Enhancing the Utility of Privacy-Preserving Cancer Classification using Synthetic Data

0

Sign in to get full access
Overview
- This paper explores the use of synthetic data to enhance the utility of privacy-preserving cancer classification models.
- The researchers investigate how generating synthetic breast cancer images can improve the performance of differential privacy-based image classification models.
- They compare the utility of models trained on real patient data versus models trained on synthetic data generated using various techniques.
Plain English Explanation
Cancer diagnosis and treatment often rely on medical imaging, such as mammograms. However, using real patient data for developing and testing these algorithms raises significant privacy concerns. This paper explores the use of synthetic data to address this challenge.
The researchers generated artificial breast cancer images using different machine learning techniques, including differential privacy and generative adversarial networks. They then trained cancer classification models using these synthetic images and compared their performance to models trained on real patient data.
The key idea is that by using synthetic data, you can develop useful algorithms without compromising patient privacy. The results suggest that in some cases, the synthetic data-based models can actually outperform the models trained on real data, potentially making privacy-preserving cancer diagnosis more feasible.
Technical Explanation
The researchers explored different techniques for generating synthetic breast cancer images that could be used to train privacy-preserving cancer classification models. They used two main approaches:
-
Differentially Private Synthetic Image Generation: The team developed a method to generate synthetic images that satisfy the differential privacy guarantee, ensuring that the presence or absence of any individual in the dataset has a bounded effect on the output.
-
Generative Adversarial Networks (GANs) for Synthetic Image Generation: The researchers also explored using GAN-based models to generate realistic synthetic breast cancer images. GANs pit a generator network against a discriminator network, allowing them to produce high-quality synthetic data.
The team then trained cancer classification models using the synthetic images and compared their performance to models trained on real patient data. They found that in some cases, the synthetic data-based models outperformed the real data-based models, suggesting that synthetic data can enhance the utility of privacy-preserving cancer classification.
Critical Analysis
The paper presents a promising approach to addressing the privacy-utility trade-off in medical imaging research. By using synthetic data, the researchers were able to develop accurate cancer classification models without compromising patient privacy.
However, the authors acknowledge that there are still limitations to the synthetic data generation techniques, and more research is needed to fully understand the trade-off between privacy and utility in this context. Additionally, the performance of the synthetic data-based models may be sensitive to the specific dataset and preprocessing steps used, which could limit their generalizability.
Further research is also needed to understand the broader implications and potential real-world applications of this approach, as well as to address any ethical concerns that may arise from the use of synthetic data in medical decision-making.
Conclusion
This paper presents a promising approach to enhancing the utility of privacy-preserving cancer classification models by leveraging synthetic data. The results suggest that, in some cases, models trained on synthetic breast cancer images can outperform those trained on real patient data, potentially making privacy-preserving cancer diagnosis more feasible.
The techniques explored in this research, such as differentially private synthetic image generation and GAN-based approaches, demonstrate the potential of synthetic data to address the privacy-utility trade-off in medical imaging applications. As the field of synthetic data continues to evolve, this work highlights the important role it can play in unlocking the benefits of medical AI while safeguarding patient privacy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing the Utility of Privacy-Preserving Cancer Classification using Synthetic Data
Richard Osuala, Daniel M. Lang, Anneliese Riess, Georgios Kaissis, Zuzanna Szafranowska, Grzegorz Skorupko, Oliver Diaz, Julia A. Schnabel, Karim Lekadir
Deep learning holds immense promise for aiding radiologists in breast cancer detection. However, achieving optimal model performance is hampered by limitations in availability and sharing of data commonly associated to patient privacy concerns. Such concerns are further exacerbated, as traditional deep learning models can inadvertently leak sensitive training information. This work addresses these challenges exploring and quantifying the utility of privacy-preserving deep learning techniques, concretely, (i) differentially private stochastic gradient descent (DP-SGD) and (ii) fully synthetic training data generated by our proposed malignancy-conditioned generative adversarial network. We assess these methods via downstream malignancy classification of mammography masses using a transformer model. Our experimental results depict that synthetic data augmentation can improve privacy-utility tradeoffs in differentially private model training. Further, model pretraining on synthetic data achieves remarkable performance, which can be further increased with DP-SGD fine-tuning across all privacy guarantees. With this first in-depth exploration of privacy-preserving deep learning in breast imaging, we address current and emerging clinical privacy requirements and pave the way towards the adoption of private high-utility deep diagnostic models. Our reproducible codebase is publicly available at https://github.com/RichardObi/mammo_dp.
