Enhancing Action Recognition from Low-Quality Skeleton Data via Part-Level Knowledge Distillation

0

Sign in to get full access
Overview
- This paper proposes a part-level knowledge distillation approach to enhance action recognition from low-quality skeleton data.
- The key idea is to leverage high-quality skeleton data to guide the training of a model on low-quality skeleton data, using a novel part-level knowledge distillation technique.
- The method aims to improve action recognition accuracy when working with challenging, noisy skeleton data, which is common in real-world applications.
Plain English Explanation
Skeleton-based action recognition is a popular technique in computer vision, where the movement and pose of a person's body parts are used to identify actions like walking, jumping, or waving. However, in real-world scenarios, the skeleton data captured by sensors can be of low quality, with missing or inaccurate joint locations.
To address this challenge, the researchers in this paper developed a technique called "part-level knowledge distillation." The idea is to use high-quality skeleton data from a well-performing model to guide the training of a new model that will work with low-quality skeleton data.
The key advantage of this approach is that it allows the new model to learn useful information about the relationships between different body parts, even when the input data is noisy. By focusing on the part-level features, the model can better recognize actions despite the low-quality input.
Through experiments, the researchers showed that their part-level knowledge distillation approach can significantly improve action recognition accuracy compared to other methods, especially when working with low-quality skeleton data. This makes the technique particularly useful for real-world applications where the input data may not be perfect, such as in surveillance, gaming, or human-computer interaction systems.
Technical Explanation
The paper proposes a part-level knowledge distillation framework to enhance action recognition from low-quality skeleton data. The key idea is to leverage a pre-trained high-quality model to guide the training of a new model that will operate on low-quality skeleton inputs.
The framework consists of three main components:
- High-quality Skeleton Model: A well-performing model trained on high-quality skeleton data, which serves as the "teacher" model.
- Low-quality Skeleton Model: The new model being trained to work with low-quality skeleton data, which acts as the "student" model.
- Part-level Knowledge Distillation: A novel distillation technique that transfers knowledge from the teacher model to the student model at the part level, rather than just at the global action level.
The part-level distillation process involves calculating the difference between the teacher and student models' predictions for each individual body part, and then using this information to update the student model's parameters during training. This encourages the student model to learn the relationships between different body parts, even when the input data is noisy.
The researchers evaluated their approach on several benchmark action recognition datasets, including link to "Learning by Aligning 2D Skeleton Sequences" and link to "Two-Person Interaction Augmentation with Skeleton Priors". The results demonstrate that the part-level knowledge distillation technique can significantly improve action recognition accuracy, especially when working with low-quality skeleton data.
Critical Analysis
The paper presents a novel and promising approach to address the challenge of action recognition from low-quality skeleton data. The part-level knowledge distillation technique is a creative solution that leverages high-quality data to guide the training of a model on more challenging, real-world inputs.
One potential limitation of the approach is that it requires access to a well-performing "teacher" model trained on high-quality skeleton data. In some cases, such a model may not be available, which could limit the applicability of the method. Additionally, the paper does not explore the impact of the quality of the teacher model on the performance of the student model, which could be an area for further investigation.
Another area for potential improvement is the computational efficiency of the part-level distillation process. The paper does not provide detailed information on the runtime or memory requirements of the approach, which could be important considerations for real-world deployment, especially in resource-constrained environments.
Despite these potential limitations, the paper makes a valuable contribution to the field of action recognition by demonstrating the effectiveness of part-level knowledge distillation in enhancing performance on low-quality skeleton data. The research has implications for a wide range of applications, such as link to "Improve Knowledge Distillation via Label Revision and Data Augmentation" and link to "Improving Facial Landmark Detection Accuracy and Efficiency through Knowledge Distillation", where dealing with noisy or incomplete data is a common challenge.
Conclusion
This paper presents a novel part-level knowledge distillation approach to enhance action recognition from low-quality skeleton data. By leveraging high-quality skeleton data to guide the training of a model on more challenging, real-world inputs, the researchers were able to significantly improve action recognition accuracy.
The key contribution of this work is the part-level distillation technique, which allows the model to learn the relationships between different body parts, even when the input data is noisy. This makes the approach particularly useful for real-world applications where the input data may not be perfect, such as in surveillance, gaming, or human-computer interaction systems.
