Enhancing Semantic Similarity Understanding in Arabic NLP with Nested Embedding Learning

0
Sign in to get full access
Overview
- The research paper explores enhancing semantic similarity understanding in Arabic natural language processing (NLP) using a novel technique called Nested Embedding Learning.
- The key objective is to improve the performance of Arabic NLP models on tasks that require deep semantic understanding, such as question answering and text summarization.
- The proposed approach leverages cross-lingual transfer learning to capture richer semantic representations for Arabic words and phrases.
Plain English Explanation
The researchers developed a new method called Nested Embedding Learning to help Arabic NLP models better understand the meaning and relationships between words and phrases. This is important for tasks like answering questions or summarizing text, where having a deep grasp of the semantics is crucial.
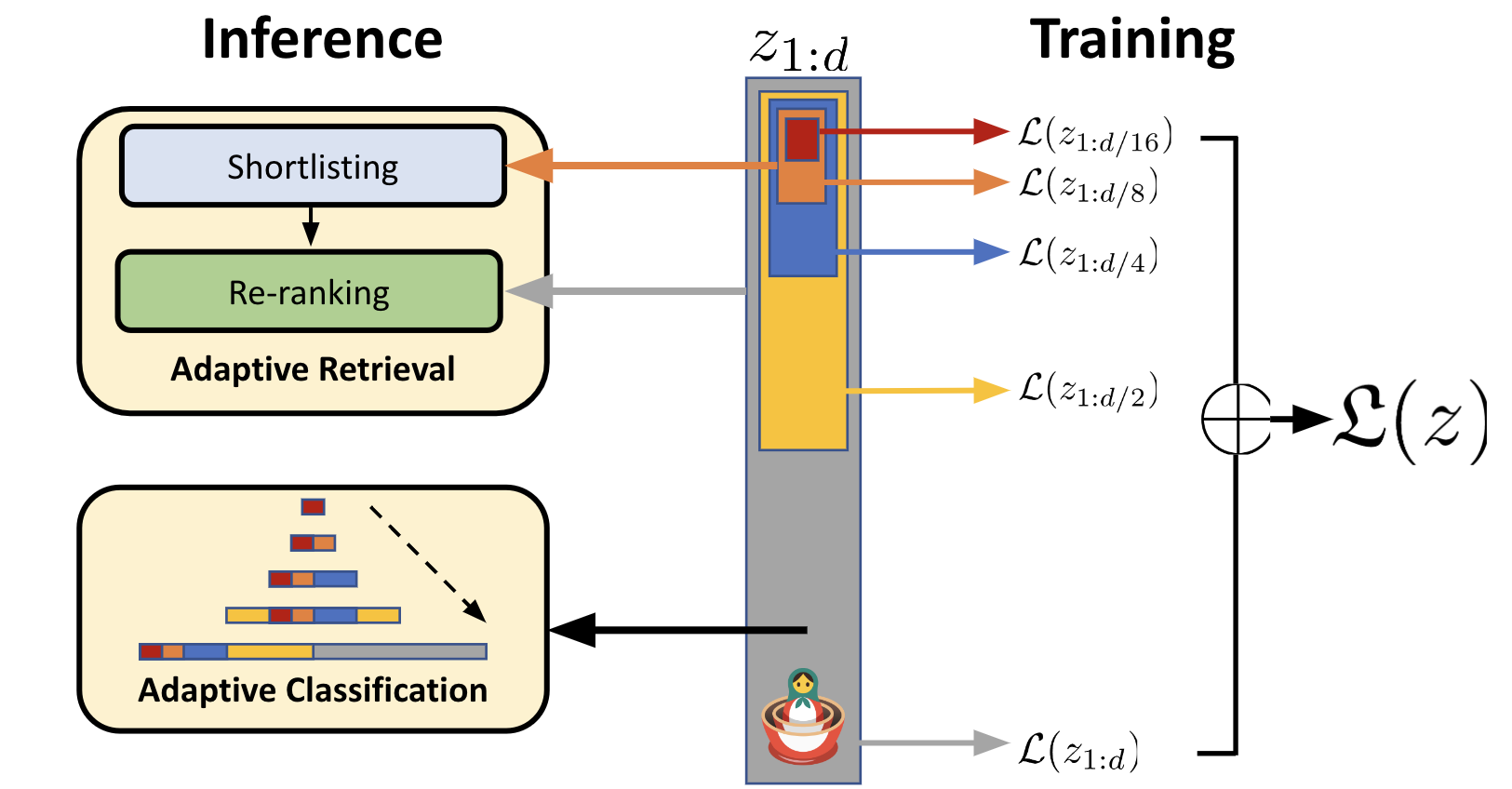
The core idea is to leverage cross-lingual transfer learning - using knowledge gained from studying other languages to enhance the Arabic models. By learning nested embeddings, where wider context is used to refine the meaning of individual words, the models can capture richer semantic representations for Arabic.