Read more7/18/2024

0
Controllable Synthetic Clinical Note Generation with Privacy Guarantees
Tal Baumel (Ari), Andre Manoel (Ari), Daniel Jones (Ari), Shize Su (Ari), Huseyin Inan (Ari), Aaron (Ari), Bornstein, Robert Sim
In the field of machine learning, domain-specific annotated data is an invaluable resource for training effective models. However, in the medical domain, this data often includes Personal Health Information (PHI), raising significant privacy concerns. The stringent regulations surrounding PHI limit the availability and sharing of medical datasets, which poses a substantial challenge for researchers and practitioners aiming to develop advanced machine learning models. In this paper, we introduce a novel method to clone datasets containing PHI. Our approach ensures that the cloned datasets retain the essential characteristics and utility of the original data without compromising patient privacy. By leveraging differential-privacy techniques and a novel fine-tuning task, our method produces datasets that are free from identifiable information while preserving the statistical properties necessary for model training. We conduct utility testing to evaluate the performance of machine learning models trained on the cloned datasets. The results demonstrate that our cloned datasets not only uphold privacy standards but also enhance model performance compared to those trained on traditional anonymized datasets. This work offers a viable solution for the ethical and effective utilization of sensitive medical data in machine learning, facilitating progress in medical research and the development of robust predictive models.
Read more9/14/2024
🖼️
0
PrivImage: Differentially Private Synthetic Image Generation using Diffusion Models with Semantic-Aware Pretraining
Kecen Li, Chen Gong, Zhixiang Li, Yuzhong Zhao, Xinwen Hou, Tianhao Wang
Differential Privacy (DP) image data synthesis, which leverages the DP technique to generate synthetic data to replace the sensitive data, allowing organizations to share and utilize synthetic images without privacy concerns. Previous methods incorporate the advanced techniques of generative models and pre-training on a public dataset to produce exceptional DP image data, but suffer from problems of unstable training and massive computational resource demands. This paper proposes a novel DP image synthesis method, termed PRIVIMAGE, which meticulously selects pre-training data, promoting the efficient creation of DP datasets with high fidelity and utility. PRIVIMAGE first establishes a semantic query function using a public dataset. Then, this function assists in querying the semantic distribution of the sensitive dataset, facilitating the selection of data from the public dataset with analogous semantics for pre-training. Finally, we pre-train an image generative model using the selected data and then fine-tune this model on the sensitive dataset using Differentially Private Stochastic Gradient Descent (DP-SGD). PRIVIMAGE allows us to train a lightly parameterized generative model, reducing the noise in the gradient during DP-SGD training and enhancing training stability. Extensive experiments demonstrate that PRIVIMAGE uses only 1% of the public dataset for pre-training and 7.6% of the parameters in the generative model compared to the state-of-the-art method, whereas achieves superior synthetic performance and conserves more computational resources. On average, PRIVIMAGE achieves 30.1% lower FID and 12.6% higher Classification Accuracy than the state-of-the-art method. The replication package and datasets can be accessed online.
