Matryoshka-Adaptor: Unsupervised and Supervised Tuning for Smaller Embedding Dimensions

131

Sign in to get full access
Overview
- The paper introduces Matryoshka-Adaptor, a technique for unsupervised and supervised tuning of language models to smaller embedding dimensions.
- The key ideas are:
- Unsupervised tuning to learn a mapping from a large pre-trained model to a smaller compressed model.
- Supervised tuning to fine-tune the compressed model on downstream tasks.
- Experiments show the approach can maintain performance while significantly reducing model size.
Plain English Explanation
The paper presents a method called Matryoshka-Adaptor that can take a large, complex language model and compress it down to a smaller, more efficient version without losing too much performance.
The basic idea is to first learn an "unsupervised" mapping that translates the original large model's representations into a compressed format. This is like squeezing a big matryoshka doll into a smaller one without losing the core features.
Then, the compressed model is "supervised fine-tuned" on specific tasks, further optimizing it for those applications. This allows the compressed model to maintain high performance, even though it's much smaller than the original.
The key benefit is that you get a model that is significantly more compact and efficient, but still retains most of the capabilities of the larger, more complex original. This could be very useful for deploying language AI on devices with limited memory or compute resources.
Technical Explanation
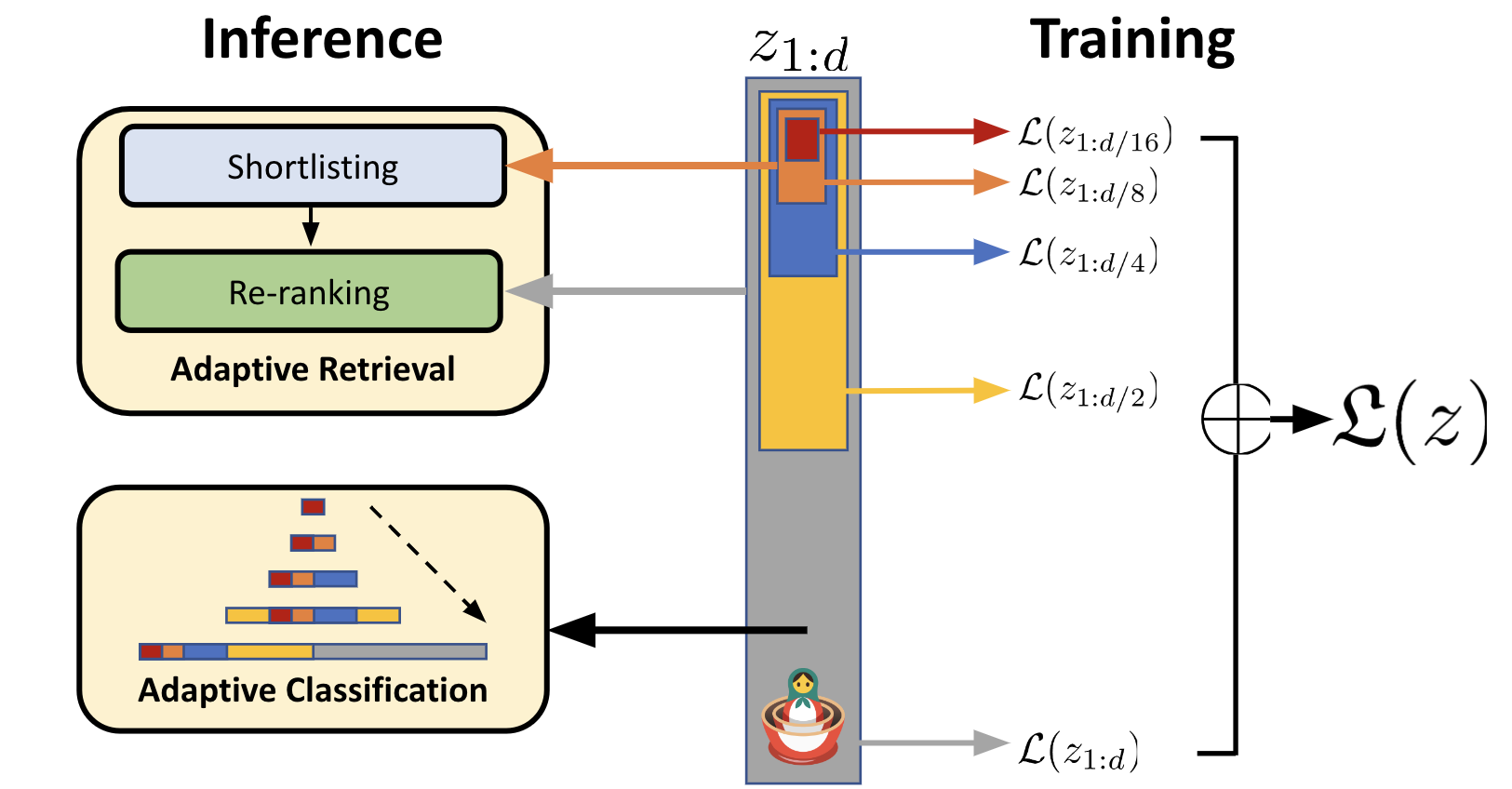
The core of the Matryoshka-Adaptor approach is an unsupervised tuning step that learns a mapping from a large pre-trained model to a smaller compressed model. This is done by optimizing an encoder-decoder architecture to reconstruct the original model's representations using a lower-dimensional latent space.
Once this unsupervised compression is complete, the compressed model is fine-tuned in a supervised manner on downstream tasks. This allows the smaller model to specialize and maintain high performance, even with the reduced dimensionality.
The experiments in the paper demonstrate that Matryoshka-Adaptor can achieve significant model size reductions (up to 8x) with only modest performance degradation across a range of NLP benchmarks. This suggests the technique is an effective way to compress large language models for more efficient deployment.
Critical Analysis
The paper provides a thorough evaluation of the Matryoshka-Adaptor approach, including comparisons to other model compression techniques. However, it does not delve into some potential limitations or caveats:
- The performance of the compressed models is still slightly lower than the original large models, even after fine-tuning. Further research may be needed to improve the compression-to-performance tradeoff.
