A Toolchain for Comprehensive Audio/Video Analysis Using Deep Learning Based Multimodal Approach (A use case of riot or violent context detection)

0

Sign in to get full access
Overview
- Presents a toolchain for comprehensive audio/video analysis using a deep learning-based multimodal approach
- Focuses on a use case of riot or violent context detection
Plain English Explanation
This paper describes a system that can analyze both audio and video data using deep learning techniques to detect whether a situation is potentially violent or involves a riot. The researchers developed a "toolchain" - a set of connected tools and processes - that can take in audio and video inputs, extract relevant features, and then use a deep learning model to classify the content as either "violent/riot" or "non-violent."
The key idea is to combine information from both the audio and video streams, rather than relying on just one or the other. This multimodal approach can potentially provide more accurate and robust classification compared to using a single modality. The researchers also discuss how this system could be used for enhanced content moderation of videos, such as for monitoring user-generated content on social media platforms.
Technical Explanation
The paper presents a toolchain for comprehensive audio/video analysis using a deep learning-based multimodal approach. The key components of the toolchain include:
-
Data Collection and Preprocessing: The researchers collected a dataset of audio and video recordings, which were then preprocessed to extract relevant features.
-
Feature Extraction: Audio features such as sound event detection and video features like object detection were extracted using deep learning models.
-
Multimodal Fusion: The audio and video features were then combined using a multimodal fusion approach to create a unified representation of the input data.
-
Classification: The fused features were then used to train a deep learning model to classify the input as either "violent/riot" or "non-violent."
The researchers evaluated the performance of their toolchain on a dataset of audio and video recordings related to riots and violent situations. They compared the results to other state-of-the-art approaches and found that their multimodal model outperformed single-modal models.
Critical Analysis
The researchers acknowledge several limitations of their work, including the need for a larger and more diverse dataset to improve the generalization of the model. They also note that their toolchain is currently focused on a specific use case of riot or violent context detection, and further research is needed to extend it to other application domains.
Additionally, there are potential ethical concerns around the use of such a system for content moderation, as it could be vulnerable to biases and errors that could lead to the suppression of legitimate speech or the amplification of harmful content. The researchers do not address these issues in depth, and further discussions on the responsible development and deployment of such technologies would be valuable.
Conclusion
This paper presents a comprehensive toolchain for audio/video analysis using a deep learning-based multimodal approach, with a focus on detecting riot or violent contexts. The researchers demonstrate the benefits of combining audio and video information to improve classification performance compared to single-modal approaches.
While the toolchain shows promise, there are still opportunities for further research and development, particularly around addressing the ethical and societal implications of such technologies. As AI-powered content moderation systems become more prevalent, it is crucial to carefully consider the potential risks and develop robust safeguards to protect individual rights and societal well-being.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Toolchain for Comprehensive Audio/Video Analysis Using Deep Learning Based Multimodal Approach (A use case of riot or violent context detection)
Lam Pham, Phat Lam, Tin Nguyen, Hieu Tang, Alexander Schindler
In this paper, we present a toolchain for a comprehensive audio/video analysis by leveraging deep learning based multimodal approach. To this end, different specific tasks of Speech to Text (S2T), Acoustic Scene Classification (ASC), Acoustic Event Detection (AED), Visual Object Detection (VOD), Image Captioning (IC), and Video Captioning (VC) are conducted and integrated into the toolchain. By combining individual tasks and analyzing both audio & visual data extracted from input video, the toolchain offers various audio/video-based applications: Two general applications of audio/video clustering, comprehensive audio/video summary and a specific application of riot or violent context detection. Furthermore, the toolchain presents a flexible and adaptable architecture that is effective to integrate new models for further audio/video-based applications.