Overall, the paper presents a valuable advancement in the field of action recognition, with the potential to have a significant impact on a wide range of computer vision applications that rely on skeleton-based data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Action Recognition from Low-Quality Skeleton Data via Part-Level Knowledge Distillation
Cuiwei Liu, Youzhi Jiang, Chong Du, Zhaokui Li
Skeleton-based action recognition is vital for comprehending human-centric videos and has applications in diverse domains. One of the challenges of skeleton-based action recognition is dealing with low-quality data, such as skeletons that have missing or inaccurate joints. This paper addresses the issue of enhancing action recognition using low-quality skeletons through a general knowledge distillation framework. The proposed framework employs a teacher-student model setup, where a teacher model trained on high-quality skeletons guides the learning of a student model that handles low-quality skeletons. To bridge the gap between heterogeneous high-quality and lowquality skeletons, we present a novel part-based skeleton matching strategy, which exploits shared body parts to facilitate local action pattern learning. An action-specific part matrix is developed to emphasize critical parts for different actions, enabling the student model to distill discriminative part-level knowledge. A novel part-level multi-sample contrastive loss achieves knowledge transfer from multiple high-quality skeletons to low-quality ones, which enables the proposed knowledge distillation framework to include training low-quality skeletons that lack corresponding high-quality matches. Comprehensive experiments conducted on the NTU-RGB+D, Penn Action, and SYSU 3D HOI datasets demonstrate the effectiveness of the proposed knowledge distillation framework.
Read more4/30/2024

0
Vision-Language Meets the Skeleton: Progressively Distillation with Cross-Modal Knowledge for 3D Action Representation Learning
Yang Chen, Tian He, Junfeng Fu, Ling Wang, Jingcai Guo, Hong Cheng
Supervised and self-supervised learning are two main training paradigms for skeleton-based human action recognition. However, the former one-hot classification requires labor-intensive predefined action categories annotations, while the latter involves skeleton transformations (e.g., cropping) in the pretext tasks that may impair the skeleton structure. To address these challenges, we introduce a novel skeleton-based training framework (C$^2$VL) based on Cross-modal Contrastive learning that uses the progressive distillation to learn task-agnostic human skeleton action representation from the Vision-Language knowledge prompts. Specifically, we establish the vision-language action concept space through vision-language knowledge prompts generated by pre-trained large multimodal models (LMMs), which enrich the fine-grained details that the skeleton action space lacks. Moreover, we propose the intra-modal self-similarity and inter-modal cross-consistency softened targets in the cross-modal contrastive process to progressively control and guide the degree of pulling vision-language knowledge prompts and corresponding skeletons closer. These soft instance discrimination and self-knowledge distillation strategies contribute to the learning of better skeleton-based action representations from the noisy skeleton-vision-language pairs. During the inference phase, our method requires only the skeleton data as the input for action recognition and no longer for vision-language prompts. Extensive experiments show that our method achieves state-of-the-art results on NTU RGB+D 60, NTU RGB+D 120, and PKU-MMD datasets. The code will be available in the future.
Read more6/3/2024

0
DL-KDD: Dual-Light Knowledge Distillation for Action Recognition in the Dark
Chi-Jui Chang, Oscar Tai-Yuan Chen, Vincent S. Tseng
Human action recognition in dark videos is a challenging task for computer vision. Recent research focuses on applying dark enhancement methods to improve the visibility of the video. However, such video processing results in the loss of critical information in the original (un-enhanced) video. Conversely, traditional two-stream methods are capable of learning information from both original and processed videos, but it can lead to a significant increase in the computational cost during the inference phase in the task of video classification. To address these challenges, we propose a novel teacher-student video classification framework, named Dual-Light KnowleDge Distillation for Action Recognition in the Dark (DL-KDD). This framework enables the model to learn from both original and enhanced video without introducing additional computational cost during inference. Specifically, DL-KDD utilizes the strategy of knowledge distillation during training. The teacher model is trained with enhanced video, and the student model is trained with both the original video and the soft target generated by the teacher model. This teacher-student framework allows the student model to predict action using only the original input video during inference. In our experiments, the proposed DL-KDD framework outperforms state-of-the-art methods on the ARID, ARID V1.5, and Dark-48 datasets. We achieve the best performance on each dataset and up to a 4.18% improvement on Dark-48, using only original video inputs, thus avoiding the use of two-stream framework or enhancement modules for inference. We further validate the effectiveness of the distillation strategy in ablative experiments. The results highlight the advantages of our knowledge distillation framework in dark human action recognition.
