Enhancing Language Model Factuality via Activation-Based Confidence Calibration and Guided Decoding

0

Sign in to get full access
Overview
- This paper proposes techniques to improve the factual accuracy and reliability of large language models (LLMs)
- It introduces "activation-based confidence calibration" and "entropy-guided decoding" to enhance the truthfulness of LLM outputs
- The methods aim to make LLMs more trustworthy and robust, addressing concerns around their current tendency to generate plausible-sounding but factually incorrect information
Plain English Explanation
Large language models (LLMs) like GPT-3 have become incredibly powerful at generating human-like text. However, they can sometimes produce information that sounds convincing but is actually false or misleading. This is a significant concern as these models are increasingly being used for high-stakes applications.
The researchers behind this paper have developed two key techniques to address this issue. The first is activation-based confidence calibration, which allows the model to better assess how confident it is in the accuracy of its own outputs. This helps the model refrain from making claims it is unsure about.
The second technique is entropy-guided decoding, which steers the model's text generation towards more factual and truthful outputs. By considering the "uncertainty" or "randomness" of the model's predictions, the system can nudge the text in a more reliable direction.
These methods aim to make LLMs more trustworthy and robust, so that users can rely on the information they generate. The paper demonstrates how these techniques can improve factual accuracy across a range of language tasks, from question answering to open-ended text generation.
Ultimately, this research is an important step towards building AI systems that are not only highly capable, but also reliable and aligned with human values. As LLMs become more ubiquitous, ensuring their truthfulness will be crucial for maintaining public trust and realizing the full potential of these transformative technologies.
Technical Explanation
The paper introduces two key innovations to enhance the factual reliability of large language models (LLMs):
-
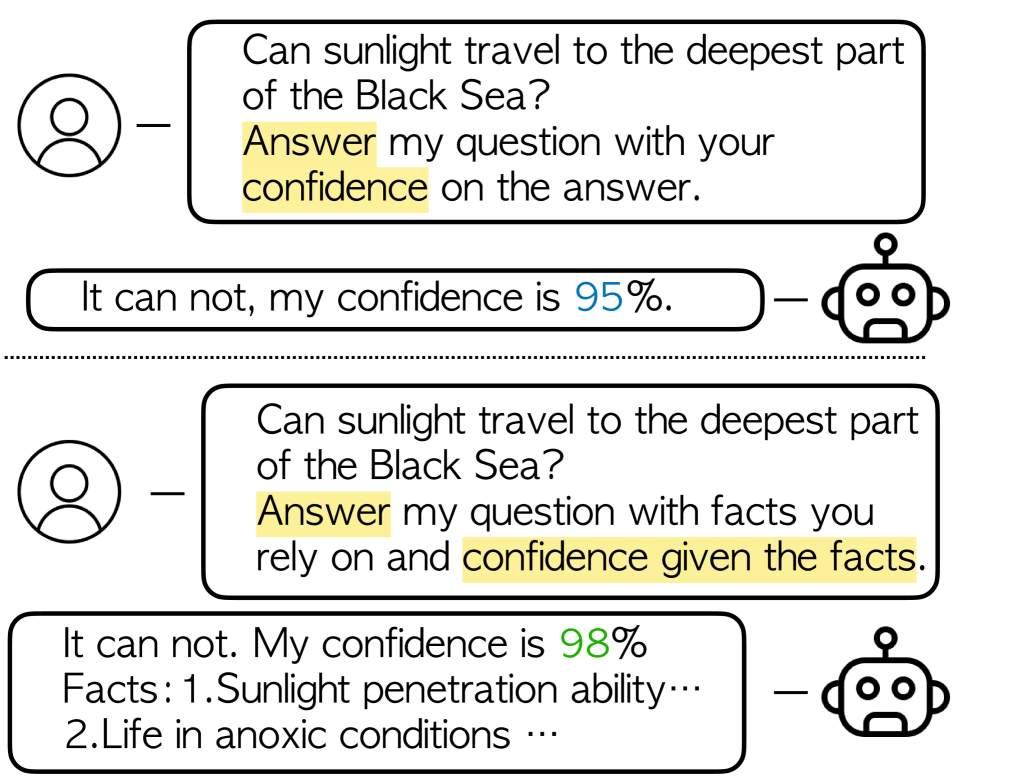
Activation-Based Confidence Calibration: The researchers develop a technique to calibrate the model's own assessment of its confidence in the accuracy of its outputs. By analyzing the internal "activations" of the model during generation, they can estimate how certain the model is about a given prediction. This allows the model to express appropriate levels of certainty, rather than making overconfident or underconfident claims.
