Matryoshka Multimodal Models
2405.17430
0
0

Abstract
Large Multimodal Models (LMMs) such as LLaVA have shown strong performance in visual-linguistic reasoning. These models first embed images into a fixed large number of visual tokens and then feed them into a Large Language Model (LLM). However, this design causes an excessive number of tokens for dense visual scenarios such as high-resolution images and videos, leading to great inefficiency. While token pruning/merging methods do exist, they produce a single length output for each image and do not afford flexibility in trading off information density v.s. efficiency. Inspired by the concept of Matryoshka Dolls, we propose M3: Matryoshka Multimodal Models, which learns to represent visual content as nested sets of visual tokens that capture information across multiple coarse-to-fine granularities. Our approach offers several unique benefits for LMMs: (1) One can explicitly control the visual granularity per test instance during inference, e.g. , adjusting the number of tokens used to represent an image based on the anticipated complexity or simplicity of the content; (2) M3 provides a framework for analyzing the granularity needed for existing datasets, where we find that COCO-style benchmarks only need around ~9 visual tokens to obtain accuracy similar to that of using all 576 tokens; (3) Our approach provides a foundation to explore the best trade-off between performance and visual token length at sample level, where our investigation reveals that a large gap exists between the oracle upper bound and current fixed-scale representations.
Create account to get full access
Overview
- This paper introduces Matryoshka Multimodal Models (M³), a novel approach to leveraging multimodal information in large language models (LLMs).
- M³ aims to improve the performance and efficiency of LLMs by integrating visual and textual modalities in a hierarchical, "matryoshka" structure.
- The key ideas include linking to "Auto-Encoding Morph Tokens for Multimodal LLMs" and enabling 3D understanding in language-image models.
Plain English Explanation
Matryoshka Multimodal Models (M³) is a new way of building large language models that can leverage both text and visual information. The core idea is to create a hierarchical, or "nested doll" (matryoshka) structure, where the model has different levels that can process and combine textual and visual data.
At the lowest level, the model can understand individual words and images. As you move up the hierarchy, the model can start to understand how words and images relate to each other and form more complex meanings. This allows the model to build a richer, more nuanced understanding of the world compared to traditional language models that only use text.
By integrating visual and textual modalities in this way, M³ aims to improve the performance and efficiency of large language models on a variety of tasks, from explaining multi-modal LLMs to enabling 3D understanding in language-image models. The hierarchical structure also allows the model to adaptively reduce tokens for more efficient processing.
Technical Explanation
The key innovation of M³ is its hierarchical, "matryoshka" structure that integrates visual and textual modalities. At the lowest level, the model has separate encoding modules for processing text and images. These encoders produce representations that are then combined and passed up to higher-level modules that can learn cross-modal relationships.
This multi-scale architecture allows the model to build a rich, multi-faceted understanding of the input data. For example, the lower-level modules can capture basic visual and linguistic features, while the higher-level modules can learn how these features interact to form complex meanings.
The authors demonstrate the effectiveness of M³ on a range of multi-modal language tasks, including image captioning, visual question answering, and multi-modal commonsense reasoning. They show that M³ outperforms strong baselines that use a more simplistic fusion of text and images.
Critical Analysis
One key strength of the M³ approach is its flexibility and scalability. By introducing a hierarchical structure, the model can adapt its processing to the complexity of the input, allocating more or less capacity to visual and textual information as needed. This could make M³ particularly well-suited for real-world applications where the input data varies widely in its modality and complexity.
However, the authors do acknowledge some limitations of their work. For example, the current M³ architecture may struggle with tasks that require tight, real-time integration of visual and linguistic processing, such as multi-modal dialog. Additionally, the training and inference costs of the hierarchical model could be higher than simpler fusion approaches, which may limit its applicability in certain resource-constrained settings.
Overall, the M³ framework represents an intriguing step forward in the quest to build more powerful and versatile multimodal language models. By taking inspiration from cognitive science and leveraging the benefits of hierarchical processing, the authors have demonstrated a novel approach that could have significant implications for a wide range of AI applications.
