Fact-and-Reflection (FaR) Improves Confidence Calibration of Large Language Models

0
Sign in to get full access
Overview
- The paper investigates how different prompting strategies influence the confidence calibration of large language models (LLMs).
- The authors propose a new prompting strategy called "Fact-and-Reflection" (FaR) that improves the confidence calibration of LLMs.
- Confidence calibration refers to how well an LLM's predicted confidence aligns with its actual accuracy.
Plain English Explanation
The paper examines how the way you ask a large language model (LLM) a question can affect how confident the model is in its answer, and how accurate that confidence level is. The researchers developed a new way of asking questions, called "Fact-and-Reflection" (FaR), that helps make the LLM's confidence level better match its actual accuracy. This is important because it means the user can better trust the model's predictions and decision-making.
Technical Explanation
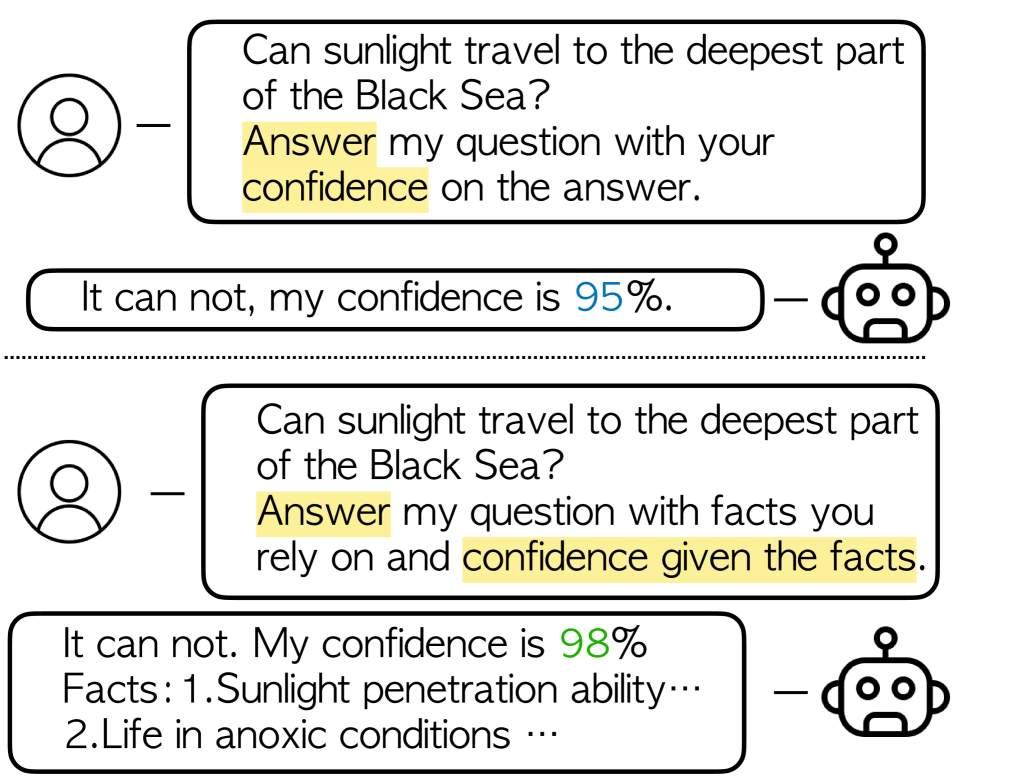
The paper investigates how different prompting strategies influence the confidence calibration of large language models (LLMs). Confidence calibration refers to how well an LLM's predicted confidence aligns with its actual accuracy. The authors propose a new prompting strategy called "Fact-and-Reflection" (FaR) and evaluate its impact on the confidence calibration of several state-of-the-art LLMs, including GPT-3, PaLM, and Chinchilla. The FaR prompting approach involves first asking the model to state a "fact" about a given topic, and then asking it to reflect on and evaluate the confidence of that fact. The authors find that the FaR prompting strategy significantly improves the confidence calibration of the tested LLMs compared to standard prompting approaches.
Critical Analysis
The paper provides a thorough and well-designed evaluation of the FaR prompting strategy. The authors acknowledge some limitations, such as the potential generalization challenges of the approach and the need for further research on the underlying mechanisms driving the improved confidence calibration. Additionally, the paper does not explore how the FaR prompting strategy may interact with or complement other approaches for enhancing LLM factuality and reliability. Further research could investigate these areas.
Conclusion
This paper presents a novel prompting strategy called "Fact-and-Reflection" (FaR) that significantly improves the confidence calibration of large language models. By asking models to first state a fact and then reflect on their confidence in that fact, the FaR approach helps align the model's predicted confidence with its actual accuracy. This is an important step towards developing more trustworthy and reliable language AI systems that can be confidently deployed in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fact-and-Reflection (FaR) Improves Confidence Calibration of Large Language Models
Xinran Zhao, Hongming Zhang, Xiaoman Pan, Wenlin Yao, Dong Yu, Tongshuang Wu, Jianshu Chen
For a LLM to be trustworthy, its confidence level should be well-calibrated with its actual performance. While it is now common sense that LLM performances are greatly impacted by prompts, the confidence calibration in prompting LLMs has yet to be thoroughly explored. In this paper, we explore how different prompting strategies influence LLM confidence calibration and how it could be improved. We conduct extensive experiments on six prompting methods in the question-answering context and we observe that, while these methods help improve the expected LLM calibration, they also trigger LLMs to be over-confident when responding to some instances. Inspired by human cognition, we propose Fact-and-Reflection (FaR) prompting, which improves the LLM calibration in two steps. First, FaR elicits the known facts that are relevant to the input prompt from the LLM. And then it asks the model to reflect over them to generate the final answer. Experiments show that FaR prompting achieves significantly better calibration; it lowers the Expected Calibration Error by 23.5% on our multi-purpose QA tasks. Notably, FaR prompting even elicits the capability of verbally expressing concerns in less confident scenarios, which helps trigger retrieval augmentation for solving these harder instances.
Read more9/10/2024