This builds on prior work on confidence calibration for language models and factual confidence estimation.
-
Entropy-Guided Decoding: The paper also introduces a novel decoding technique that steers the model's text generation towards more factual and truthful outputs. By considering the "entropy" or uncertainty of the model's predictions at each step, the system can guide the generation process to avoid overly speculative or fictitious content.
This approach is inspired by prior research on entropy-guided decoding and multicalibration for confidence scoring in LLMs.
The paper evaluates these techniques on a range of language tasks, including open-ended text generation, question answering, and fact-checking. The results demonstrate significant improvements in factual accuracy and reliability, without compromising the models' overall performance.
Critical Analysis
The paper presents a thoughtful and technically robust approach to enhancing the factual reliability of large language models. The proposed techniques of activation-based confidence calibration and entropy-guided decoding are well-grounded in prior research and show promising empirical results.
However, the authors acknowledge several limitations and areas for further exploration. For example, the methods may struggle with rare or out-of-distribution inputs, and the confidence estimation could be further improved. Additionally, the paper does not address potential biases or societal impacts that could arise from these techniques.
It would be valuable for future work to investigate the broader implications of these approaches, particularly as LLMs become more widely deployed. Ensuring the truthfulness and trustworthiness of these models is crucial, but must be balanced against other important considerations like fairness, transparency, and alignment with human values.
Overall, this paper makes a significant contribution to the growing field of responsible AI development. The techniques proposed here represent an important step towards building language models that are not only highly capable, but also reliably truthful and aligned with human interests.
Conclusion
This paper presents innovative methods to enhance the factual accuracy and reliability of large language models (LLMs). By introducing activation-based confidence calibration and entropy-guided decoding, the researchers have developed techniques to help LLMs better assess and express their own certainty, as well as generate more truthful and trustworthy outputs.
As LLMs become increasingly prevalent in high-stakes applications, ensuring their factual reliability is critical. The approaches described in this paper represent an important step towards building AI systems that are not only powerful, but also aligned with human values and deserving of user trust.
While the proposed methods have limitations and require further exploration, this work demonstrates the potential to create more responsible and trustworthy language models. Continued research in this direction will be essential for realizing the full societal benefits of transformative AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Language Model Factuality via Activation-Based Confidence Calibration and Guided Decoding
Xin Liu, Farima Fatahi Bayat, Lu Wang
Calibrating language models (LMs) aligns their generation confidence with the actual likelihood of answer correctness, which can inform users about LMs' reliability and mitigate hallucinated content. However, prior calibration methods, such as self-consistency-based and logit-based approaches, are either limited in inference-time efficiency or fall short of providing informative signals. Moreover, simply filtering out low-confidence responses reduces the LM's helpfulness when the answers are correct. Therefore, effectively using calibration techniques to enhance an LM's factuality remains an unsolved challenge. In this paper, we first propose an activation-based calibration method, ActCab, which trains a linear layer on top of the LM's last-layer activations that can better capture the representations of knowledge. Built on top of ActCab, we further propose CoDec, a confidence-guided decoding strategy to elicit truthful answers with high confidence from LMs. By evaluating on five popular QA benchmarks, ActCab achieves superior calibration performance than all competitive baselines, e.g., by reducing the average expected calibration error (ECE) score by up to 39%. Further experiments on CoDec show consistent improvements in several LMs' factuality on challenging QA datasets, such as TruthfulQA, highlighting the value of confidence signals in enhancing factuality.
