Enhancing Sound Source Localization via False Negative Elimination

0
💬
Sign in to get full access
Overview
- Sound source localization aims to locate objects emitting sound in visual scenes.
- Recent methods using contrastive learning have achieved impressive results, but the common practice of randomly sampling negatives can lead to the "false negative issue".
- This issue occurs when sounds semantically similar to the visual instance are sampled as negatives and incorrectly pushed away from the visual anchor/query.
- This audio-visual feature misalignment can degrade performance.
Plain English Explanation
The paper proposes a novel audio-visual learning framework to address the "false negative issue" in sound source localization. Sound source localization aims to identify the location of objects that are making sounds within visual scenes.
Recent approaches using contrastive learning have produced impressive results, but they often randomly sample "negative" examples (sounds that don't match the visual scene) during training. This can lead to the "false negative issue", where sounds that are actually semantically similar to the visual scene are mistakenly treated as negatives and pushed away from the visual anchor/query.
This misalignment between the audio and visual features can ultimately hurt the model's performance. To address this, the paper proposes two learning schemes:
-
Self-Supervised Predictive Learning (SSPL): This method only uses positive audio-visual pairs, eliminating the need for negative sampling and avoiding the "false negative issue". It discovers semantic similarities between audio and visual features through predictive coding.
-
Semantic-Aware Contrastive Learning (SACL): This method harnesses the power of contrastive learning, but uses a more reliable visual anchor and selects better audio negatives to improve feature alignment.
By combining these two approaches, the framework can effectively learn robust audio-visual representations for sound source localization, while also being extensible to other tasks like audio-visual event classification and object detection.
Technical Explanation
The paper proposes a novel audio-visual learning framework to address the "false negative issue" in sound source localization.
The framework consists of two key components:
-
Self-Supervised Predictive Learning (SSPL): This module explores only positive audio-visual pairs to discover semantically coherent similarities between audio and visual features. A predictive coding module is introduced to facilitate this positive-only learning, effectively eliminating the need for negative sampling and avoiding the "false negative issue".
-
Semantic-Aware Contrastive Learning (SACL): This module is designed to compact visual features and remove false negatives, providing a reliable visual anchor and audio negatives for contrastive learning. Unlike SSPL, SACL harnesses the power of audio-visual contrastive learning to achieve the same goal.
The paper demonstrates the superiority of this framework over state-of-the-art approaches through comprehensive experiments. Furthermore, the versatility of the learned representations is highlighted by extending the framework to audio-visual event classification and object detection tasks.
Critical Analysis
The paper addresses a valid issue in audio-visual contrastive learning for sound source localization - the "false negative issue" caused by randomly sampling negatives. The proposed solutions, SSPL and SACL, offer compelling alternatives to mitigate this problem.
However, the paper could have provided more detailed analysis on the limitations and potential drawbacks of the framework. For example, it's unclear how the framework would scale to larger and more diverse audio-visual datasets, or how it might perform in real-world scenarios with noisy or ambiguous audio-visual inputs.
Additionally, the paper could have explored the tradeoffs between SSPL and SACL in terms of computational complexity, training stability, and overall performance. A more in-depth comparison and analysis of these two components would help readers better understand the nuances and suitability of the proposed framework.
Nevertheless, the paper makes a valuable contribution by addressing a critical issue in audio-visual contrastive learning and proposing solutions that demonstrate promising results. Further research and refinement of the framework could lead to even more robust and versatile audio-visual representation learning models.
Conclusion
This paper presents a novel audio-visual learning framework that addresses the "false negative issue" in sound source localization. By proposing two complementary learning schemes, SSPL and SACL, the framework effectively learns robust audio-visual representations while avoiding the pitfalls of random negative sampling.
The framework's versatility is highlighted by its extension to other audio-visual tasks, such as event classification and object detection. This suggests the potential for the learned representations to be useful in a wide range of applications beyond just sound source localization.