Read more7/4/2024
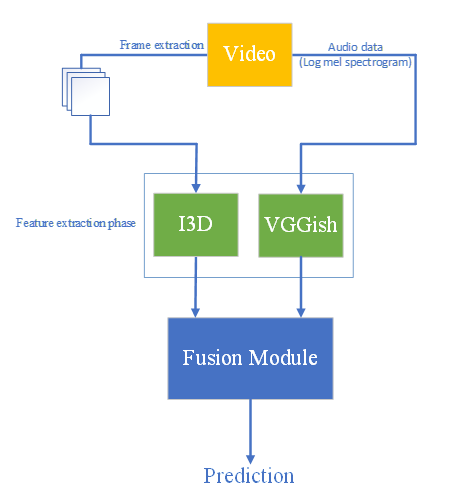
0
Enhancing Human Action Recognition and Violence Detection Through Deep Learning Audiovisual Fusion
Pooya Janani (Distributed and Intelligent Optimization Research Laboratory, Dept. of Electrical Engineering, Amirkabir University of Technology, Tehran, Iran), Amirabolfazl Suratgar (Distributed and Intelligent Optimization Research Laboratory, Dept. of Electrical Engineering, Amirkabir University of Technology, Tehran, Iran), Afshin Taghvaeipour (Dept. of Mechanical Engineering, Amirkabir University of Technology, Tehran, Iran)
This paper proposes a hybrid fusion-based deep learning approach based on two different modalities, audio and video, to improve human activity recognition and violence detection in public places. To take advantage of audiovisual fusion, late fusion, intermediate fusion, and hybrid fusion-based deep learning (HFBDL) are used and compared. Since the objective is to detect and recognize human violence in public places, Real-life violence situation (RLVS) dataset is expanded and used. Simulating results of HFBDL show 96.67% accuracy on validation data, which is more accurate than the other state-of-the-art methods on this dataset. To showcase our model's ability in real-world scenarios, another dataset of 54 sounded videos of both violent and non-violent situations was recorded. The model could successfully detect 52 out of 54 videos correctly. The proposed method shows a promising performance on real scenarios. Thus, it can be used for human action recognition and violence detection in public places for security purposes.
Read more8/6/2024
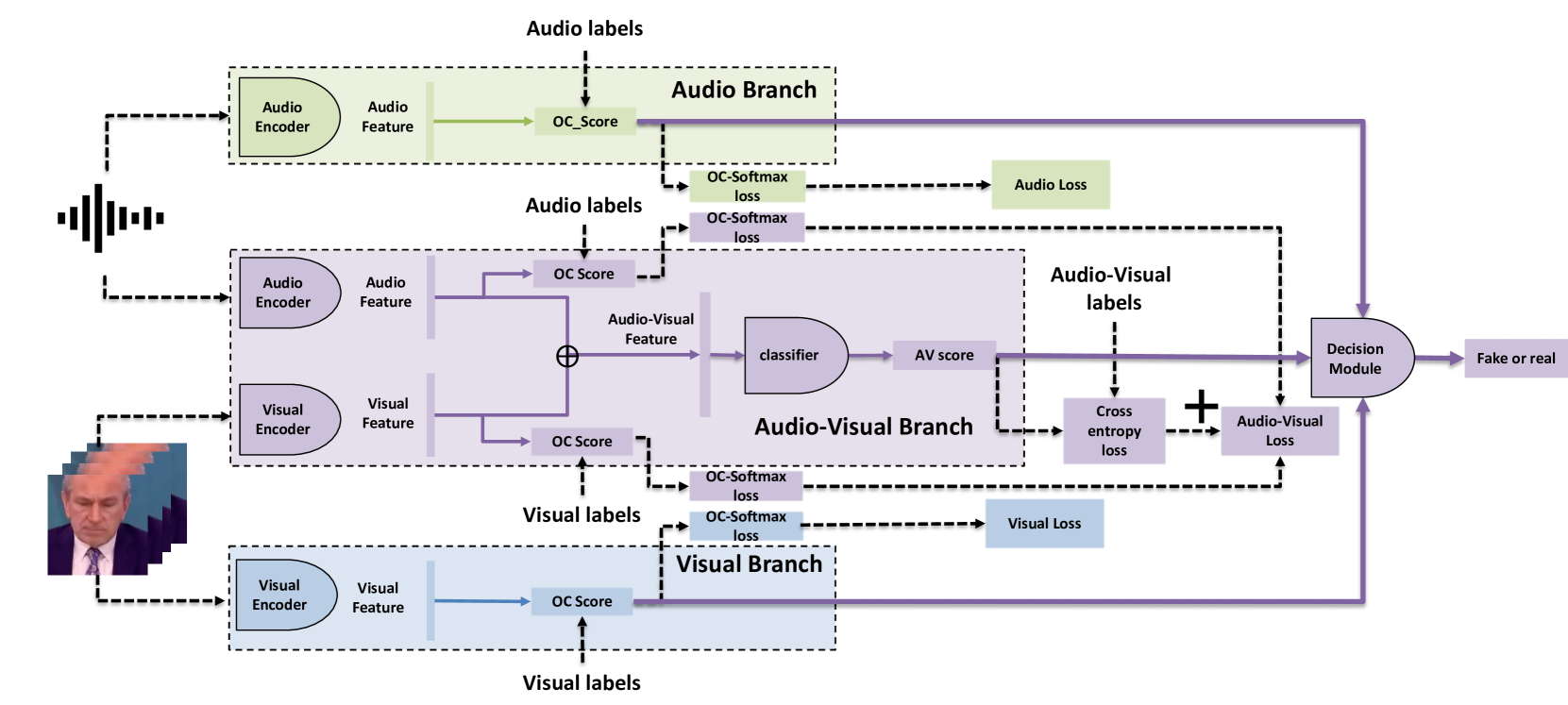
0
A Multi-Stream Fusion Approach with One-Class Learning for Audio-Visual Deepfake Detection
Kyungbok Lee, You Zhang, Zhiyao Duan