Conclusion
Matryoshka Multimodal Models (M³) offer a promising new direction for developing large language models that can seamlessly integrate visual and textual information. By adopting a hierarchical, "nested doll" structure, M³ can build rich, multi-faceted representations that capture the complex relationships between language and imagery.
The potential benefits of this approach are far-reaching, from improving the interpretability of multi-modal LLMs to enabling more sophisticated 3D understanding in language-image models. While the current M³ framework has some limitations, the authors have laid the groundwork for a new generation of multimodal models that could transform a wide range of AI applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
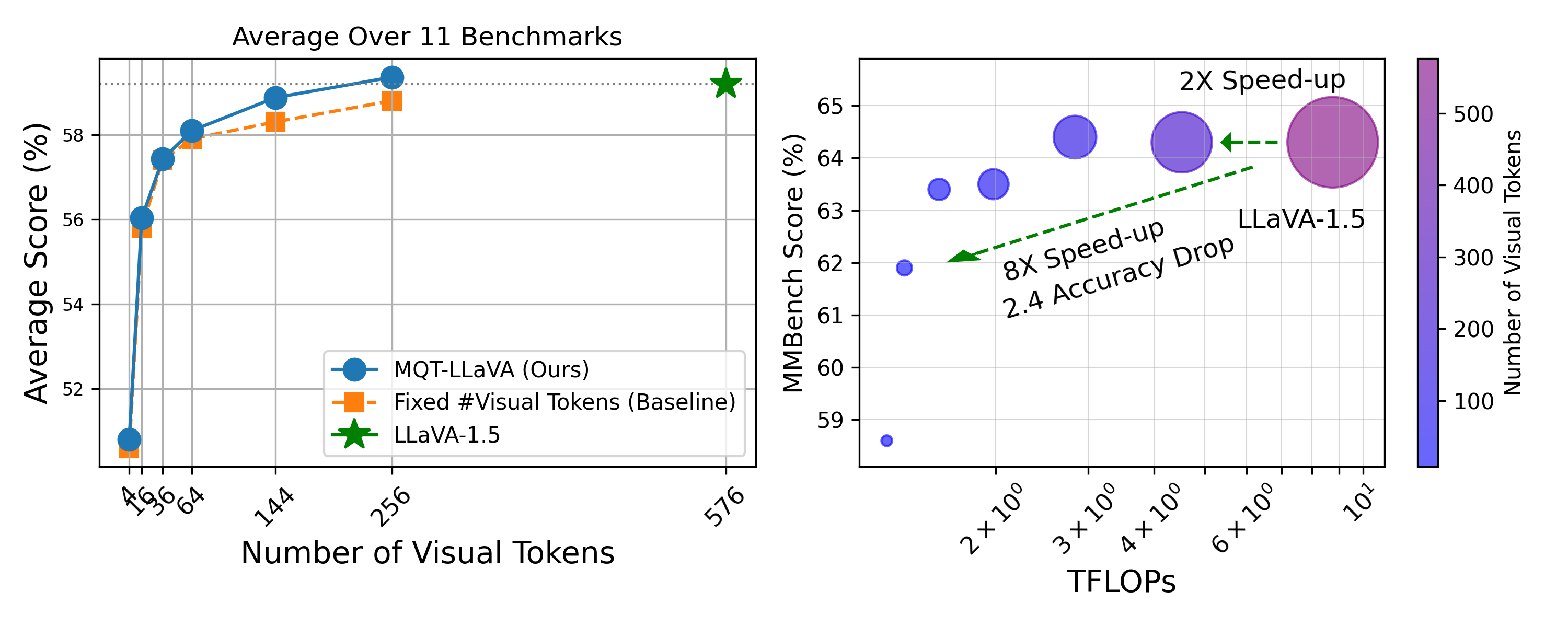
Matryoshka Query Transformer for Large Vision-Language Models
Wenbo Hu, Zi-Yi Dou, Liunian Harold Li, Amita Kamath, Nanyun Peng, Kai-Wei Chang
0
0
Large Vision-Language Models (LVLMs) typically encode an image into a fixed number of visual tokens (e.g., 576) and process these tokens with a language model. Despite their strong performance, LVLMs face challenges in adapting to varying computational constraints. This raises the question: can we achieve flexibility in the number of visual tokens to suit different tasks and computational resources? We answer this with an emphatic yes. Inspired by Matryoshka Representation Learning, we introduce the Matryoshka Query Transformer (MQT), capable of encoding an image into m visual tokens during inference, where m can be any number up to a predefined maximum. This is achieved by employing a query transformer with M latent query tokens to compress the visual embeddings. During each training step, we randomly select m <= M latent query tokens and train the model using only these first m tokens, discarding the rest. Combining MQT with LLaVA, we train a single model once, and flexibly and drastically reduce the number of inference-time visual tokens while maintaining similar or better performance compared to training independent models for each number of tokens. Our model, MQT-LLAVA, matches LLaVA-1.5 performance across 11 benchmarks using a maximum of 256 tokens instead of LLaVA's fixed 576. Reducing to 16 tokens (8x less TFLOPs) only sacrifices the performance by 2.4 points on MMBench. On certain tasks such as ScienceQA and MMMU, we can even go down to only 2 visual tokens with performance drops of just 3% and 6% each. Our exploration of the trade-off between the accuracy and computational cost brought about by the number of visual tokens facilitates future research to achieve the best of both worlds.
6/10/2024
💬
MammothModa: Multi-Modal Large Language Model
Qi She, Junwen Pan, Xin Wan, Rui Zhang, Dawei Lu, Kai Huang
0
0
