Improving Facial Landmark Detection Accuracy and Efficiency with Knowledge Distillation
2404.06029
0
0

Abstract
The domain of computer vision has experienced significant advancements in facial-landmark detection, becoming increasingly essential across various applications such as augmented reality, facial recognition, and emotion analysis. Unlike object detection or semantic segmentation, which focus on identifying objects and outlining boundaries, faciallandmark detection aims to precisely locate and track critical facial features. However, deploying deep learning-based facial-landmark detection models on embedded systems with limited computational resources poses challenges due to the complexity of facial features, especially in dynamic settings. Additionally, ensuring robustness across diverse ethnicities and expressions presents further obstacles. Existing datasets often lack comprehensive representation of facial nuances, particularly within populations like those in Taiwan. This paper introduces a novel approach to address these challenges through the development of a knowledge distillation method. By transferring knowledge from larger models to smaller ones, we aim to create lightweight yet powerful deep learning models tailored specifically for facial-landmark detection tasks. Our goal is to design models capable of accurately locating facial landmarks under varying conditions, including diverse expressions, orientations, and lighting environments. The ultimate objective is to achieve high accuracy and real-time performance suitable for deployment on embedded systems. This method was successfully implemented and achieved a top 6th place finish out of 165 participants in the IEEE ICME 2024 PAIR competition.
Create account to get full access
Overview
- This paper describes a challenge for the IEEE ICME 2024 conference focused on developing low-power, efficient, and accurate facial landmark detection models for embedded systems.
- The challenge aims to advance the state-of-the-art in facial landmark detection by encouraging the development of lightweight models that can run effectively on resource-constrained devices.
- Key aspects of the challenge include optimizing model size and computational complexity while maintaining high accuracy on benchmark datasets.
Plain English Explanation
This paper outlines a contest for researchers and engineers to create new facial landmark detection models that are both powerful and efficient. Facial landmark detection is the process of identifying key points on a person's face, like the corners of the eyes or tips of the nose, in images or videos.
The goal of this challenge is to develop models that can accurately detect facial landmarks, but use very little power and computer resources. This is important for embedding these models in small, battery-powered devices like smartphones or security cameras. Current state-of-the-art models are often too large and computationally intensive to run well on these types of embedded systems.
Participants will need to find ways to reduce the size and complexity of their models while still maintaining high accuracy on standard benchmark datasets. This could involve techniques like knowledge distillation or model compression. The most innovative and effective solutions will be awarded prizes.
Technical Explanation
The key aspects of the challenge as described in the paper are:
-
Model Size and Complexity Optimization: Participants must develop facial landmark detection models that are small in size and have low computational complexity, enabling them to run efficiently on embedded devices with limited resources.
-
High Accuracy Maintenance: Even as the models are optimized for size and efficiency, they must maintain high accuracy on standard facial landmark detection benchmark datasets like 300W and WFLW.
-
Embedded System Deployment: The models should be designed with the constraints of embedded systems in mind, such as limited memory, processing power, and energy budgets.
The paper suggests that techniques like knowledge distillation and model compression could be leveraged to create small, efficient models without sacrificing too much accuracy. Participants will need to carefully balance model complexity, size, and performance to meet the challenge requirements.
Critical Analysis
The challenge outlined in this paper addresses an important real-world problem in computer vision and embedded systems. As the use of facial recognition and analysis grows, there is a clear need for lightweight, efficient models that can be deployed on resource-constrained devices.
However, the paper does not provide much detail on the specific evaluation criteria or benchmarks that will be used to assess the submitted models. It will be important for the organizers to clearly define the performance targets and ensure a fair and rigorous evaluation process.
Additionally, the paper does not discuss potential ethical concerns around the use of facial landmark detection technology, such as privacy issues or algorithmic bias. These are important considerations that the challenge organizers should address to ensure the research is conducted responsibly.
Overall, this challenge represents an interesting opportunity to advance the state-of-the-art in efficient computer vision models. But the organizers should carefully consider the broader implications and potential downsides of the technology being developed.