This is a bit like how when we learn a new word, we rely on the surrounding words and phrases to fully understand its meaning. The researchers aimed to mimic this process in their Matryoshka Learning approach, where the model learns progressively deeper levels of semantic understanding.
By enhancing the Arabic NLP models in this way, the researchers hope to improve performance on tasks that require genuine comprehension of the language, going beyond just surface-level pattern matching.
Technical Explanation
The key innovation in this work is the Nested Embedding Learning technique, which builds on ideas from multilingual de-duplication strategies and Matryoshka Learning.
The core architecture consists of a Nested Embedding Module that takes an Arabic input sequence and produces a hierarchy of increasingly refined embeddings. This allows the model to capture both local and global semantic relationships. The nested embeddings are then used as input to downstream NLP tasks.
The training process involves GEMMAR instruction tuning to fine-tune the model on Arabic-specific linguistic knowledge. This helps the nested embeddings better reflect the nuances of the Arabic language.
Through extensive experiments on standard Arabic NLP benchmarks, the authors demonstrate significant performance gains compared to previous state-of-the-art approaches. The nested embeddings proved especially valuable for tasks requiring deep semantic understanding, such as question answering and text summarization.
Critical Analysis
The researchers acknowledge several limitations and areas for further exploration:
-
The performance improvements, while substantial, are still constrained by the quality and coverage of the training data available for Arabic NLP. Expanding and diversifying Arabic language resources could further boost the model's capabilities.
-
The nested embedding approach adds complexity to the model architecture, which could impact inference speed and computational efficiency. Balancing model complexity with performance is an important consideration.
-
While the cross-lingual transfer learning component is a key strength, the extent to which the nested embeddings can capture uniquely Arabic semantic properties remains an open question. Deeper analysis of the learned representations is warranted.
-
The evaluation focused on standard benchmarks, but real-world Arabic NLP applications may surface additional challenges not reflected in these test sets. Rigorous real-world deployment and testing would be valuable.
Overall, this work represents a promising step forward in enhancing semantic understanding for Arabic NLP. The nested embedding approach offers an innovative way to leverage cross-lingual knowledge while adapting to the nuances of the Arabic language.
Conclusion
The Nested Embedding Learning technique introduced in this paper offers a novel approach to improving semantic similarity understanding in Arabic natural language processing. By leveraging cross-lingual transfer learning and progressively refining word embeddings, the model is able to capture richer semantic representations that boost performance on tasks requiring deep language comprehension.
While there are still avenues for further research and optimization, this work demonstrates the potential of this approach to advance the state-of-the-art in Arabic NLP. As Arabic continues to grow in global importance, innovations like this will be crucial for developing more capable and reliable language AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Semantic Similarity Understanding in Arabic NLP with Nested Embedding Learning
Omer Nacar, Anis Koubaa
This work presents a novel framework for training Arabic nested embedding models through Matryoshka Embedding Learning, leveraging multilingual, Arabic-specific, and English-based models, to highlight the power of nested embeddings models in various Arabic NLP downstream tasks. Our innovative contribution includes the translation of various sentence similarity datasets into Arabic, enabling a comprehensive evaluation framework to compare these models across different dimensions. We trained several nested embedding models on the Arabic Natural Language Inference triplet dataset and assessed their performance using multiple evaluation metrics, including Pearson and Spearman correlations for cosine similarity, Manhattan distance, Euclidean distance, and dot product similarity. The results demonstrate the superior performance of the Matryoshka embedding models, particularly in capturing semantic nuances unique to the Arabic language. Results demonstrated that Arabic Matryoshka embedding models have superior performance in capturing semantic nuances unique to the Arabic language, significantly outperforming traditional models by up to 20-25% across various similarity metrics. These results underscore the effectiveness of language-specific training and highlight the potential of Matryoshka models in enhancing semantic textual similarity tasks for Arabic NLP.