This paper addresses the challenge of developing a robust audio-visual deepfake detection model. In practical use cases, new generation algorithms are continually emerging, and these algorithms are not encountered during the development of detection methods. This calls for the generalization ability of the method. Additionally, to ensure the credibility of detection methods, it is beneficial for the model to interpret which cues from the video indicate it is fake. Motivated by these considerations, we then propose a multi-stream fusion approach with one-class learning as a representation-level regularization technique. We study the generalization problem of audio-visual deepfake detection by creating a new benchmark by extending and re-splitting the existing FakeAVCeleb dataset. The benchmark contains four categories of fake videos (Real Audio-Fake Visual, Fake Audio-Fake Visual, Fake Audio-Real Visual, and Unsynchronized videos). The experimental results demonstrate that our approach surpasses the previous models by a large margin. Furthermore, our proposed framework offers interpretability, indicating which modality the model identifies as more likely to be fake. The source code is released at https://github.com/bok-bok/MSOC.
Read more8/20/2024

0
New!Efficient Video to Audio Mapper with Visual Scene Detection
Mingjing Yi, Ming Li
Video-to-audio (V2A) generation aims to produce corresponding audio given silent video inputs. This task is particularly challenging due to the cross-modality and sequential nature of the audio-visual features involved. Recent works have made significant progress in bridging the domain gap between video and audio, generating audio that is semantically aligned with the video content. However, a critical limitation of these approaches is their inability to effectively recognize and handle multiple scenes within a video, often leading to suboptimal audio generation in such cases. In this paper, we first reimplement a state-of-the-art V2A model with a slightly modified light-weight architecture, achieving results that outperform the baseline. We then propose an improved V2A model that incorporates a scene detector to address the challenge of switching between multiple visual scenes. Results on VGGSound show that our model can recognize and handle multiple scenes within a video and achieve superior performance against the baseline for both fidelity and relevance.
Read more9/17/2024