Conclusion
This IEEE ICME 2024 Grand Challenge aims to drive innovation in the field of facial landmark detection by encouraging the development of low-power, efficient models that can be deployed on embedded systems. By focusing on optimizing model size and complexity while maintaining high accuracy, the challenge could lead to significant advancements in how computer vision technology is implemented in real-world applications.
The success of this challenge could have broad implications, enabling more widespread use of facial analysis capabilities in a wide range of industries and devices. However, the organizers should also carefully consider the ethical considerations around this technology to ensure it is developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
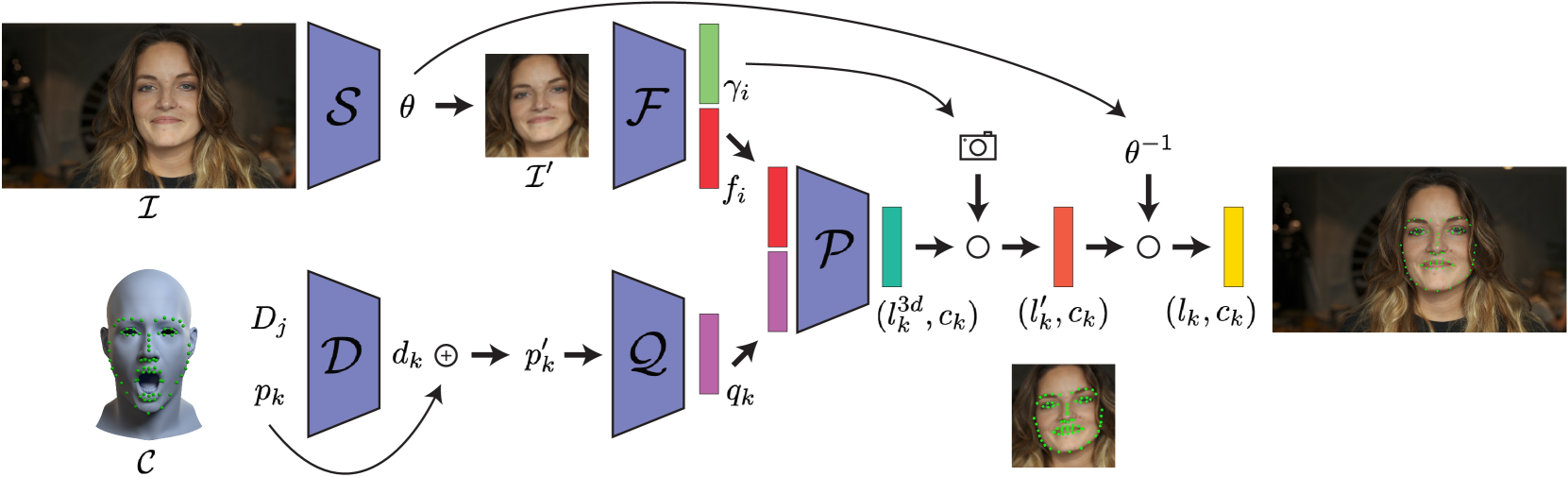
Infinite 3D Landmarks: Improving Continuous 2D Facial Landmark Detection
Prashanth Chandran, Gaspard Zoss, Paulo Gotardo, Derek Bradley
0
0
In this paper, we examine 3 important issues in the practical use of state-of-the-art facial landmark detectors and show how a combination of specific architectural modifications can directly improve their accuracy and temporal stability. First, many facial landmark detectors require face normalization as a preprocessing step, which is accomplished by a separately-trained neural network that crops and resizes the face in the input image. There is no guarantee that this pre-trained network performs the optimal face normalization for landmark detection. We instead analyze the use of a spatial transformer network that is trained alongside the landmark detector in an unsupervised manner, and jointly learn optimal face normalization and landmark detection. Second, we show that modifying the output head of the landmark predictor to infer landmarks in a canonical 3D space can further improve accuracy. To convert the predicted 3D landmarks into screen-space, we additionally predict the camera intrinsics and head pose from the input image. As a side benefit, this allows to predict the 3D face shape from a given image only using 2D landmarks as supervision, which is useful in determining landmark visibility among other things. Finally, when training a landmark detector on multiple datasets at the same time, annotation inconsistencies across datasets forces the network to produce a suboptimal average. We propose to add a semantic correction network to address this issue. This additional lightweight neural network is trained alongside the landmark detector, without requiring any additional supervision. While the insights of this paper can be applied to most common landmark detectors, we specifically target a recently-proposed continuous 2D landmark detector to demonstrate how each of our additions leads to meaningful improvements over the state-of-the-art on standard benchmarks.
