Enhancing In-Context Learning Performance with just SVD-Based Weight Pruning: A Theoretical Perspective

0
Sign in to get full access
Overview
- This paper explores the use of singular value decomposition (SVD)-based weight pruning to enhance the performance of in-context learning in large language models (LLMs).
- The authors provide a theoretical perspective on the benefits of this approach, which can improve the efficiency and effectiveness of LLMs without requiring significant architectural changes.
- The research builds upon previous work on SVD-based truncation and implicit context learning in LLMs.
Plain English Explanation
The paper discusses a way to improve the performance of large language models (LLMs) when they are used for in-context learning. In-context learning is a technique where the model takes in some background information or "context" and then uses that to help it generate new text or complete a task.
The key idea in this paper is to use a mathematical technique called singular value decomposition (SVD) to prune or simplify the weights of the LLM. This can make the model more efficient and effective without requiring major changes to the model architecture.
The authors build on previous research that has looked at using SVD to selectively keep or remove certain parts of the model's internal representation, as well as work on how LLMs can implicitly learn and use contextual information during their training.
Technical Explanation
The paper proposes using SVD-based weight pruning to enhance the in-context learning performance of LLMs. This approach involves decomposing the weight matrices of the LLM using SVD and then selectively retaining only the most important singular values and corresponding singular vectors.
This has the effect of simplifying the model's internal representation while preserving the most critical information. The authors show theoretically that this can lead to improved in-context learning capabilities, as the model is able to more effectively leverage the relevant contextual information.
The research builds on previous work, including SVD-based truncation for efficient LLM representation and implicit context learning techniques that allow LLMs to learn and utilize contextual information during training.
Critical Analysis
The paper provides a thoughtful theoretical analysis of the potential benefits of SVD-based weight pruning for in-context learning. However, the authors acknowledge that the proposed approach has not been empirically validated, and further experimental work is needed to demonstrate its effectiveness in practice.
