Multilingual De-Duplication Strategies: Applying scalable similarity search with monolingual & multilingual embedding models

0
🐍
Sign in to get full access
Overview
- Compares two methods for deduplicating multilingual text data: a two-step approach involving translation to English and embedding, and a multilingual embedding model
- The two-step approach achieved higher performance, especially for less widely used languages
- Highlights limitations related to token length constraints and computational efficiency
- Suggests potential improvements for future multilingual deduplication tasks
Plain English Explanation
This research paper explores ways to identify and remove duplicate text content across multiple languages. The researchers tested two different approaches:
-
Translate to English, then embed: First, they translated the text from various languages into English. Then, they used a powerful language model called mpnet to create numerical representations (called embeddings) of the English text. These embeddings were then used to identify duplicate content.
-
Use a multilingual embedding model: In this approach, the researchers used a single multilingual embedding model called distiluse to create embeddings directly from the original text in multiple languages.
The two-step "translate to English, then embed" approach performed better overall, achieving an 82% accuracy score compared to 60% for the multilingual embedding model. This was especially true for less commonly used languages.
The researchers also found they could further boost the performance of the two-step approach up to 89% by adding some expert rules based on domain knowledge. However, they noted some limitations, such as constraints on the length of text that can be processed and the computational resources required.
The insights from this research could help improve multilingual natural language processing systems and make it easier to identify duplicate content across languages.
Technical Explanation
The researchers compared two approaches for deduplicating multilingual text data:
-
Two-step method: First, they used machine translation to convert the text from various languages into English. They then used the mpnet language model to generate numerical embeddings of the English text, which were used to identify duplicate content.
-
Multilingual embedding model: In this approach, the researchers used a single distiluse multilingual embedding model to directly generate embeddings from the original text in multiple languages.
The experiments showed that the two-step "translate to English, then embed" method achieved a higher F1 score of 82%, compared to 60% for the multilingual embedding model. This advantage was particularly pronounced for less widely used languages.
Additionally, the researchers found they could further improve the performance of the two-step approach up to 89% by incorporating expert rules based on domain knowledge.
However, the paper also highlights some limitations of the approaches, such as constraints on the maximum length of text that can be processed and the computational resources required.
Critical Analysis
The paper provides a thorough comparison of two approaches for multilingual text deduplication, with a focus on the trade-offs between performance and computational efficiency.
While the two-step "translate to English, then embed" method demonstrated superior accuracy, especially for less widely used languages, the researchers acknowledge that this approach may not be practical in all scenarios due to the computational costs and token length constraints.
As noted in other research, the quality and reliability of machine translation can also be a concern, especially for low-resource languages. This could potentially introduce additional errors or biases into the deduplication process.
Additionally, the researchers do not explore the impact of domain-specific knowledge or the availability of parallel training data on the performance of the multilingual embedding model. These factors may play a significant role in real-world applications and warrant further investigation.
Overall, the paper provides valuable insights into the trade-offs and limitations of different approaches to multilingual text deduplication, which can inform the design of more robust and efficient solutions in the future.
Conclusion
This research paper compares two methods for deduplicating multilingual text data: a two-step approach involving translation to English and embedding, and a multilingual embedding model. The findings suggest that the two-step method can achieve higher performance, especially for less widely used languages, by leveraging the power of language models like mpnet.
However, the paper also highlights important limitations related to computational efficiency and token length constraints. The researchers suggest that incorporating domain-specific expert rules can further improve the performance of the two-step approach, but more work is needed to develop scalable and practical solutions for real-world multilingual deduplication tasks.
The insights from this research can help inform the development of more robust and effective multilingual natural language processing systems that can accurately identify and remove duplicate content across a diverse range of languages.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
0
Multilingual De-Duplication Strategies: Applying scalable similarity search with monolingual & multilingual embedding models
Stefan Pasch, Dimitirios Petridis, Jannic Cutura
This paper addresses the deduplication of multilingual textual data using advanced NLP tools. We compare a two-step method involving translation to English followed by embedding with mpnet, and a multilingual embedding model (distiluse). The two-step approach achieved a higher F1 score (82% vs. 60%), particularly with less widely used languages, which can be increased up to 89% by leveraging expert rules based on domain knowledge. We also highlight limitations related to token length constraints and computational efficiency. Our methodology suggests improvements for future multilingual deduplication tasks.
Read more6/21/2024