5/31/2024
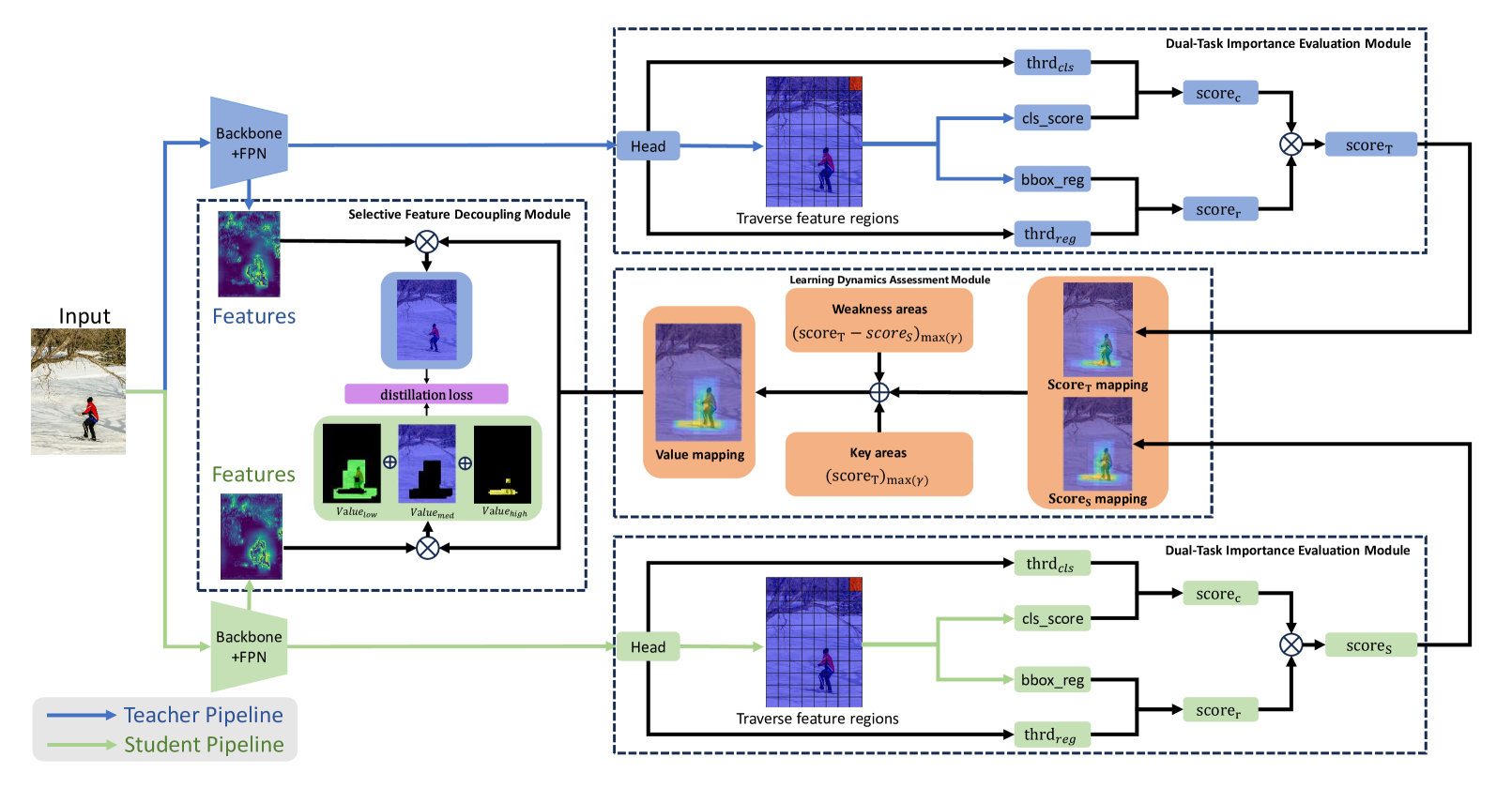
Task Integration Distillation for Object Detectors
Hai Su, ZhenWen Jian, Songsen Yu
0
0
Knowledge distillation is a widely adopted technique for model lightening. However, the performance of most knowledge distillation methods in the domain of object detection is not satisfactory. Typically, knowledge distillation approaches consider only the classification task among the two sub-tasks of an object detector, largely overlooking the regression task. This oversight leads to a partial understanding of the object detector's comprehensive task, resulting in skewed estimations and potentially adverse effects. Therefore, we propose a knowledge distillation method that addresses both the classification and regression tasks, incorporating a task significance strategy. By evaluating the importance of features based on the output of the detector's two sub-tasks, our approach ensures a balanced consideration of both classification and regression tasks in object detection. Drawing inspiration from real-world teaching processes and the definition of learning condition, we introduce a method that focuses on both key and weak areas. By assessing the value of features for knowledge distillation based on their importance differences, we accurately capture the current model's learning situation. This method effectively prevents the issue of biased predictions about the model's learning reality caused by an incomplete utilization of the detector's outputs.
4/3/2024
👀
A Comprehensive Review of Knowledge Distillation in Computer Vision
Sheikh Musa Kaleem, Tufail Rouf, Gousia Habib, Tausifa jan Saleem, Brejesh Lall
0
0
Deep learning techniques have been demonstrated to surpass preceding cutting-edge machine learning techniques in recent years, with computer vision being one of the most prominent examples. However, deep learning models suffer from significant drawbacks when deployed in resource-constrained environments due to their large model size and high complexity. Knowledge Distillation is one of the prominent solutions to overcome this challenge. This review