Read more6/21/2024
🔮
0
On the Calibration of Multilingual Question Answering LLMs
Yahan Yang, Soham Dan, Dan Roth, Insup Lee
Multilingual pre-trained Large Language Models (LLMs) are incredibly effective at Question Answering (QA), a core task in Natural Language Understanding, achieving high accuracies on several multilingual benchmarks. However, little is known about how well their confidences are calibrated. In this paper, we comprehensively benchmark the calibration of several multilingual LLMs (MLLMs) on a variety of QA tasks. We perform extensive experiments, spanning encoder-only, encoder-decoder, and decoder-only QA models (size varying from 110M to 7B parameters) and diverse languages, including both high- and low-resource ones. We study different dimensions of calibration in in-distribution, out-of-distribution, and cross-lingual transfer settings, and investigate strategies to improve it, including post-hoc methods and regularized fine-tuning. For decoder-only LLMs such as LlaMa2, we additionally find that in-context learning improves confidence calibration on multilingual data. We also conduct several ablation experiments to study the effect of language distances, language corpus size, and model size on calibration, and how multilingual models compare with their monolingual counterparts for diverse tasks and languages. Our experiments suggest that the multilingual QA models are poorly calibrated for languages other than English and incorporating a small set of cheaply translated multilingual samples during fine-tuning/calibration effectively enhances the calibration performance.
Read more4/16/2024
0
Fact-and-Reflection (FaR) Improves Confidence Calibration of Large Language Models
Xinran Zhao, Hongming Zhang, Xiaoman Pan, Wenlin Yao, Dong Yu, Tongshuang Wu, Jianshu Chen
For a LLM to be trustworthy, its confidence level should be well-calibrated with its actual performance. While it is now common sense that LLM performances are greatly impacted by prompts, the confidence calibration in prompting LLMs has yet to be thoroughly explored. In this paper, we explore how different prompting strategies influence LLM confidence calibration and how it could be improved. We conduct extensive experiments on six prompting methods in the question-answering context and we observe that, while these methods help improve the expected LLM calibration, they also trigger LLMs to be over-confident when responding to some instances. Inspired by human cognition, we propose Fact-and-Reflection (FaR) prompting, which improves the LLM calibration in two steps. First, FaR elicits the known facts that are relevant to the input prompt from the LLM. And then it asks the model to reflect over them to generate the final answer. Experiments show that FaR prompting achieves significantly better calibration; it lowers the Expected Calibration Error by 23.5% on our multi-purpose QA tasks. Notably, FaR prompting even elicits the capability of verbally expressing concerns in less confident scenarios, which helps trigger retrieval augmentation for solving these harder instances.
Read more9/10/2024

0
Causal-Guided Active Learning for Debiasing Large Language Models
Li Du, Zhouhao Sun, Xiao Ding, Yixuan Ma, Yang Zhao, Kaitao Qiu, Ting Liu, Bing Qin
Although achieving promising performance, recent analyses show that current generative large language models (LLMs) may still capture dataset biases and utilize them for generation, leading to poor generalizability and harmfulness of LLMs. However, due to the diversity of dataset biases and the over-optimization problem, previous prior-knowledge-based debiasing methods and fine-tuning-based debiasing methods may not be suitable for current LLMs. To address this issue, we explore combining active learning with the causal mechanisms and propose a casual-guided active learning (CAL) framework, which utilizes LLMs itself to automatically and autonomously identify informative biased samples and induce the bias patterns. Then a cost-effective and efficient in-context learning based method is employed to prevent LLMs from utilizing dataset biases during generation. Experimental results show that CAL can effectively recognize typical biased instances and induce various bias patterns for debiasing LLMs.
Read more9/2/2024