Read more4/16/2024
0
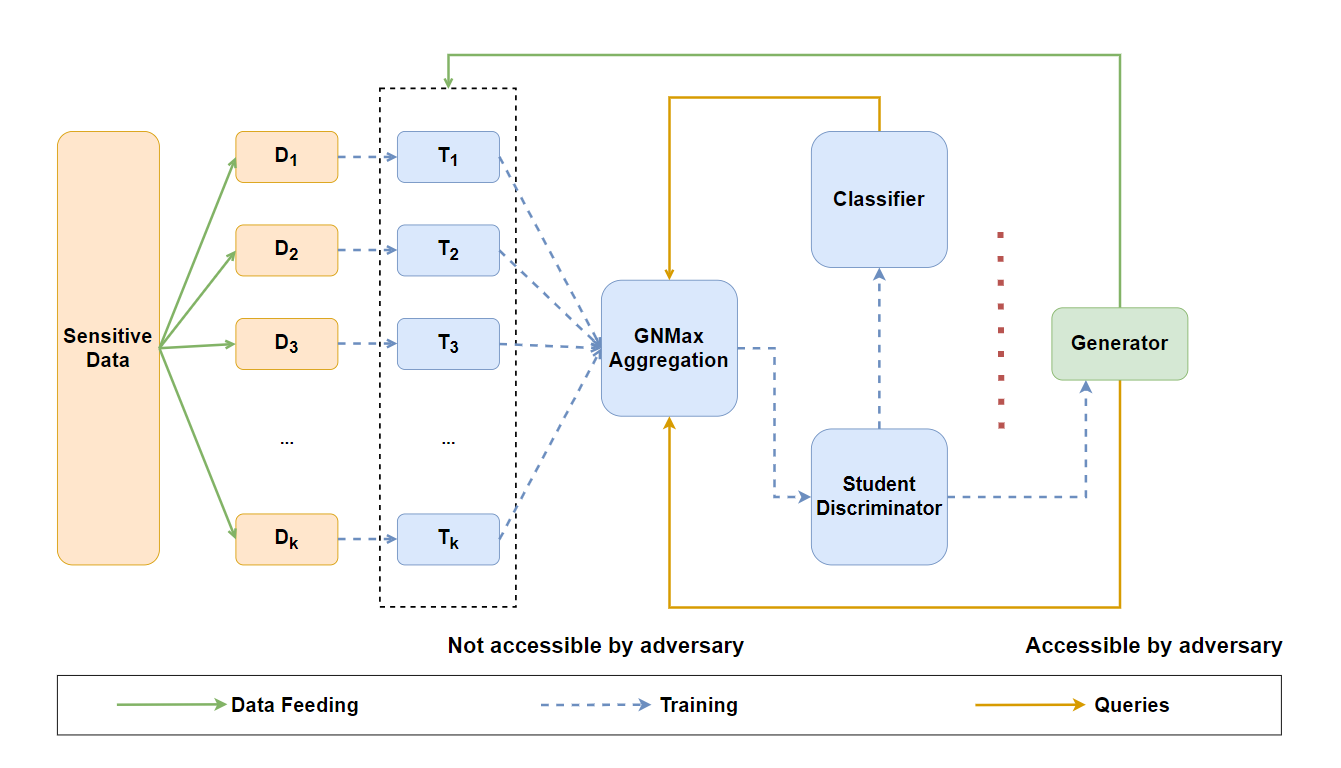
PATE-TripleGAN: Privacy-Preserving Image Synthesis with Gaussian Differential Privacy
Zepeng Jiang, Weiwei Ni, Yifan Zhang
Conditional Generative Adversarial Networks (CGANs) exhibit significant potential in supervised learning model training by virtue of their ability to generate realistic labeled images. However, numerous studies have indicated the privacy leakage risk in CGANs models. The solution DPCGAN, incorporating the differential privacy framework, faces challenges such as heavy reliance on labeled data for model training and potential disruptions to original gradient information due to excessive gradient clipping, making it difficult to ensure model accuracy. To address these challenges, we present a privacy-preserving training framework called PATE-TripleGAN. This framework incorporates a classifier to pre-classify unlabeled data, establishing a three-party min-max game to reduce dependence on labeled data. Furthermore, we present a hybrid gradient desensitization algorithm based on the Private Aggregation of Teacher Ensembles (PATE) framework and Differential Private Stochastic Gradient Descent (DPSGD) method. This algorithm allows the model to retain gradient information more effectively while ensuring privacy protection, thereby enhancing the model's utility. Privacy analysis and extensive experiments affirm that the PATE-TripleGAN model can generate a higher quality labeled image dataset while ensuring the privacy of the training data.
Read more4/22/2024