Aligning Sight and Sound: Advanced Sound Source Localization Through Audio-Visual Alignment

0

Sign in to get full access
Overview
- The paper explores advanced sound source localization through audio-visual alignment, leveraging multi-modal learning and cross-modal retrieval.
- It investigates how aligning visual and audio data can improve the accuracy of sound source localization, a key capability for applications like robotics and augmented reality.
- The research builds on previous work in audio-visual talker localization, text-guided visual sound source localization, and audio-visual information fusion for sound event localization.
Plain English Explanation
The paper explores a way to improve the ability of AI systems to figure out where sounds are coming from, using both audio and visual information. This is an important capability for things like robotics and augmented reality, where the system needs to know where sounds are originating from in the environment.
The key idea is that by aligning or matching up the audio and visual data, the system can learn to more accurately locate sound sources. For example, if the system sees a person talking and hears the corresponding speech, it can learn to associate the visual location of the person's mouth with the source of the sound. This allows the system to better pinpoint the location of sounds in the future, even if it's just hearing the audio without any visual information.
The researchers build on previous work that has looked at using multi-modal (audio and visual) data for tasks like localizing talkers in a video or guiding visual sound source localization using text descriptions. This new research aims to push the state-of-the-art in this area and develop more advanced sound localization capabilities.
Technical Explanation
The paper presents a novel approach for sound source localization that leverages the alignment between audio and visual data through multi-modal learning and cross-modal retrieval. The proposed method learns to associate visual information, such as the location of objects or people in a scene, with the corresponding audio signals, allowing it to more accurately pinpoint the origin of sounds.
The core technical components include:
- Audio-Visual Encoder: A neural network architecture that takes in both audio and visual inputs and learns a joint embedding space, enabling cross-modal retrieval and alignment.
- Self-Supervised Pre-Training: The model is first pre-trained on large-scale unlabeled audio-visual data to learn the fundamental associations between sight and sound, without requiring any manual annotations.
- Sound Source Localization: During the downstream task of sound source localization, the pre-trained model is fine-tuned on annotated data to predict the spatial coordinates of sound sources based on the audio input.
The researchers evaluate their approach on several benchmark datasets, including audio simulation for sound source localization in virtual environments, and demonstrate significant improvements over previous state-of-the-art methods. The key insights highlight the power of leveraging cross-modal information and the benefits of self-supervised pre-training for enhancing sound localization capabilities.
Critical Analysis
The paper presents a compelling approach for advancing sound source localization through audio-visual alignment, but there are a few potential limitations and areas for further research:
-
Dataset Bias: The performance of the model may be sensitive to the characteristics of the training data, such as the types of sound sources, environments, and audio-visual correlations. Evaluating the system's robustness to more diverse and challenging datasets would be valuable.
-
Real-World Deployment: While the results on benchmark datasets are promising, the practicality of deploying such a system in real-world applications, such as robotics or augmented reality, remains to be explored. Factors like processing speed, power consumption, and integration with other sensors would need to be considered.
-
Interpretability and Explainability: As with many deep learning models, the internal workings of the audio-visual encoder may be opaque. Developing techniques to better understand how the model is making its predictions could lead to important insights and help build trust in the system's decision-making.
-
Multimodal Fusion Strategies: The paper focuses on aligning audio and visual data, but there may be opportunities to explore more sophisticated multimodal fusion strategies that can better leverage the complementary information from different modalities.
Overall, the research presented in this paper represents an important step forward in sound source localization and highlights the potential of cross-modal learning for enhancing multimodal perception capabilities. Addressing the identified limitations and continuing to push the boundaries of this field could lead to significant advancements in various real-world applications.
Conclusion
This paper introduces a novel approach for improving sound source localization by leveraging the alignment between audio and visual data through multi-modal learning and cross-modal retrieval. The proposed method demonstrates significant performance gains over previous state-of-the-art techniques, highlighting the power of combining sight and sound to enhance spatial audio perception.
