the assumption of a fixed number of lanes, which does not always work. This study aims to develop an optimal structure for the lane detection problem, offering a promising solution for driver assistance features in modern vehicles by utilizing a machine learning method consisting of binary segmentation and Affinity Fields that can manage varying numbers of lanes and lane change scenarios. In this approach, the Convolutional Neural Network (CNN), is selected as a feature extractor, and the final output is obtained through clustering of the semantic segmentation and Affinity Field outputs. Our method uses less complex CNN architecture than existing ones. Experiments on the TuSimple dataset support the effectiveness of the proposed method.
Read more8/9/2024
0
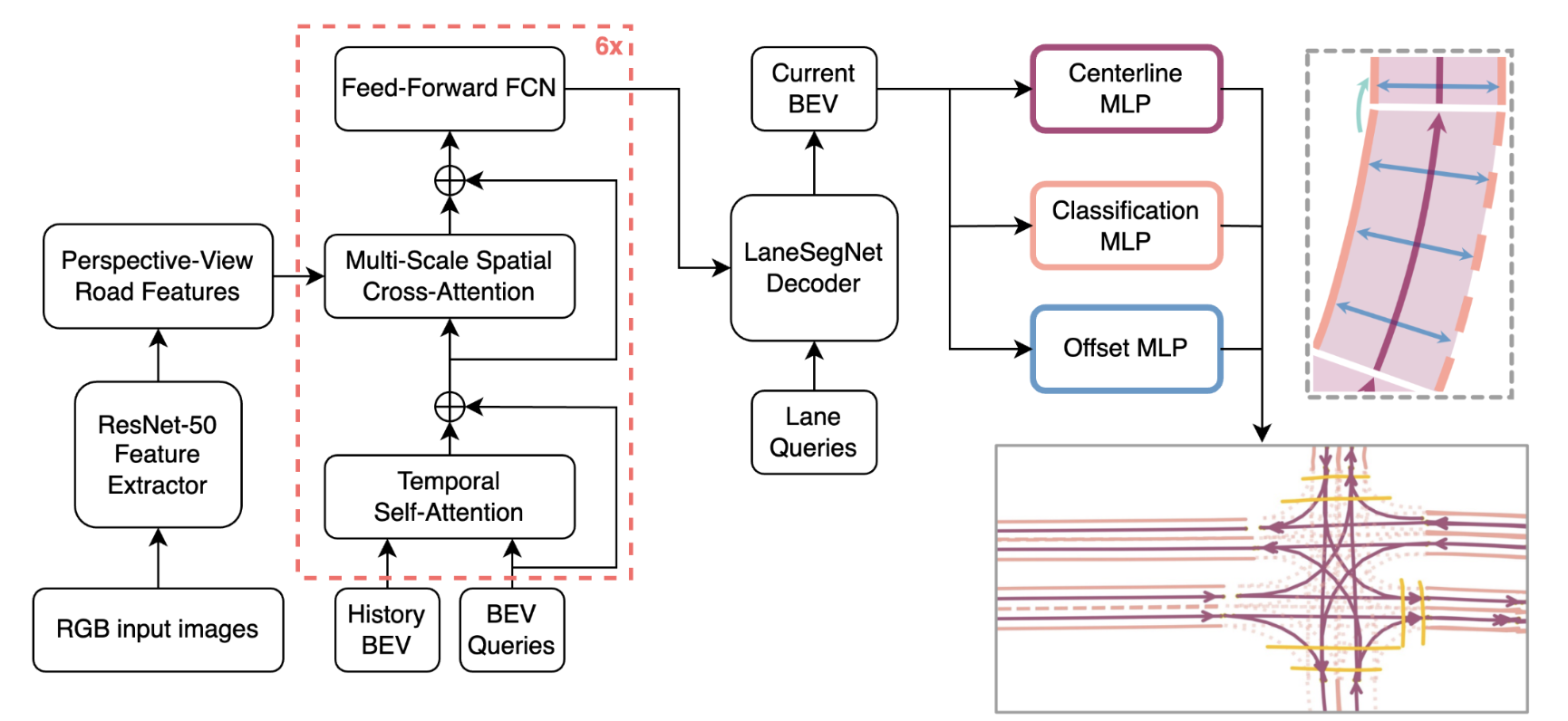
LaneSegNet Design Study
William Stevens, Vishal Urs, Karthik Selvaraj, Gabriel Torres, Gaurish Lakhanpal
With the increasing prevalence of autonomous vehicles, it is essential for computer vision algorithms to accurately assess road features in real-time. This study explores the LaneSegNet architecture, a new approach to lane topology prediction which integrates topological information with lane-line data to provide a more contextual understanding of road environments. The LaneSegNet architecture includes a feature extractor, lane encoder, lane decoder, and prediction head, leveraging components from ResNet-50, BEVFormer, and various attention mechanisms. We experimented with optimizations to the LaneSegNet architecture through feature extractor modification and transformer encoder-decoder stack modification. We found that modifying the encoder and decoder stacks offered an interesting tradeoff between training time and prediction accuracy, with certain combinations showing promising results. Our implementation, trained on a single NVIDIA Tesla A100 GPU, found that a 2:4 ratio reduced training time by 22.3% with only a 7.1% drop in mean average precision, while a 4:8 ratio increased training time by only 11.1% but improved mean average precision by a significant 23.7%. These results indicate that strategic hyperparameter tuning can yield substantial improvements depending on the resources of the user. This study provides valuable insights for optimizing LaneSegNet according to available computation power, making it more accessible for users with limited resources and increasing the capabilities for users with more powerful resources.
Read more8/1/2024

0
SFPNet: Sparse Focal Point Network for Semantic Segmentation on General LiDAR Point Clouds
Yanbo Wang, Wentao Zhao, Chuan Cao, Tianchen Deng, Jingchuan Wang, Weidong Chen
Although LiDAR semantic segmentation advances rapidly, state-of-the-art methods often incorporate specifically designed inductive bias derived from benchmarks originating from mechanical spinning LiDAR. This can limit model generalizability to other kinds of LiDAR technologies and make hyperparameter tuning more complex. To tackle these issues, we propose a generalized framework to accommodate various types of LiDAR prevalent in the market by replacing window-attention with our sparse focal point modulation. Our SFPNet is capable of extracting multi-level contexts and dynamically aggregating them using a gate mechanism. By implementing a channel-wise information query, features that incorporate both local and global contexts are encoded. We also introduce a novel large-scale hybrid-solid LiDAR semantic segmentation dataset for robotic applications. SFPNet demonstrates competitive performance on conventional benchmarks derived from mechanical spinning LiDAR, while achieving state-of-the-art results on benchmark derived from solid-state LiDAR. Additionally, it outperforms existing methods on our novel dataset sourced from hybrid-solid LiDAR. Code and dataset are available at https://github.com/Cavendish518/SFPNet and https://www.semanticindustry.top.
Read more7/17/2024