Additionally, the paper does not address potential limitations or challenges that may arise when applying this technique to real-world LLM architectures and datasets. For example, the impact of weight pruning on the model's ability to generalize to new tasks or handle diverse input distributions is not explored.
It would also be valuable for the authors to consider the computational and memory efficiency tradeoffs of their approach, as well as any potential negative effects on model interpretability or robustness.
Conclusion
This paper presents a promising theoretical framework for enhancing the in-context learning performance of LLMs through the use of SVD-based weight pruning. By selectively simplifying the model's internal representation, the authors suggest that LLMs can more effectively leverage relevant contextual information to improve their task-solving capabilities.
While further empirical validation is needed, the research builds on important prior work and offers a compelling perspective on how to optimize LLM architectures for advanced in-context learning applications. As LLMs continue to play an increasingly prominent role in AI systems, techniques like the one proposed in this paper may prove crucial for unlocking their full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing In-Context Learning Performance with just SVD-Based Weight Pruning: A Theoretical Perspective
Xinhao Yao, Xiaolin Hu, Shenzhi Yang, Yong Liu
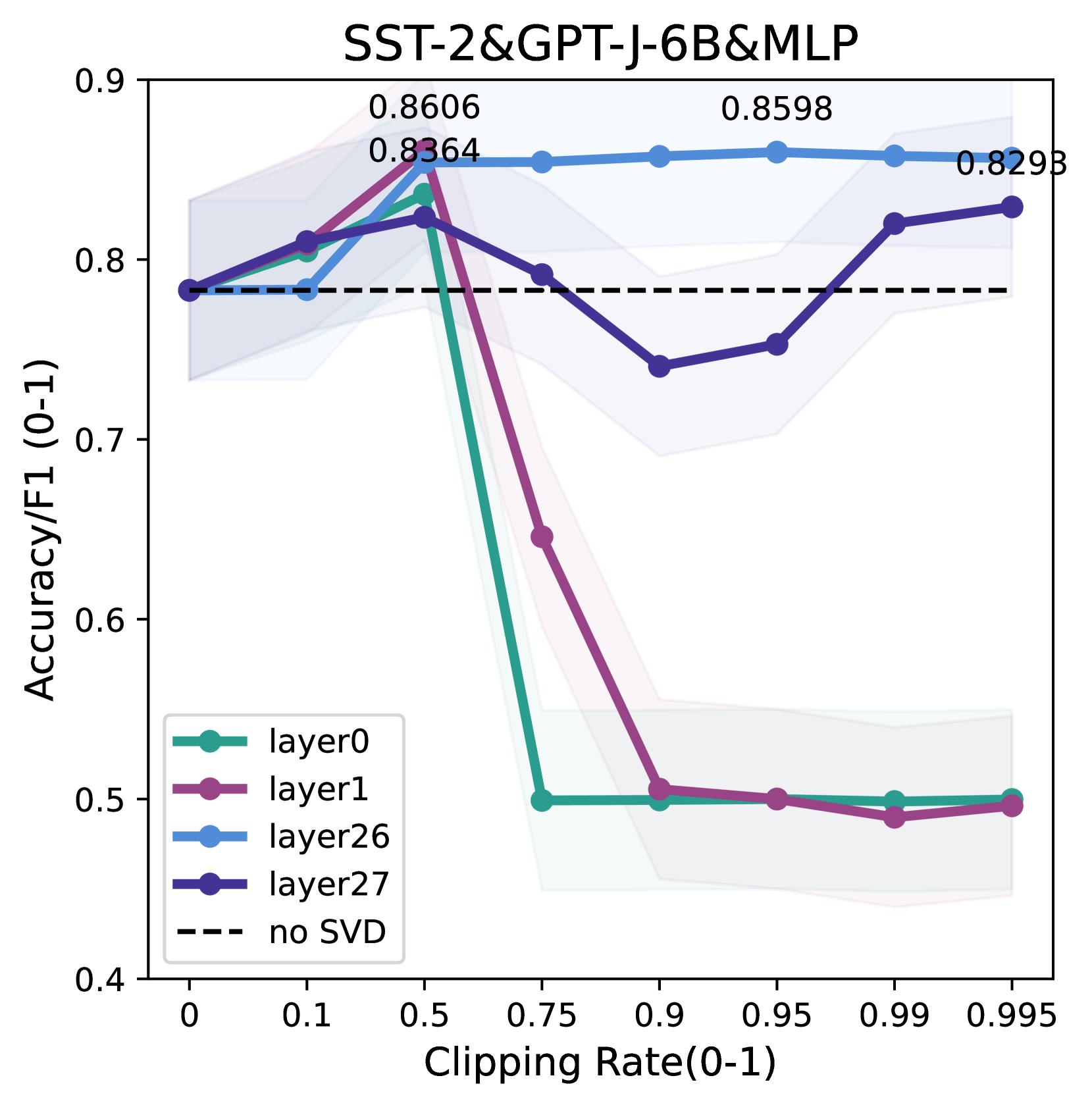
Pre-trained large language models (LLMs) based on Transformer have demonstrated striking in-context learning (ICL) abilities. With a few demonstration input-label pairs, they can predict the label for an unseen input without any parameter updates. In this paper, we show an exciting phenomenon that SVD-based weight pruning can enhance ICL performance, and more surprising, pruning weights in deep layers often results in more stable performance improvements in shallow layers. However, the underlying mechanism of those findings still remains an open question. To reveal those findings, we conduct an in-depth theoretical analysis by presenting the implicit gradient descent (GD) trajectories of ICL and giving the mutual information based generalization bounds of ICL via full implicit GD trajectories. This helps us reasonably explain the surprising experimental findings. Besides, based on all our experimental and theoretical insights, we intuitively propose a simple, model-compression and derivative-free algorithm for downstream tasks in enhancing ICL inference. Experiments on benchmark datasets and open source LLMs display the method effectivenessfootnote{The code is available at url{https://github.com/chen123CtrlS/EnhancingICL_SVDPruning}}.
Read more6/7/2024
🚀
0
Do pretrained Transformers Learn In-Context by Gradient Descent?
