SVD-LLM: Truncation-aware Singular Value Decomposition for Large Language Model Compression

0

Sign in to get full access
Overview
• This research paper introduces a novel technique called SVD-LLM for compressing large language models using a truncation-aware Singular Value Decomposition (SVD) approach.
• The key idea is to leverage the structure of large language models to enable more efficient compression through a tailored SVD-based method.
• The paper provides a detailed technical explanation of the SVD-LLM approach, evaluates its performance on various benchmarks, and discusses the implications and potential limitations of the proposed technique.
Plain English Explanation
• Large language models, like those used in chatbots and other AI applications, can be extremely powerful but also very large and resource-intensive. This makes them difficult to deploy on resource-constrained devices or in applications with limited computing power.
• The researchers in this paper have developed a new way to compress these large language models, making them much smaller and more efficient to use, without losing too much of their original performance.
• The key insight is that the structure of these language models can be leveraged to apply a specialized version of a mathematical technique called Singular Value Decomposition (SVD) to compress the model more effectively.
• By being "truncation-aware," the SVD-LLM approach can identify and retain the most important parts of the language model while discarding the less important parts, leading to significant compression without too much loss in accuracy.
• This could enable the deployment of powerful language models on a wider range of devices and in more resource-constrained applications, opening up new possibilities for AI-powered technologies.
Technical Explanation
• The paper introduces a novel technique called SVD-LLM for compressing large language models using a truncation-aware Singular Value Decomposition (SVD) approach.
• The core idea is to leverage the structure of large language models, which typically consist of multiple layers of neural networks, to enable more efficient compression through a tailored SVD-based method.
• The researchers propose a two-stage approach: first, they apply SVD to the weight matrices of the individual layers of the language model, and then they introduce a "truncation-aware" step that selectively retains the most important singular values and vectors based on their contribution to the overall model performance.
• This truncation-aware approach allows the researchers to achieve significant compression rates (up to 10x) while maintaining relatively high performance on various language tasks, as demonstrated through extensive experiments on benchmarks like GLUE and SQuAD.
• The paper also provides a detailed analysis of the trade-offs between compression rate and model performance, as well as insights into the impact of the truncation-aware SVD on the internal representations and behaviors of the compressed language models.
Critical Analysis
• The SVD-LLM approach presented in the paper is a promising and well-designed technique for compressing large language models, leveraging the inherent structure of these models to enable more efficient compression.
• However, the paper does not address the potential limitations of the SVD-LLM approach, such as its applicability to other types of neural network architectures beyond language models, or the impact of the compression on the model's ability to generalize to out-of-distribution data.
• Additionally, the paper could have provided more insights into the theoretical underpinnings of the truncation-aware SVD, and how it compares to other low-rank approximation techniques, such as those explored in TriLora, Feature-Based Low-Rank Compression, and Basis Selection for Low-Rank Decomposition.
• It would also be interesting to see how the SVD-LLM approach compares to other language model compression techniques, such as Sparse LLM, in terms of performance, efficiency, and practical implications.
Conclusion
• The SVD-LLM technique presented in this paper offers a promising approach for compressing large language models, enabling their deployment on a wider range of devices and in more resource-constrained applications.
• The truncation-aware SVD-based method leverages the inherent structure of language models to achieve significant compression rates while maintaining relatively high performance on various language tasks.
• While the paper provides a detailed technical explanation and evaluation of the SVD-LLM approach, further research is needed to explore its broader applicability, theoretical foundations, and comparison to other compression techniques to fully understand its potential impact on the field of large language model deployment and optimization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SVD-LLM: Truncation-aware Singular Value Decomposition for Large Language Model Compression
Xin Wang, Yu Zheng, Zhongwei Wan, Mi Zhang
The advancements in Large Language Models (LLMs) have been hindered by their substantial sizes, which necessitate LLM compression methods for practical deployment. Singular Value Decomposition (SVD) offers a promising solution for LLM compression. However, state-of-the-art SVD-based LLM compression methods have two key limitations: truncating smaller singular values may lead to higher compression loss, and the lack of update on the compressed weight after SVD truncation. In this work, we propose SVD-LLM, a new SVD-based LLM compression method that addresses the limitations of existing methods. SVD-LLM incorporates a truncation-aware data whitening strategy to ensure a direct mapping between singular values and compression loss. Moreover, SVD-LLM adopts a layer-wise closed-form model parameter update strategy to compensate for accuracy degradation under high compression ratios. We evaluate SVD-LLM on a total of 10 datasets and eight models from three different LLM families at four different scales. Our results demonstrate the superiority of SVD-LLM over state-of-the-arts, especially at high model compression ratios.