Read more6/5/2024
0
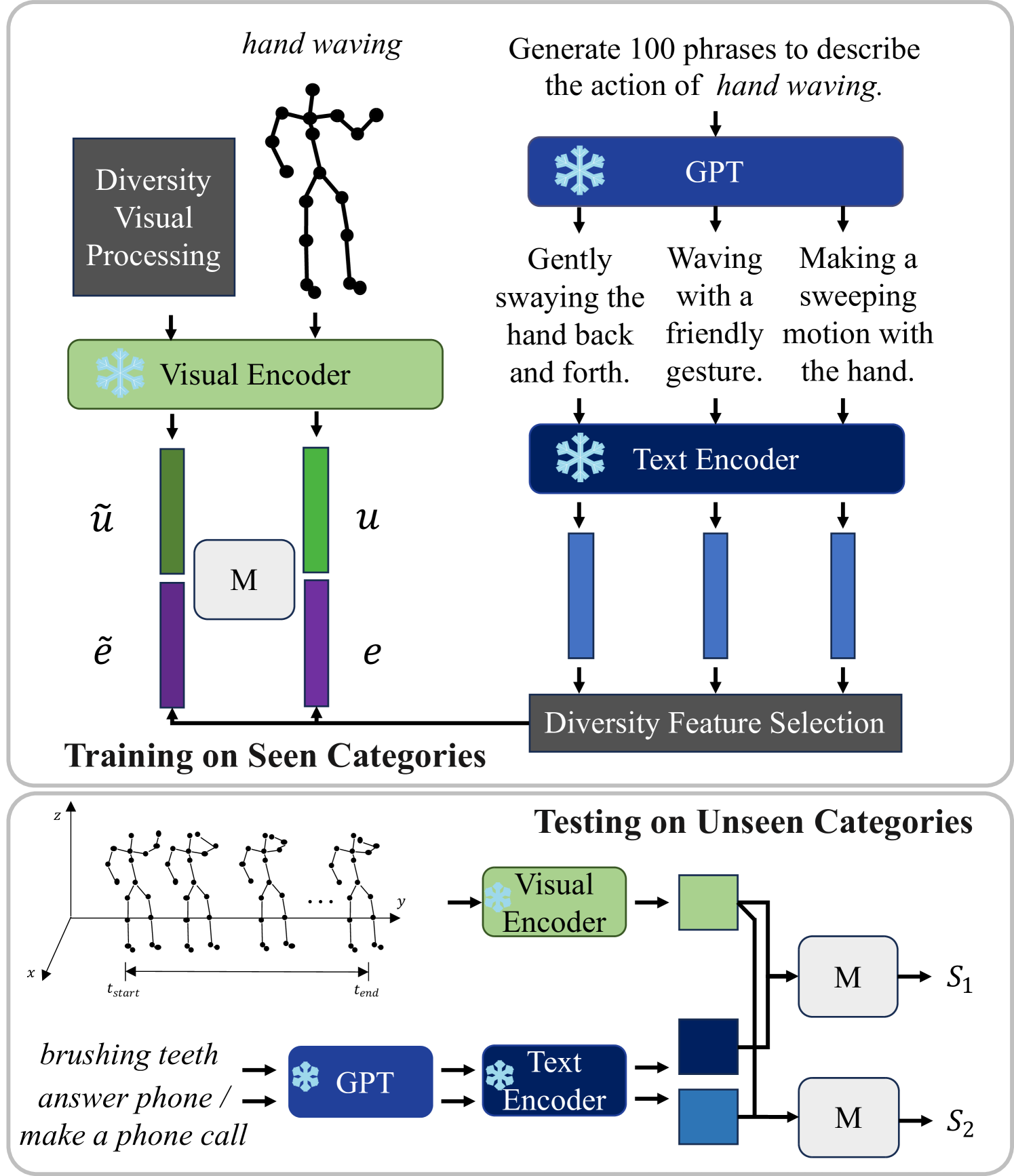
An Information Compensation Framework for Zero-Shot Skeleton-based Action Recognition
Haojun Xu, Yan Gao, Jie Li, Xinbo Gao
Zero-shot human skeleton-based action recognition aims to construct a model that can recognize actions outside the categories seen during training. Previous research has focused on aligning sequences' visual and semantic spatial distributions. However, these methods extract semantic features simply. They ignore that proper prompt design for rich and fine-grained action cues can provide robust representation space clustering. In order to alleviate the problem of insufficient information available for skeleton sequences, we design an information compensation learning framework from an information-theoretic perspective to improve zero-shot action recognition accuracy with a multi-granularity semantic interaction mechanism. Inspired by ensemble learning, we propose a multi-level alignment (MLA) approach to compensate information for action classes. MLA aligns multi-granularity embeddings with visual embedding through a multi-head scoring mechanism to distinguish semantically similar action names and visually similar actions. Furthermore, we introduce a new loss function sampling method to obtain a tight and robust representation. Finally, these multi-granularity semantic embeddings are synthesized to form a proper decision surface for classification. Significant action recognition performance is achieved when evaluated on the challenging NTU RGB+D, NTU RGB+D 120, and PKU-MMD benchmarks and validate that multi-granularity semantic features facilitate the differentiation of action clusters with similar visual features.
Read more6/4/2024