The research builds on and advances previous work in related areas like audio-visual talker localization, text-guided visual sound source localization, and audio-visual information fusion for sound event localization. By demonstrating the benefits of aligning sight and sound, this research paves the way for more advanced multimodal perception capabilities that could significantly impact applications in robotics, augmented reality, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Aligning Sight and Sound: Advanced Sound Source Localization Through Audio-Visual Alignment
Arda Senocak, Hyeonggon Ryu, Junsik Kim, Tae-Hyun Oh, Hanspeter Pfister, Joon Son Chung
Recent studies on learning-based sound source localization have mainly focused on the localization performance perspective. However, prior work and existing benchmarks overlook a crucial aspect: cross-modal interaction, which is essential for interactive sound source localization. Cross-modal interaction is vital for understanding semantically matched or mismatched audio-visual events, such as silent objects or off-screen sounds. In this paper, we first comprehensively examine the cross-modal interaction of existing methods, benchmarks, evaluation metrics, and cross-modal understanding tasks. Then, we identify the limitations of previous studies and make several contributions to overcome the limitations. First, we introduce a new synthetic benchmark for interactive sound source localization. Second, we introduce new evaluation metrics to rigorously assess sound source localization methods, focusing on accurately evaluating both localization performance and cross-modal interaction ability. Third, we propose a learning framework with a cross-modal alignment strategy to enhance cross-modal interaction. Lastly, we evaluate both interactive sound source localization and auxiliary cross-modal retrieval tasks together to thoroughly assess cross-modal interaction capabilities and benchmark competing methods. Our new benchmarks and evaluation metrics reveal previously overlooked issues in sound source localization studies. Our proposed novel method, with enhanced cross-modal alignment, shows superior sound source localization performance. This work provides the most comprehensive analysis of sound source localization to date, with extensive validation of competing methods on both existing and new benchmarks using new and standard evaluation metrics.
Read more7/19/2024
0
T-VSL: Text-Guided Visual Sound Source Localization in Mixtures
Tanvir Mahmud, Yapeng Tian, Diana Marculescu
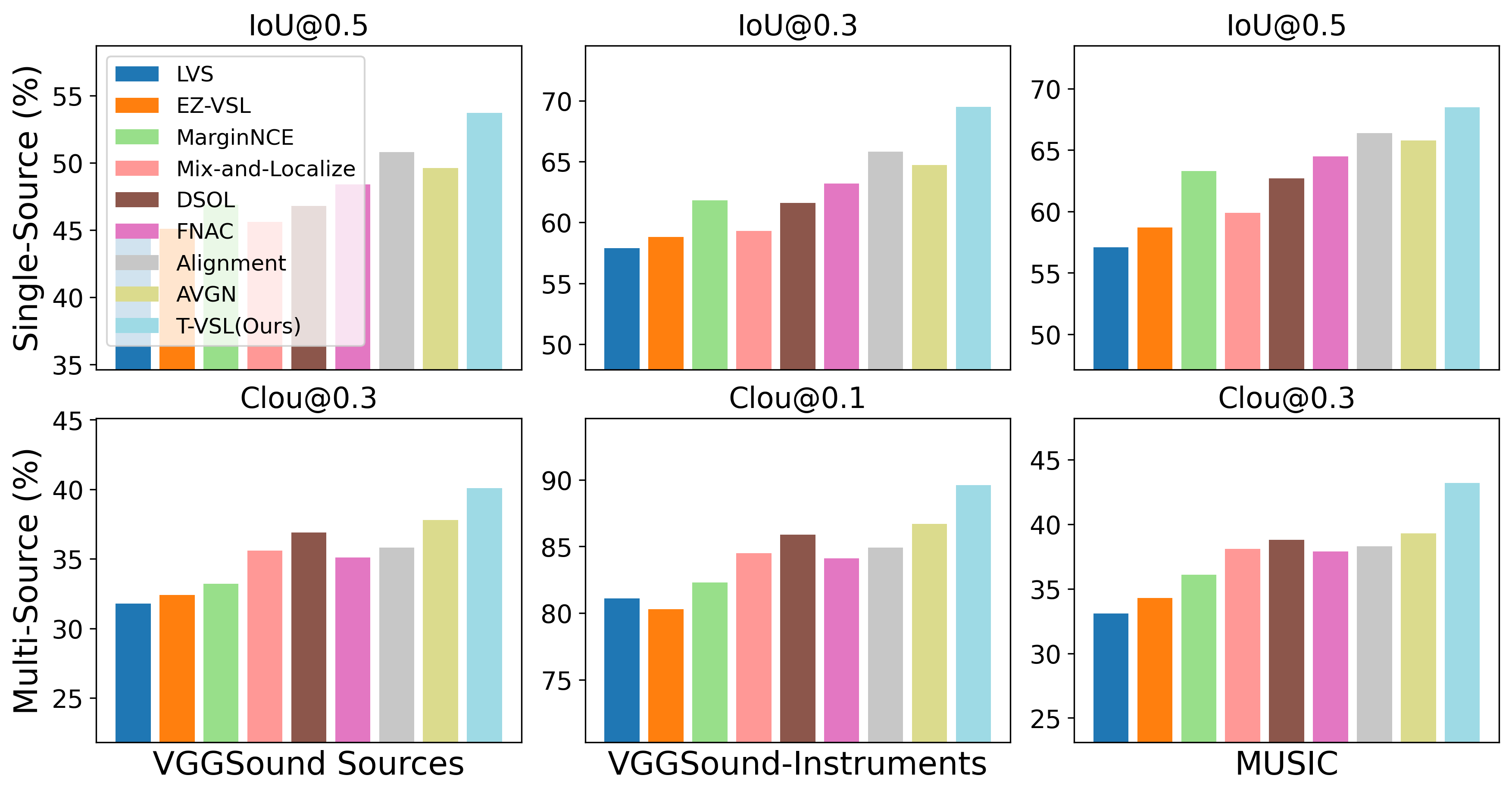