Read more5/29/2024

0
ASVD: Activation-aware Singular Value Decomposition for Compressing Large Language Models
Zhihang Yuan, Yuzhang Shang, Yue Song, Qiang Wu, Yan Yan, Guangyu Sun
In this paper, we introduce a new post-training compression paradigm for Large Language Models (LLMs) to facilitate their wider adoption. We delve into LLM weight low-rank factorization, and find that the challenges of this task stem from the outlier phenomenon in the LLM activations and the sensitivity difference among various kinds of layers. To address these issues, we propose a training-free approach called Activation-aware Singular Value Decomposition (ASVD). Specifically, ASVD manages activation outliers by scaling the weight matrix based on the activation distribution, thereby enhancing decomposition accuracy. Additionally, we propose an efficient iterative calibration process to optimize layer-specific decomposition by addressing the varying sensitivity of different LLM layers. ASVD can compress a network by 10-20%, without compromising the performance of LLMs. Based on the success of the low-rank decomposition of projection matrices in the self-attention module, we further introduce ASVD to compress the KV cache. By reducing the channel dimension of KV activations, memory requirements for KV cache can be largely reduced. Thanks to the 50-75% reduction in the rank of the KV projection matrices, ASVD can further achieve 50% KV cache reductions without performance drop in a training-free manner.
Read more5/27/2024
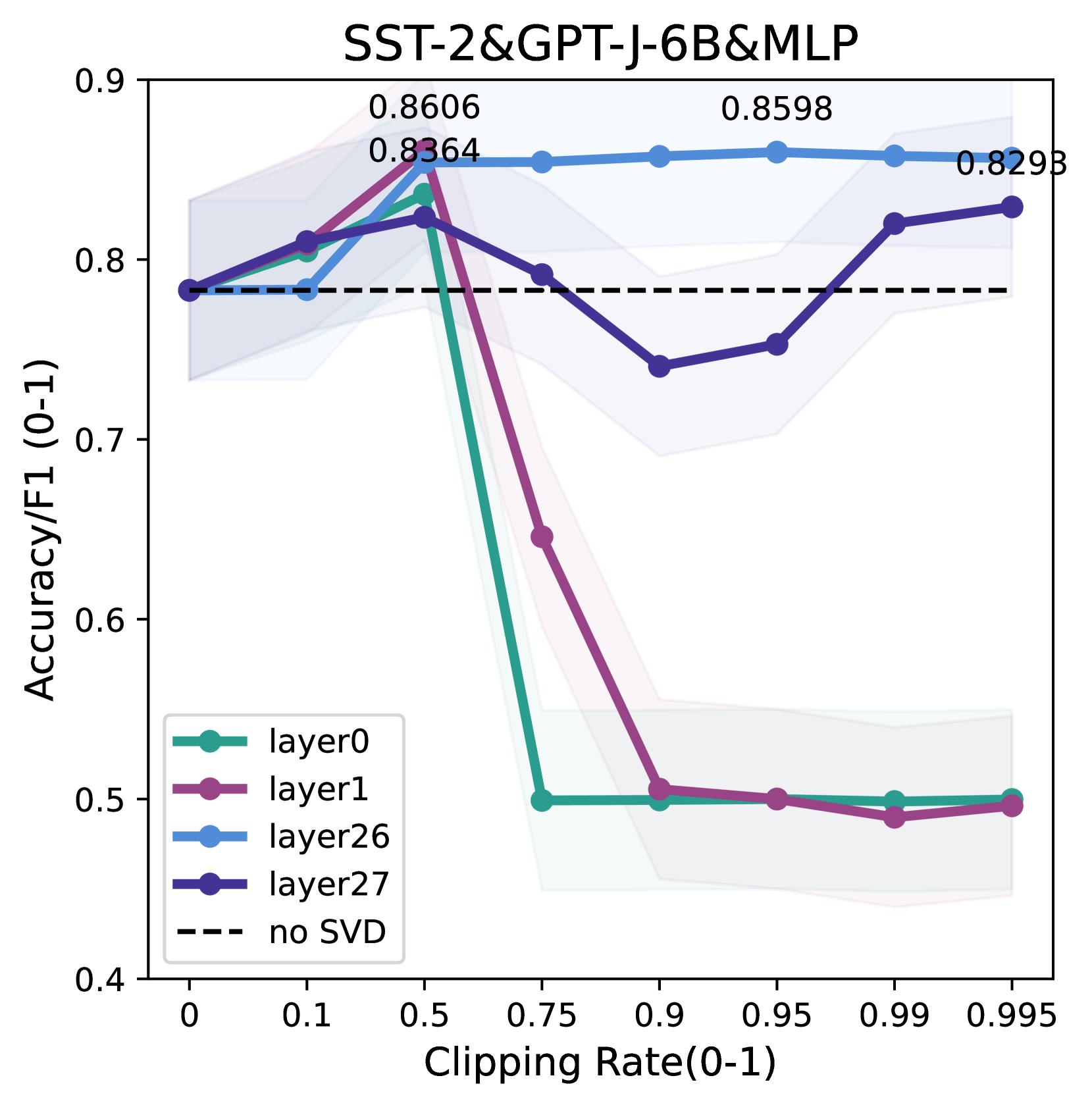
0
Enhancing In-Context Learning Performance with just SVD-Based Weight Pruning: A Theoretical Perspective
Xinhao Yao, Xiaolin Hu, Shenzhi Yang, Yong Liu
Pre-trained large language models (LLMs) based on Transformer have demonstrated striking in-context learning (ICL) abilities. With a few demonstration input-label pairs, they can predict the label for an unseen input without any parameter updates. In this paper, we show an exciting phenomenon that SVD-based weight pruning can enhance ICL performance, and more surprising, pruning weights in deep layers often results in more stable performance