0
Enhancing Language Model Factuality via Activation-Based Confidence Calibration and Guided Decoding
Xin Liu, Farima Fatahi Bayat, Lu Wang
Calibrating language models (LMs) aligns their generation confidence with the actual likelihood of answer correctness, which can inform users about LMs' reliability and mitigate hallucinated content. However, prior calibration methods, such as self-consistency-based and logit-based approaches, are either limited in inference-time efficiency or fall short of providing informative signals. Moreover, simply filtering out low-confidence responses reduces the LM's helpfulness when the answers are correct. Therefore, effectively using calibration techniques to enhance an LM's factuality remains an unsolved challenge. In this paper, we first propose an activation-based calibration method, ActCab, which trains a linear layer on top of the LM's last-layer activations that can better capture the representations of knowledge. Built on top of ActCab, we further propose CoDec, a confidence-guided decoding strategy to elicit truthful answers with high confidence from LMs. By evaluating on five popular QA benchmarks, ActCab achieves superior calibration performance than all competitive baselines, e.g., by reducing the average expected calibration error (ECE) score by up to 39%. Further experiments on CoDec show consistent improvements in several LMs' factuality on challenging QA datasets, such as TruthfulQA, highlighting the value of confidence signals in enhancing factuality.
Read more6/21/2024

0
Self-Reflection Outcome is Sensitive to Prompt Construction
Fengyuan Liu, Nouar AlDahoul, Gregory Eady, Yasir Zaki, Bedoor AlShebli, Talal Rahwan
Large language models (LLMs) demonstrate impressive zero-shot and few-shot reasoning capabilities. Some propose that such capabilities can be improved through self-reflection, i.e., letting LLMs reflect on their own output to identify and correct mistakes in the initial responses. However, despite some evidence showing the benefits of self-reflection, recent studies offer mixed results. Here, we aim to reconcile these conflicting findings by first demonstrating that the outcome of self-reflection is sensitive to prompt wording; e.g., LLMs are more likely to conclude that it has made a mistake when explicitly prompted to find mistakes. Consequently, idiosyncrasies in reflection prompts may lead LLMs to change correct responses unnecessarily. We show that most prompts used in the self-reflection literature are prone to this bias. We then propose different ways of constructing prompts that are conservative in identifying mistakes and show that self-reflection using such prompts results in higher accuracy. Our findings highlight the importance of prompt engineering in self-reflection tasks. We release our code at https://github.com/Michael98Liu/mixture-of-prompts.
Read more6/18/2024

0
FaaF: Facts as a Function for the evaluation of generated text
Vasileios Katranidis, Gabor Barany
The demand for accurate and efficient verification of information in texts generated by large language models (LMs) is at an all-time high, but remains unresolved. Recent efforts have focused on extracting and verifying atomic facts from these texts via prompting LM evaluators. However, we demonstrate that this method of prompting is unreliable when faced with incomplete or inaccurate reference information. We introduce Facts as a Function (FaaF), a new approach to the fact verification task that leverages the function-calling capabilities of LMs. FaaF significantly enhances the ability of LMs to identify unsupported facts in texts, while also improving efficiency and significantly lowering costs compared to prompt-based methods. Additionally, we propose a framework for evaluating factual recall in Retrieval Augmented Generation (RAG) systems, which we employ to compare prompt-based and FaaF methods using various LMs under challenging conditions.
Read more4/9/2024