Read more8/2/2024

131
Matryoshka-Adaptor: Unsupervised and Supervised Tuning for Smaller Embedding Dimensions
Jinsung Yoon, Raj Sinha, Sercan O Arik, Tomas Pfister
Embeddings from Large Language Models (LLMs) have emerged as critical components in various applications, particularly for information retrieval. While high-dimensional embeddings generally demonstrate superior performance as they contain more salient information, their practical application is frequently hindered by elevated computational latency and the associated higher cost. To address these challenges, we propose Matryoshka-Adaptor, a novel tuning framework designed for the customization of LLM embeddings. Matryoshka-Adaptor facilitates substantial dimensionality reduction while maintaining comparable performance levels, thereby achieving a significant enhancement in computational efficiency and cost-effectiveness. Our framework directly modifies the embeddings from pre-trained LLMs which is designed to be seamlessly integrated with any LLM architecture, encompassing those accessible exclusively through black-box APIs. Also, it exhibits efficacy in both unsupervised and supervised learning settings. A rigorous evaluation conducted across a diverse corpus of English, multilingual, and multimodal datasets consistently reveals substantial gains with Matryoshka-Adaptor. Notably, with Google and OpenAI Embedding APIs, Matryoshka-Adaptor achieves a reduction in dimensionality ranging from two- to twelve-fold without compromising performance across multiple BEIR datasets.
Read more7/31/2024
🤔
4
Contrastive Learning and Mixture of Experts Enables Precise Vector Embeddings
Logan Hallee, Rohan Kapur, Arjun Patel, Jason P. Gleghorn, Bohdan Khomtchouk
The advancement of transformer neural networks has significantly elevated the capabilities of sentence similarity models, but they struggle with highly discriminative tasks and produce sub-optimal representations of important documents like scientific literature. With the increased reliance on retrieval augmentation and search, representing diverse documents as concise and descriptive vectors is crucial. This paper improves upon the vectors embeddings of scientific literature by assembling niche datasets using co-citations as a similarity metric, focusing on biomedical domains. We apply a novel Mixture of Experts (MoE) extension pipeline to pretrained BERT models, where every multi-layer perceptron section is enlarged and copied into multiple distinct experts. Our MoE variants perform well over $N$ scientific domains with $N$ dedicated experts, whereas standard BERT models excel in only one domain. Notably, extending just a single transformer block to MoE captures 85% of the benefit seen from full MoE extension at every layer. This holds promise for versatile and efficient One-Size-Fits-All transformer networks for numerically representing diverse inputs. Our methodology marks significant advancements in representing scientific text and holds promise for enhancing vector database search and compilation.
Read more6/3/2024

0
New!jina-embeddings-v3: Multilingual Embeddings With Task LoRA
Saba Sturua, Isabelle Mohr, Mohammad Kalim Akram, Michael Gunther, Bo Wang, Markus Krimmel, Feng Wang, Georgios Mastrapas, Andreas Koukounas, Andreas Koukounas, Nan Wang, Han Xiao
We introduce jina-embeddings-v3, a novel text embedding model with 570 million parameters, achieves state-of-the-art performance on multilingual data and long-context retrieval tasks, supporting context lengths of up to 8192 tokens. The model includes a set of task-specific Low-Rank Adaptation (LoRA) adapters to generate high-quality embeddings for query-document retrieval, clustering, classification, and text matching. Additionally, Matryoshka Representation Learning is integrated into the training process, allowing flexible truncation of embedding dimensions without compromising performance. Evaluation on the MTEB benchmark shows that jina-embeddings-v3 outperforms the latest proprietary embeddings from OpenAI and Cohere on English tasks, while achieving superior performance compared to multilingual-e5-large-instruct across all multilingual tasks.
Read more9/17/2024