Visual sound source localization poses a significant challenge in identifying the semantic region of each sounding source within a video. Existing self-supervised and weakly supervised source localization methods struggle to accurately distinguish the semantic regions of each sounding object, particularly in multi-source mixtures. These methods often rely on audio-visual correspondence as guidance, which can lead to substantial performance drops in complex multi-source localization scenarios. The lack of access to individual source sounds in multi-source mixtures during training exacerbates the difficulty of learning effective audio-visual correspondence for localization. To address this limitation, in this paper, we propose incorporating the text modality as an intermediate feature guide using tri-modal joint embedding models (e.g., AudioCLIP) to disentangle the semantic audio-visual source correspondence in multi-source mixtures. Our framework, dubbed T-VSL, begins by predicting the class of sounding entities in mixtures. Subsequently, the textual representation of each sounding source is employed as guidance to disentangle fine-grained audio-visual source correspondence from multi-source mixtures, leveraging the tri-modal AudioCLIP embedding. This approach enables our framework to handle a flexible number of sources and exhibits promising zero-shot transferability to unseen classes during test time. Extensive experiments conducted on the MUSIC, VGGSound, and VGGSound-Instruments datasets demonstrate significant performance improvements over state-of-the-art methods. Code is released at https://github.com/enyac-group/T-VSL/tree/main
Read more7/9/2024
↗️
0
Audio Simulation for Sound Source Localization in Virtual Evironment
Yi Di Yuan, Swee Liang Wong, Jonathan Pan
Non-line-of-sight localization in signal-deprived environments is a challenging yet pertinent problem. Acoustic methods in such predominantly indoor scenarios encounter difficulty due to the reverberant nature. In this study, we aim to locate sound sources to specific locations within a virtual environment by leveraging physically grounded sound propagation simulations and machine learning methods. This process attempts to overcome the issue of data insufficiency to localize sound sources to their location of occurrence especially in post-event localization. We achieve 0.786+/- 0.0136 F1-score using an audio transformer spectrogram approach.
Read more4/3/2024

0
Unveiling Visual Biases in Audio-Visual Localization Benchmarks
Liangyu Chen, Zihao Yue, Boshen Xu, Qin Jin
Audio-Visual Source Localization (AVSL) aims to localize the source of sound within a video. In this paper, we identify a significant issue in existing benchmarks: the sounding objects are often easily recognized based solely on visual cues, which we refer to as visual bias. Such biases hinder these benchmarks from effectively evaluating AVSL models. To further validate our hypothesis regarding visual biases, we examine two representative AVSL benchmarks, VGG-SS and EpicSounding-Object, where the vision-only models outperform all audiovisual baselines. Our findings suggest that existing AVSL benchmarks need further refinement to facilitate audio-visual learning.
Read more9/12/2024