In this report, we introduce MammothModa, yet another multi-modal large language model (MLLM) designed to achieve state-of-the-art performance starting from an elementary baseline. We focus on three key design insights: (i) Integrating Visual Capabilities while Maintaining Complex Language Understanding: In addition to the vision encoder, we incorporated the Visual Attention Experts into the LLM to enhance its visual capabilities. (ii) Extending Context Window for High-Resolution and Long-Duration Visual Feature: We explore the Visual Merger Module to effectively reduce the token number of high-resolution images and incorporated frame position ids to avoid position interpolation. (iii) High-Quality Bilingual Datasets: We meticulously curated and filtered a high-quality bilingual multimodal dataset to reduce visual hallucinations. With above recipe we build MammothModa that consistently outperforms the state-of-the-art models, e.g., LLaVA-series, across main real-world visual language benchmarks without bells and whistles.
6/27/2024

LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, Yan Yan
0
0
Large Multimodal Models (LMMs) have shown significant visual reasoning capabilities by connecting a visual encoder and a large language model. LMMs typically take in a fixed and large amount of visual tokens, such as the penultimate layer features in the CLIP visual encoder, as the prefix content. Recent LMMs incorporate more complex visual inputs, such as high-resolution images and videos, which further increases the number of visual tokens significantly. However, due to the inherent design of the Transformer architecture, the computational costs of these models tend to increase quadratically with the number of input tokens. To tackle this problem, we explore a token reduction mechanism that identifies significant spatial redundancy among visual tokens. In response, we propose PruMerge, a novel adaptive visual token reduction strategy that significantly reduces the number of visual tokens without compromising the performance of LMMs. Specifically, to metric the importance of each token, we exploit the sparsity observed in the visual encoder, characterized by the sparse distribution of attention scores between the class token and visual tokens. This sparsity enables us to dynamically select the most crucial visual tokens to retain. Subsequently, we cluster the selected (unpruned) tokens based on their key similarity and merge them with the unpruned tokens, effectively supplementing and enhancing their informational content. Empirically, when applied to LLaVA-1.5, our approach can compress the visual tokens by 14 times on average, and achieve comparable performance across diverse visual question-answering and reasoning tasks. Code and checkpoints are at https://llava-prumerge.github.io/.
5/24/2024

The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
0
0
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
6/7/2024