Enhancing Human Action Recognition and Violence Detection Through Deep Learning Audiovisual Fusion

0
Sign in to get full access
Overview
- This paper explores the use of deep learning and audiovisual data fusion to enhance human action recognition and violence detection.
- The researchers developed a deep learning model that combines visual and audio information to improve the accuracy of recognizing human actions and detecting violent behavior.
- The model was evaluated on standard benchmark datasets for action recognition and violence detection, demonstrating improved performance over previous approaches.
Plain English Explanation
The paper focuses on improving the ability of computer systems to recognize human actions and detect violent behavior. The researchers developed a deep learning model that uses both visual information (like video footage) and audio information (like sounds) to make these determinations.
By combining these two types of data, the model is able to better understand the context and details of human behavior compared to using just one type of information alone. This leads to improved accuracy in recognizing different actions people take and identifying potentially violent situations.
The researchers tested their model on standard datasets used to benchmark action recognition and violence detection systems. Their approach outperformed previous methods, demonstrating the value of fusing visual and audio data for these types of behavior analysis tasks.
Technical Explanation
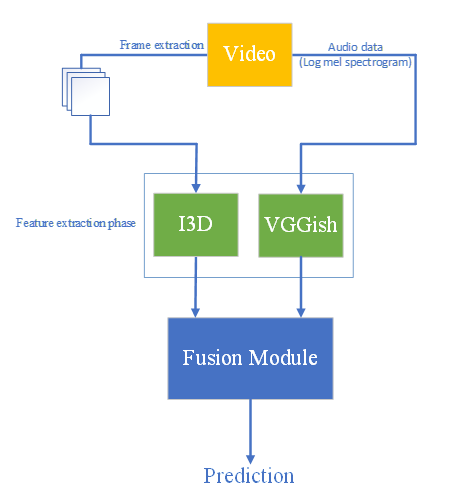
The paper presents a deep learning-based framework for enhancing human action recognition and violence detection through the fusion of audiovisual information. The model architecture consists of separate visual and audio processing streams that extract relevant features from input video and audio data, respectively. These features are then combined and passed through additional neural network layers to produce the final action recognition and violence detection outputs.
The visual processing stream uses a convolutional neural network (CNN) to extract spatial features from video frames, while the audio processing stream utilizes a recurrent neural network (RNN) to capture temporal information from the audio signal. The fused audiovisual features are then processed by a series of fully connected layers to produce the classification results.
The researchers evaluate their approach on standard benchmark datasets for action recognition and violence detection, including NTU RGB+D and Violence in Video in the Wild (ViVID). Their results demonstrate significant improvements in performance compared to previous methods that rely solely on visual or audio information. The audiovisual fusion model achieves higher accuracy in recognizing a broader range of human actions and more reliably detecting violent behavior.
Critical Analysis
The paper provides a compelling demonstration of the benefits of combining visual and audio data for enhancing human action recognition and violence detection. By leveraging the complementary information provided by these modalities, the deep learning model is able to capture more nuanced cues and contextual details that lead to improved classification performance.
However, the paper does not fully address potential limitations or caveats of the proposed approach. For example, it does not explore how the model's performance may be affected by noisy or low-quality audio data, which could be common in real-world scenarios. Additionally, the paper does not discuss the computational efficiency or deployment considerations of the audiovisual fusion architecture, which could be important factors for practical applications.
Further research could also investigate the model's ability to generalize to a wider range of actions and violent behaviors beyond the specific datasets used in the evaluation. Exploring the interpretability of the learned audiovisual features could also provide valuable insights into the model's decision-making process and lead to improved understanding of human behavior.
Conclusion
This paper presents a promising approach for leveraging the power of deep learning and audiovisual data fusion to enhance human action recognition and violence detection. By combining visual and audio information, the model is able to achieve superior performance compared to previous methods that relied on a single modality.
The findings have important implications for a range of applications, such as video surveillance, human-computer interaction, and behavioral analysis. Continued research and development in this area could lead to more accurate and robust systems for understanding and responding to human behavior in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Human Action Recognition and Violence Detection Through Deep Learning Audiovisual Fusion
Pooya Janani (Distributed and Intelligent Optimization Research Laboratory, Dept. of Electrical Engineering, Amirkabir University of Technology, Tehran, Iran), Amirabolfazl Suratgar (Distributed and Intelligent Optimization Research Laboratory, Dept. of Electrical Engineering, Amirkabir University of Technology, Tehran, Iran), Afshin Taghvaeipour (Dept. of Mechanical Engineering, Amirkabir University of Technology, Tehran, Iran)
This paper proposes a hybrid fusion-based deep learning approach based on two different modalities, audio and video, to improve human activity recognition and violence detection in public places. To take advantage of audiovisual fusion, late fusion, intermediate fusion, and hybrid fusion-based deep learning (HFBDL) are used and compared. Since the objective is to detect and recognize human violence in public places, Real-life violence situation (RLVS) dataset is expanded and used. Simulating results of HFBDL show 96.67% accuracy on validation data, which is more accurate than the other state-of-the-art methods on this dataset. To showcase our model's ability in real-world scenarios, another dataset of 54 sounded videos of both violent and non-violent situations was recorded. The model could successfully detect 52 out of 54 videos correctly. The proposed method shows a promising performance on real scenarios. Thus, it can be used for human action recognition and violence detection in public places for security purposes.
Read more8/6/2024
👁️
0
Comparative Analysis: Violence Recognition from Videos using Transfer Learning
Dursun Dashdamirov
Action recognition has become a hot topic in computer vision. However, the main applications of computer vision in video processing have focused on detection of relatively simple actions while complex events such as violence detection have been comparatively less investigated. This study focuses on the benchmarking of various deep learning techniques on a complex dataset. Next, a larger dataset is utilized to test the uplift from increasing volume of data. The dataset size increase from 500 to 1,600 videos resulted in a notable average accuracy improvement of 6% across four models.