Lingfeng Shen, Aayush Mishra, Daniel Khashabi
The emergence of In-Context Learning (ICL) in LLMs remains a remarkable phenomenon that is partially understood. To explain ICL, recent studies have created theoretical connections to Gradient Descent (GD). We ask, do such connections hold up in actual pre-trained language models? We highlight the limiting assumptions in prior works that make their setup considerably different from the practical setup in which language models are trained. For example, their experimental verification uses emph{ICL objective} (training models explicitly for ICL), which differs from the emergent ICL in the wild. Furthermore, the theoretical hand-constructed weights used in these studies have properties that don't match those of real LLMs. We also look for evidence in real models. We observe that ICL and GD have different sensitivity to the order in which they observe demonstrations. Finally, we probe and compare the ICL vs. GD hypothesis in a natural setting. We conduct comprehensive empirical analyses on language models pre-trained on natural data (LLaMa-7B). Our comparisons of three performance metrics highlight the inconsistent behavior of ICL and GD as a function of various factors such as datasets, models, and the number of demonstrations. We observe that ICL and GD modify the output distribution of language models differently. These results indicate that emph{the equivalence between ICL and GD remains an open hypothesis} and calls for further studies.
Read more6/4/2024

0
Does learning the right latent variables necessarily improve in-context learning?
Sarthak Mittal, Eric Elmoznino, Leo Gagnon, Sangnie Bhardwaj, Dhanya Sridhar, Guillaume Lajoie
Large autoregressive models like Transformers can solve tasks through in-context learning (ICL) without learning new weights, suggesting avenues for efficiently solving new tasks. For many tasks, e.g., linear regression, the data factorizes: examples are independent given a task latent that generates the data, e.g., linear coefficients. While an optimal predictor leverages this factorization by inferring task latents, it is unclear if Transformers implicitly do so or if they instead exploit heuristics and statistical shortcuts enabled by attention layers. Both scenarios have inspired active ongoing work. In this paper, we systematically investigate the effect of explicitly inferring task latents. We minimally modify the Transformer architecture with a bottleneck designed to prevent shortcuts in favor of more structured solutions, and then compare performance against standard Transformers across various ICL tasks. Contrary to intuition and some recent works, we find little discernible difference between the two; biasing towards task-relevant latent variables does not lead to better out-of-distribution performance, in general. Curiously, we find that while the bottleneck effectively learns to extract latent task variables from context, downstream processing struggles to utilize them for robust prediction. Our study highlights the intrinsic limitations of Transformers in achieving structured ICL solutions that generalize, and shows that while inferring the right latents aids interpretability, it is not sufficient to alleviate this problem.
Read more5/30/2024
0
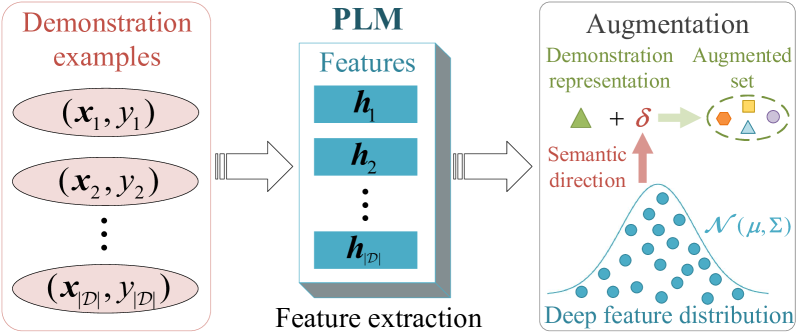
Enhancing In-Context Learning via Implicit Demonstration Augmentation
Xiaoling Zhou, Wei Ye, Yidong Wang, Chaoya Jiang, Zhemg Lee, Rui Xie, Shikun Zhang
The emergence of in-context learning (ICL) enables large pre-trained language models (PLMs) to make predictions for unseen inputs without updating parameters. Despite its potential, ICL's effectiveness heavily relies on the quality, quantity, and permutation of demonstrations, commonly leading to suboptimal and unstable performance. In this paper, we tackle this challenge for the first time from the perspective of demonstration augmentation. Specifically, we start with enriching representations of demonstrations by leveraging their deep feature distribution. We then theoretically reveal that when the number of augmented copies approaches infinity, the augmentation is approximately equal to a novel logit calibration mechanism integrated with specific statistical properties. This insight results in a simple yet highly efficient method that significantly improves the average and worst-case accuracy across diverse PLMs and tasks. Moreover, our method effectively reduces performance variance among varying demonstrations, permutations, and templates, and displays the capability to address imbalanced class distributions.
Read more7/2/2024