paper examines the current state of research on knowledge distillation, a technique for compressing complex models into smaller and simpler ones. The paper provides an overview of the major principles and techniques associated with knowledge distillation and reviews the applications of knowledge distillation in the domain of computer vision. The review focuses on the benefits of knowledge distillation, as well as the problems that must be overcome to improve its effectiveness.
4/9/2024

Teaching with Uncertainty: Unleashing the Potential of Knowledge Distillation in Object Detection
Junfei Yi, Jianxu Mao, Tengfei Liu, Mingjie Li, Hanyu Gu, Hui Zhang, Xiaojun Chang, Yaonan Wang
0
0
Knowledge distillation (KD) is a widely adopted and effective method for compressing models in object detection tasks. Particularly, feature-based distillation methods have shown remarkable performance. Existing approaches often ignore the uncertainty in the teacher model's knowledge, which stems from data noise and imperfect training. This limits the student model's ability to learn latent knowledge, as it may overly rely on the teacher's imperfect guidance. In this paper, we propose a novel feature-based distillation paradigm with knowledge uncertainty for object detection, termed Uncertainty Estimation-Discriminative Knowledge Extraction-Knowledge Transfer (UET), which can seamlessly integrate with existing distillation methods. By leveraging the Monte Carlo dropout technique, we introduce knowledge uncertainty into the training process of the student model, facilitating deeper exploration of latent knowledge. Our method performs effectively during the KD process without requiring intricate structures or extensive computational resources. Extensive experiments validate the effectiveness of our proposed approach across various distillation strategies, detectors, and backbone architectures. Specifically, following our proposed paradigm, the existing FGD method achieves state-of-the-art (SoTA) performance, with ResNet50-based GFL achieving 44.1% mAP on the COCO dataset, surpassing the baselines by 3.9%.
6/12/2024