0
SoftDedup: an Efficient Data Reweighting Method for Speeding Up Language Model Pre-training
Nan He, Weichen Xiong, Hanwen Liu, Yi Liao, Lei Ding, Kai Zhang, Guohua Tang, Xiao Han, Wei Yang
The effectiveness of large language models (LLMs) is often hindered by duplicated data in their extensive pre-training datasets. Current approaches primarily focus on detecting and removing duplicates, which risks the loss of valuable information and neglects the varying degrees of duplication. To address this, we propose a soft deduplication method that maintains dataset integrity while selectively reducing the sampling weight of data with high commonness. Central to our approach is the concept of data commonness, a metric we introduce to quantify the degree of duplication by measuring the occurrence probabilities of samples using an n-gram model. Empirical analysis shows that this method significantly improves training efficiency, achieving comparable perplexity scores with at least a 26% reduction in required training steps. Additionally, it enhances average few-shot downstream accuracy by 1.77% when trained for an equivalent duration. Importantly, this approach consistently improves performance, even on rigorously deduplicated datasets, indicating its potential to complement existing methods and become a standard pre-training process for LLMs.
Read more7/10/2024
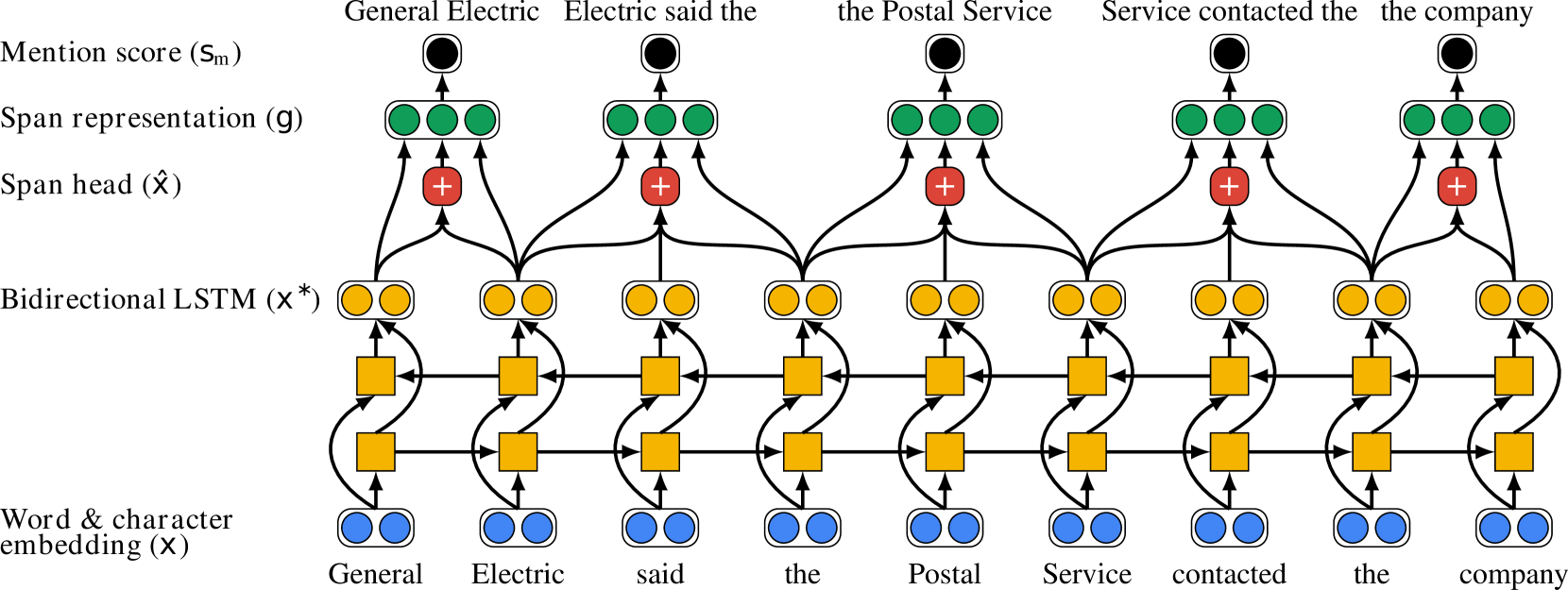
0
Exploring Multiple Strategies to Improve Multilingual Coreference Resolution in CorefUD
Ondv{r}ej Prav{z}'ak, Miloslav Konop'ik
Coreference resolution, the task of identifying expressions in text that refer to the same entity, is a critical component in various natural language processing (NLP) applications. This paper presents our end-to-end neural coreference resolution system, utilizing the CorefUD 1.1 dataset, which spans 17 datasets across 12 languages. We first establish strong baseline models, including monolingual and cross-lingual variations, and then propose several extensions to enhance performance across diverse linguistic contexts. These extensions include cross-lingual training, incorporation of syntactic information, a Span2Head model for optimized headword prediction, and advanced singleton modeling. We also experiment with headword span representation and long-documents modeling through overlapping segments. The proposed extensions, particularly the heads-only approach, singleton modeling, and long document prediction significantly improve performance across most datasets. We also perform zero-shot cross-lingual experiments, highlighting the potential and limitations of cross-lingual transfer in coreference resolution. Our findings contribute to the development of robust and scalable coreference systems for multilingual coreference resolution. Finally, we evaluate our model on CorefUD 1.1 test set and surpass the best model from CRAC 2023 shared task of a comparable size by a large margin. Our nodel is available on GitHub: url{https://github.com/ondfa/coref-multiling}
Read more9/2/2024

0
Transforming LLMs into Cross-modal and Cross-lingual RetrievalSystems
Frank Palma Gomez, Ramon Sanabria, Yun-hsuan Sung, Daniel Cer, Siddharth Dalmia, Gustavo Hernandez Abrego
Large language models (LLMs) are trained on text-only data that go far beyond the languages with paired speech and text data. At the same time, Dual Encoder (DE) based retrieval systems project queries and documents into the same embedding space and have demonstrated their success in retrieval and bi-text mining. To match speech and text in many languages, we propose using LLMs to initialize multi-modal DE retrieval systems. Unlike traditional methods, our system doesn't require speech data during LLM pre-training and can exploit LLM's multilingual text understanding capabilities to match speech and text in languages unseen during retrieval training. Our multi-modal LLM-based retrieval system is capable of matching speech and text in 102 languages despite only training on 21 languages. Our system outperforms previous systems trained explicitly on all 102 languages. We achieve a 10% absolute improvement in Recall@1 averaged across these languages. Additionally, our model demonstrates cross-lingual speech and text matching, which is further enhanced by readily available machine translation data.
Read more7/11/2024