Read more8/28/2024
0
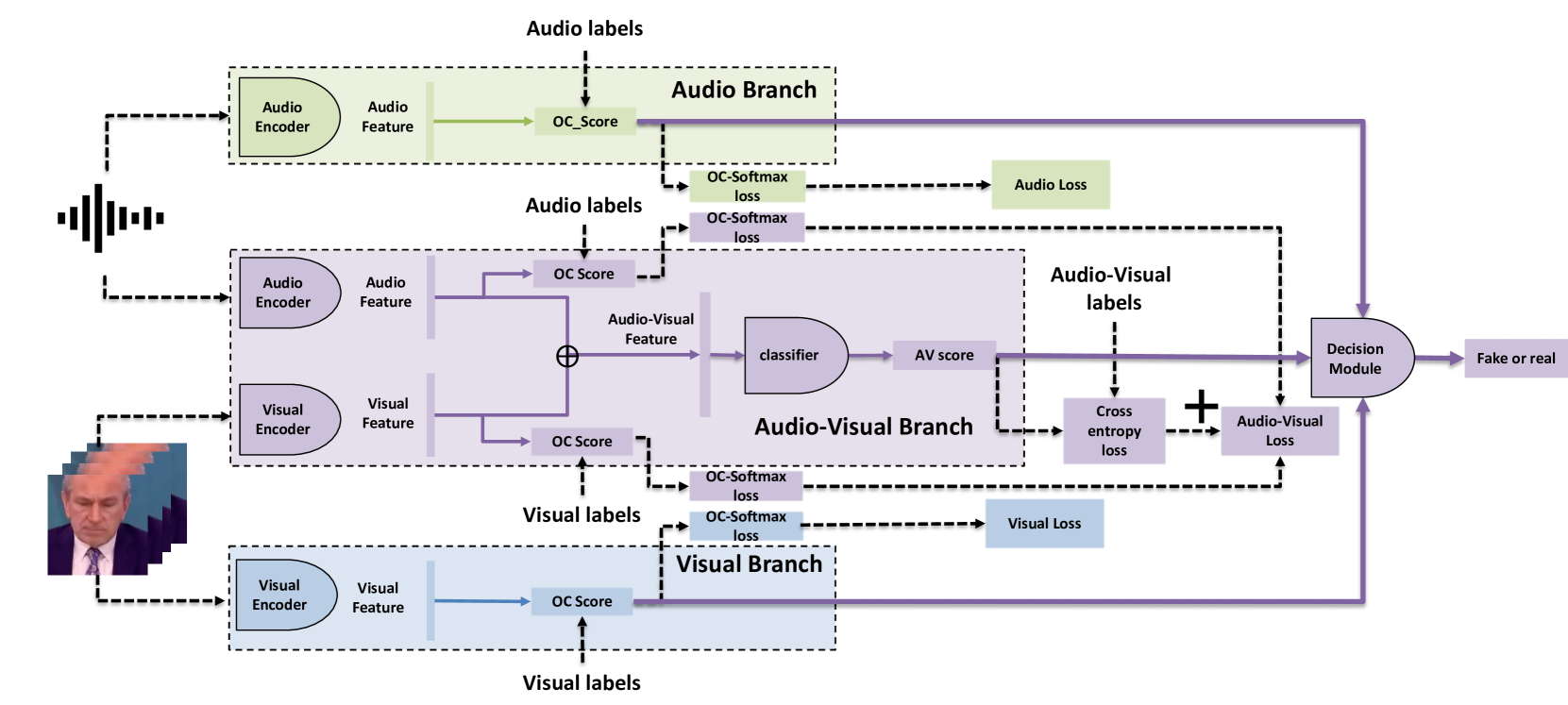
A Multi-Stream Fusion Approach with One-Class Learning for Audio-Visual Deepfake Detection
Kyungbok Lee, You Zhang, Zhiyao Duan
This paper addresses the challenge of developing a robust audio-visual deepfake detection model. In practical use cases, new generation algorithms are continually emerging, and these algorithms are not encountered during the development of detection methods. This calls for the generalization ability of the method. Additionally, to ensure the credibility of detection methods, it is beneficial for the model to interpret which cues from the video indicate it is fake. Motivated by these considerations, we then propose a multi-stream fusion approach with one-class learning as a representation-level regularization technique. We study the generalization problem of audio-visual deepfake detection by creating a new benchmark by extending and re-splitting the existing FakeAVCeleb dataset. The benchmark contains four categories of fake videos (Real Audio-Fake Visual, Fake Audio-Fake Visual, Fake Audio-Real Visual, and Unsynchronized videos). The experimental results demonstrate that our approach surpasses the previous models by a large margin. Furthermore, our proposed framework offers interpretability, indicating which modality the model identifies as more likely to be fake. The source code is released at https://github.com/bok-bok/MSOC.
Read more8/20/2024

0
Violence detection in videos using deep recurrent and convolutional neural networks
Abdarahmane Traor'e, Moulay A. Akhloufi
Violence and abnormal behavior detection research have known an increase of interest in recent years, due mainly to a rise in crimes in large cities worldwide. In this work, we propose a deep learning architecture for violence detection which combines both recurrent neural networks (RNNs) and 2-dimensional convolutional neural networks (2D CNN). In addition to video frames, we use optical flow computed using the captured sequences. CNN extracts spatial characteristics in each frame, while RNN extracts temporal characteristics. The use of optical flow allows to encode the movements in the scenes. The proposed approaches reach the same level as the state-of-the-art techniques and sometime surpass them. It was validated on 3 databases achieving good results.
Read more9/14/2024