improvements in shallow layers. However, the underlying mechanism of those findings still remains an open question. To reveal those findings, we conduct an in-depth theoretical analysis by presenting the implicit gradient descent (GD) trajectories of ICL and giving the mutual information based generalization bounds of ICL via full implicit GD trajectories. This helps us reasonably explain the surprising experimental findings. Besides, based on all our experimental and theoretical insights, we intuitively propose a simple, model-compression and derivative-free algorithm for downstream tasks in enhancing ICL inference. Experiments on benchmark datasets and open source LLMs display the method effectivenessfootnote{The code is available at url{https://github.com/chen123CtrlS/EnhancingICL_SVDPruning}}.
Read more6/7/2024
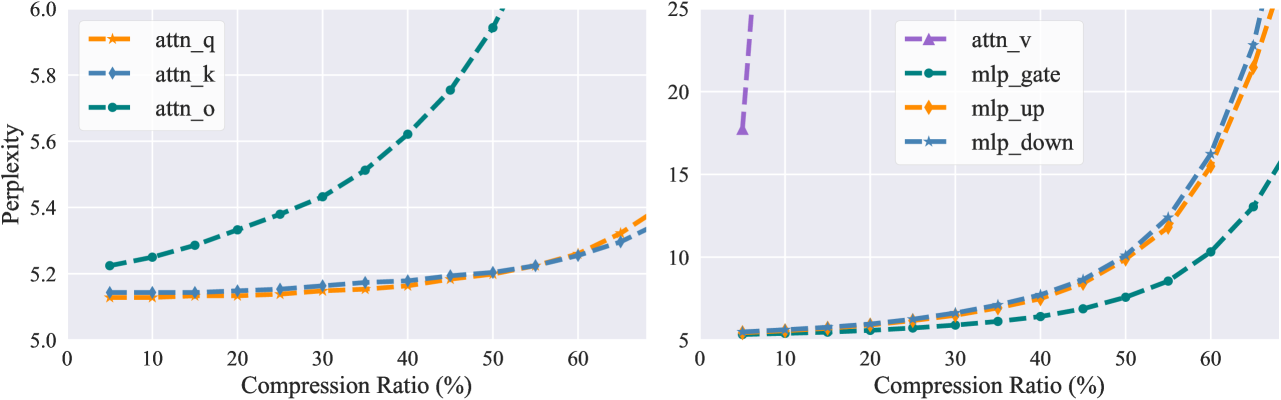
0
Feature-based Low-Rank Compression of Large Language Models via Bayesian Optimization
Yixin Ji, Yang Xiang, Juntao Li, Wei Chen, Zhongyi Liu, Kehai Chen, Min Zhang
In recent years, large language models (LLMs) have driven advances in natural language processing. Still, their growing scale has increased the computational burden, necessitating a balance between efficiency and performance. Low-rank compression, a promising technique, reduces non-essential parameters by decomposing weight matrices into products of two low-rank matrices. Yet, its application in LLMs has not been extensively studied. The key to low-rank compression lies in low-rank factorization and low-rank dimensions allocation. To address the challenges of low-rank compression in LLMs, we conduct empirical research on the low-rank characteristics of large models. We propose a low-rank compression method suitable for LLMs. This approach involves precise estimation of feature distributions through pooled covariance matrices and a Bayesian optimization strategy for allocating low-rank dimensions. Experiments on the LLaMA-2 models demonstrate that our method outperforms existing strong structured pruning and low-rank compression techniques in maintaining model performance at the same compression ratio.
Read more5/20/2024