- The technique was only evaluated on English language models. Its effectiveness on multilingual or non-English models is not yet clear.
- The computational and memory requirements of the unsupervised tuning process are not detailed. Scaling this to extremely large models could be challenging.
Overall, the Matryoshka-Adaptor method seems promising for efficiently deploying large language models, but additional research may be needed to fully understand its limitations and further optimize the compression-performance tradeoff.
Conclusion
The Matryoshka-Adaptor paper presents a novel approach for compressing large language models into smaller, more efficient versions without sacrificing too much performance. By combining unsupervised and supervised tuning, the technique can learn compact representations that retain the core capabilities of the original models.
This could have significant practical implications, enabling the deployment of powerful language AI on resource-constrained devices or in applications where model size is a critical constraint. As language models continue to grow in scale and complexity, techniques like Matryoshka-Adaptor will become increasingly important for making this technology more widely accessible and usable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
131
Matryoshka-Adaptor: Unsupervised and Supervised Tuning for Smaller Embedding Dimensions
Jinsung Yoon, Raj Sinha, Sercan O Arik, Tomas Pfister
Embeddings from Large Language Models (LLMs) have emerged as critical components in various applications, particularly for information retrieval. While high-dimensional embeddings generally demonstrate superior performance as they contain more salient information, their practical application is frequently hindered by elevated computational latency and the associated higher cost. To address these challenges, we propose Matryoshka-Adaptor, a novel tuning framework designed for the customization of LLM embeddings. Matryoshka-Adaptor facilitates substantial dimensionality reduction while maintaining comparable performance levels, thereby achieving a significant enhancement in computational efficiency and cost-effectiveness. Our framework directly modifies the embeddings from pre-trained LLMs which is designed to be seamlessly integrated with any LLM architecture, encompassing those accessible exclusively through black-box APIs. Also, it exhibits efficacy in both unsupervised and supervised learning settings. A rigorous evaluation conducted across a diverse corpus of English, multilingual, and multimodal datasets consistently reveals substantial gains with Matryoshka-Adaptor. Notably, with Google and OpenAI Embedding APIs, Matryoshka-Adaptor achieves a reduction in dimensionality ranging from two- to twelve-fold without compromising performance across multiple BEIR datasets.