Overall, the paper's approach represents an important step forward in audio-visual representation learning, with the potential to improve the performance and robustness of various multimodal perception tasks. As the field continues to evolve, further research and refinement of this framework could lead to even more powerful and practical solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Enhancing Sound Source Localization via False Negative Elimination
Zengjie Song, Jiangshe Zhang, Yuxi Wang, Junsong Fan, Zhaoxiang Zhang
Sound source localization aims to localize objects emitting the sound in visual scenes. Recent works obtaining impressive results typically rely on contrastive learning. However, the common practice of randomly sampling negatives in prior arts can lead to the false negative issue, where the sounds semantically similar to visual instance are sampled as negatives and incorrectly pushed away from the visual anchor/query. As a result, this misalignment of audio and visual features could yield inferior performance. To address this issue, we propose a novel audio-visual learning framework which is instantiated with two individual learning schemes: self-supervised predictive learning (SSPL) and semantic-aware contrastive learning (SACL). SSPL explores image-audio positive pairs alone to discover semantically coherent similarities between audio and visual features, while a predictive coding module for feature alignment is introduced to facilitate the positive-only learning. In this regard SSPL acts as a negative-free method to eliminate false negatives. By contrast, SACL is designed to compact visual features and remove false negatives, providing reliable visual anchor and audio negatives for contrast. Different from SSPL, SACL releases the potential of audio-visual contrastive learning, offering an effective alternative to achieve the same goal. Comprehensive experiments demonstrate the superiority of our approach over the state-of-the-arts. Furthermore, we highlight the versatility of the learned representation by extending the approach to audio-visual event classification and object detection tasks. Code and models are available at: https://github.com/zjsong/SACL.
Read more8/30/2024
0
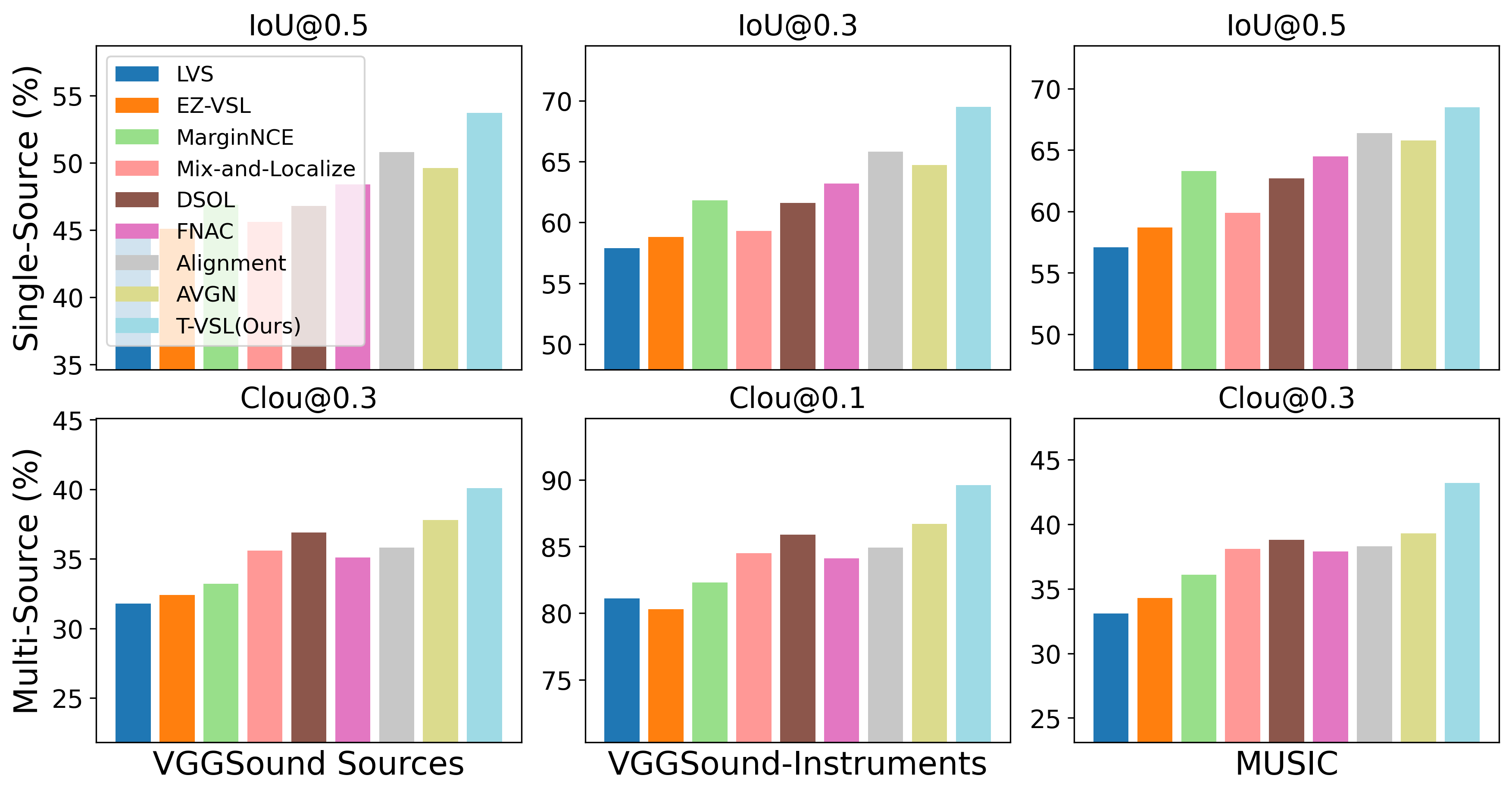
T-VSL: Text-Guided Visual Sound Source Localization in Mixtures
Tanvir Mahmud, Yapeng Tian, Diana Marculescu
Visual sound source localization poses a significant challenge in identifying the semantic region of each sounding source within a video. Existing self-supervised and weakly supervised source localization methods struggle to accurately distinguish the semantic regions of each sounding object, particularly in multi-source mixtures. These methods often rely on audio-visual correspondence as guidance, which can lead to substantial performance drops in complex multi-source localization scenarios. The lack of access to individual source sounds in multi-source mixtures during training exacerbates the difficulty of learning effective audio-visual correspondence for localization. To address this limitation, in this paper, we propose incorporating the text modality as an intermediate feature guide using tri-modal joint embedding models (e.g., AudioCLIP) to disentangle the semantic audio-visual source correspondence in multi-source mixtures. Our framework, dubbed T-VSL, begins by predicting the class of sounding entities in mixtures. Subsequently, the textual representation of each sounding source is employed as guidance to disentangle fine-grained audio-visual source correspondence from multi-source mixtures, leveraging the tri-modal AudioCLIP embedding. This approach enables our framework to handle a flexible number of sources and exhibits promising zero-shot transferability to unseen classes during test time. Extensive experiments conducted on the MUSIC, VGGSound, and VGGSound-Instruments datasets demonstrate significant performance improvements over state-of-the-art methods. Code is released at https://github.com/enyac-group/T-VSL/tree/main