Read more7/31/2024
0
Enhancing Semantic Similarity Understanding in Arabic NLP with Nested Embedding Learning
Omer Nacar, Anis Koubaa
This work presents a novel framework for training Arabic nested embedding models through Matryoshka Embedding Learning, leveraging multilingual, Arabic-specific, and English-based models, to highlight the power of nested embeddings models in various Arabic NLP downstream tasks. Our innovative contribution includes the translation of various sentence similarity datasets into Arabic, enabling a comprehensive evaluation framework to compare these models across different dimensions. We trained several nested embedding models on the Arabic Natural Language Inference triplet dataset and assessed their performance using multiple evaluation metrics, including Pearson and Spearman correlations for cosine similarity, Manhattan distance, Euclidean distance, and dot product similarity. The results demonstrate the superior performance of the Matryoshka embedding models, particularly in capturing semantic nuances unique to the Arabic language. Results demonstrated that Arabic Matryoshka embedding models have superior performance in capturing semantic nuances unique to the Arabic language, significantly outperforming traditional models by up to 20-25% across various similarity metrics. These results underscore the effectiveness of language-specific training and highlight the potential of Matryoshka models in enhancing semantic textual similarity tasks for Arabic NLP.
Read more8/2/2024

0
Search-Adaptor: Embedding Customization for Information Retrieval
Jinsung Yoon, Sercan O Arik, Yanfei Chen, Tomas Pfister
Embeddings extracted by pre-trained Large Language Models (LLMs) have significant potential to improve information retrieval and search. Beyond the zero-shot setup in which they are being conventionally used, being able to take advantage of the information from the relevant query-corpus paired data can further boost the LLM capabilities. In this paper, we propose a novel method, Search-Adaptor, for customizing LLMs for information retrieval in an efficient and robust way. Search-Adaptor modifies the embeddings generated by pre-trained LLMs, and can be integrated with any LLM, including those only available via prediction APIs. On multiple English, multilingual, and multimodal retrieval datasets, we show consistent and significant performance benefits for Search-Adaptor -- e.g., more than 5% improvements for Google Embedding APIs in nDCG@10 averaged over 14 BEIR datasets.
Read more8/26/2024

0
Matryoshka Multimodal Models
Mu Cai, Jianwei Yang, Jianfeng Gao, Yong Jae Lee
Large Multimodal Models (LMMs) such as LLaVA have shown strong performance in visual-linguistic reasoning. These models first embed images into a fixed large number of visual tokens and then feed them into a Large Language Model (LLM). However, this design causes an excessive number of tokens for dense visual scenarios such as high-resolution images and videos, leading to great inefficiency. While token pruning/merging methods do exist, they produce a single length output for each image and do not afford flexibility in trading off information density v.s. efficiency. Inspired by the concept of Matryoshka Dolls, we propose M3: Matryoshka Multimodal Models, which learns to represent visual content as nested sets of visual tokens that capture information across multiple coarse-to-fine granularities. Our approach offers several unique benefits for LMMs: (1) One can explicitly control the visual granularity per test instance during inference, e.g. , adjusting the number of tokens used to represent an image based on the anticipated complexity or simplicity of the content; (2) M3 provides a framework for analyzing the granularity needed for existing datasets, where we find that COCO-style benchmarks only need around ~9 visual tokens to obtain accuracy similar to that of using all 576 tokens; (3) Our approach provides a foundation to explore the best trade-off between performance and visual token length at sample level, where our investigation reveals that a large gap exists between the oracle upper bound and current fixed-scale representations.
Read more7/30/2024