Read more7/9/2024
🛠️
0
SemiPL: A Semi-supervised Method for Event Sound Source Localization
Yue Li, Baiqiao Yin, Jinfu Liu, Jiajun Wen, Jiaying Lin, Mengyuan Liu
In recent years, Event Sound Source Localization has been widely applied in various fields. Recent works typically relying on the contrastive learning framework show impressive performance. However, all work is based on large relatively simple datasets. It's also crucial to understand and analyze human behaviors (actions and interactions of people), voices, and sounds in chaotic events in many applications, e.g., crowd management, and emergency response services. In this paper, we apply the existing model to a more complex dataset, explore the influence of parameters on the model, and propose a semi-supervised improvement method SemiPL. With the increase in data quantity and the influence of label quality, self-supervised learning will be an unstoppable trend. The experiment shows that the parameter adjustment will positively affect the existing model. In particular, SSPL achieved an improvement of 12.2% cIoU and 0.56% AUC in Chaotic World compared to the results provided. The code is available at: https://github.com/ly245422/SSPL
Read more5/1/2024

0
Aligning Sight and Sound: Advanced Sound Source Localization Through Audio-Visual Alignment
Arda Senocak, Hyeonggon Ryu, Junsik Kim, Tae-Hyun Oh, Hanspeter Pfister, Joon Son Chung
Recent studies on learning-based sound source localization have mainly focused on the localization performance perspective. However, prior work and existing benchmarks overlook a crucial aspect: cross-modal interaction, which is essential for interactive sound source localization. Cross-modal interaction is vital for understanding semantically matched or mismatched audio-visual events, such as silent objects or off-screen sounds. In this paper, we first comprehensively examine the cross-modal interaction of existing methods, benchmarks, evaluation metrics, and cross-modal understanding tasks. Then, we identify the limitations of previous studies and make several contributions to overcome the limitations. First, we introduce a new synthetic benchmark for interactive sound source localization. Second, we introduce new evaluation metrics to rigorously assess sound source localization methods, focusing on accurately evaluating both localization performance and cross-modal interaction ability. Third, we propose a learning framework with a cross-modal alignment strategy to enhance cross-modal interaction. Lastly, we evaluate both interactive sound source localization and auxiliary cross-modal retrieval tasks together to thoroughly assess cross-modal interaction capabilities and benchmark competing methods. Our new benchmarks and evaluation metrics reveal previously overlooked issues in sound source localization studies. Our proposed novel method, with enhanced cross-modal alignment, shows superior sound source localization performance. This work provides the most comprehensive analysis of sound source localization to date, with extensive validation of competing methods on both existing and new benchmarks using new and standard evaluation metrics.
Read more7/19/2024