Controllable Synthetic Clinical Note Generation with Privacy Guarantees

0

Sign in to get full access
Overview
- The paper presents a method for generating synthetic clinical notes while preserving the privacy of patient data.
- The approach uses language models and differential privacy techniques to create realistic but anonymized medical notes.
- The generated notes can be customized based on specific attributes, making them useful for training machine learning models.
- The proposed system aims to balance the utility of the synthetic data with strong privacy guarantees.
Plain English Explanation
The paper describes a way to create artificial medical notes that look and sound realistic, but without using any real patient information. This is important because medical data is very sensitive and private, so we need to be very careful about how it's used.
The researchers use advanced language models to generate the synthetic notes. These models are trained on lots of real medical notes, so the generated notes have a similar style and content. But the researchers also apply privacy techniques to ensure the notes don't contain any real patient details.
One key feature is that the generated notes can be customized based on specific attributes, like the patient's age, gender, or medical condition. This makes the synthetic data more useful for training machine learning models to analyze medical information.
Overall, the goal is to create a realistic but private dataset that can be used for medical research and development, without compromising the privacy of real patients.
Technical Explanation
The paper presents a novel approach for generating controllable synthetic clinical notes with strong privacy guarantees. The system uses a language model trained on a large corpus of real medical notes to generate new, realistic-looking notes.
To preserve privacy, the researchers apply differential privacy techniques during the note generation process. This ensures that the synthetic notes do not contain any identifiable information about real patients.
The generated notes can be customized based on various attributes, such as the patient's age, gender, or medical condition. This controllability allows the synthetic data to be tailored for specific use cases, such as training machine learning models for medical applications.
The authors evaluate the proposed system using both qualitative and quantitative metrics. They demonstrate that the synthetic notes are comparable to real notes in terms of clinical accuracy and readability, while providing strong privacy protections.
Critical Analysis
The paper presents a compelling approach for generating synthetic clinical notes with privacy guarantees. The use of differential privacy techniques is a robust way to ensure that the generated notes do not contain any real patient information, which is crucial for maintaining patient privacy.
One potential limitation is the reliance on a single language model for generating the notes. While the authors report good results, a more diverse ensemble of models may improve the overall quality and diversity of the synthetic notes.
Additionally, the paper does not fully address the potential biases that may be present in the training data for the language model. If the real clinical notes used for training exhibit biases, these biases may be reflected in the generated synthetic notes, which could impact the utility of the data for certain applications.
Further research could explore the integration of bias mitigation techniques into the note generation process to address these concerns.
Conclusion
The paper presents a promising approach for generating synthetic clinical notes while preserving patient privacy. The ability to customize the generated notes based on specific attributes makes the synthetic data valuable for training machine learning models in the medical domain.
The strong privacy guarantees provided by the differential privacy techniques are a key strength of the proposed system, ensuring that the generated notes do not compromise the confidentiality of real patient information.
This work represents an important step towards developing synthetic healthcare datasets that can drive innovation in medical research and AI applications, while respecting the privacy and security of sensitive patient data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Controllable Synthetic Clinical Note Generation with Privacy Guarantees
Tal Baumel (Ari), Andre Manoel (Ari), Daniel Jones (Ari), Shize Su (Ari), Huseyin Inan (Ari), Aaron (Ari), Bornstein, Robert Sim
In the field of machine learning, domain-specific annotated data is an invaluable resource for training effective models. However, in the medical domain, this data often includes Personal Health Information (PHI), raising significant privacy concerns. The stringent regulations surrounding PHI limit the availability and sharing of medical datasets, which poses a substantial challenge for researchers and practitioners aiming to develop advanced machine learning models. In this paper, we introduce a novel method to clone datasets containing PHI. Our approach ensures that the cloned datasets retain the essential characteristics and utility of the original data without compromising patient privacy. By leveraging differential-privacy techniques and a novel fine-tuning task, our method produces datasets that are free from identifiable information while preserving the statistical properties necessary for model training. We conduct utility testing to evaluate the performance of machine learning models trained on the cloned datasets. The results demonstrate that our cloned datasets not only uphold privacy standards but also enhance model performance compared to those trained on traditional anonymized datasets. This work offers a viable solution for the ethical and effective utilization of sensitive medical data in machine learning, facilitating progress in medical research and the development of robust predictive models.
Read more9/14/2024
💬
0
Robust Privacy Amidst Innovation with Large Language Models Through a Critical Assessment of the Risks
Yao-Shun Chuang, Atiquer Rahman Sarkar, Yu-Chun Hsu, Noman Mohammed, Xiaoqian Jiang
This study examines integrating EHRs and NLP with large language models (LLMs) to improve healthcare data management and patient care. It focuses on using advanced models to create secure, HIPAA-compliant synthetic patient notes for biomedical research. The study used de-identified and re-identified MIMIC III datasets with GPT-3.5, GPT-4, and Mistral 7B to generate synthetic notes. Text generation employed templates and keyword extraction for contextually relevant notes, with one-shot generation for comparison. Privacy assessment checked PHI occurrence, while text utility was tested using an ICD-9 coding task. Text quality was evaluated with ROUGE and cosine similarity metrics to measure semantic similarity with source notes. Analysis of PHI occurrence and text utility via the ICD-9 coding task showed that the keyword-based method had low risk and good performance. One-shot generation showed the highest PHI exposure and PHI co-occurrence, especially in geographic location and date categories. The Normalized One-shot method achieved the highest classification accuracy. Privacy analysis revealed a critical balance between data utility and privacy protection, influencing future data use and sharing. Re-identified data consistently outperformed de-identified data. This study demonstrates the effectiveness of keyword-based methods in generating privacy-protecting synthetic clinical notes that retain data usability, potentially transforming clinical data-sharing practices. The superior performance of re-identified over de-identified data suggests a shift towards methods that enhance utility and privacy by using dummy PHIs to perplex privacy attacks.
Read more9/17/2024

0
Enhancing the Utility of Privacy-Preserving Cancer Classification using Synthetic Data
Richard Osuala, Daniel M. Lang, Anneliese Riess, Georgios Kaissis, Zuzanna Szafranowska, Grzegorz Skorupko, Oliver Diaz, Julia A. Schnabel, Karim Lekadir
Deep learning holds immense promise for aiding radiologists in breast cancer detection. However, achieving optimal model performance is hampered by limitations in availability and sharing of data commonly associated to patient privacy concerns. Such concerns are further exacerbated, as traditional deep learning models can inadvertently leak sensitive training information. This work addresses these challenges exploring and quantifying the utility of privacy-preserving deep learning techniques, concretely, (i) differentially private stochastic gradient descent (DP-SGD) and (ii) fully synthetic training data generated by our proposed malignancy-conditioned generative adversarial network. We assess these methods via downstream malignancy classification of mammography masses using a transformer model. Our experimental results depict that synthetic data augmentation can improve privacy-utility tradeoffs in differentially private model training. Further, model pretraining on synthetic data achieves remarkable performance, which can be further increased with DP-SGD fine-tuning across all privacy guarantees. With this first in-depth exploration of privacy-preserving deep learning in breast imaging, we address current and emerging clinical privacy requirements and pave the way towards the adoption of private high-utility deep diagnostic models. Our reproducible codebase is publicly available at https://github.com/RichardObi/mammo_dp.
Read more7/18/2024
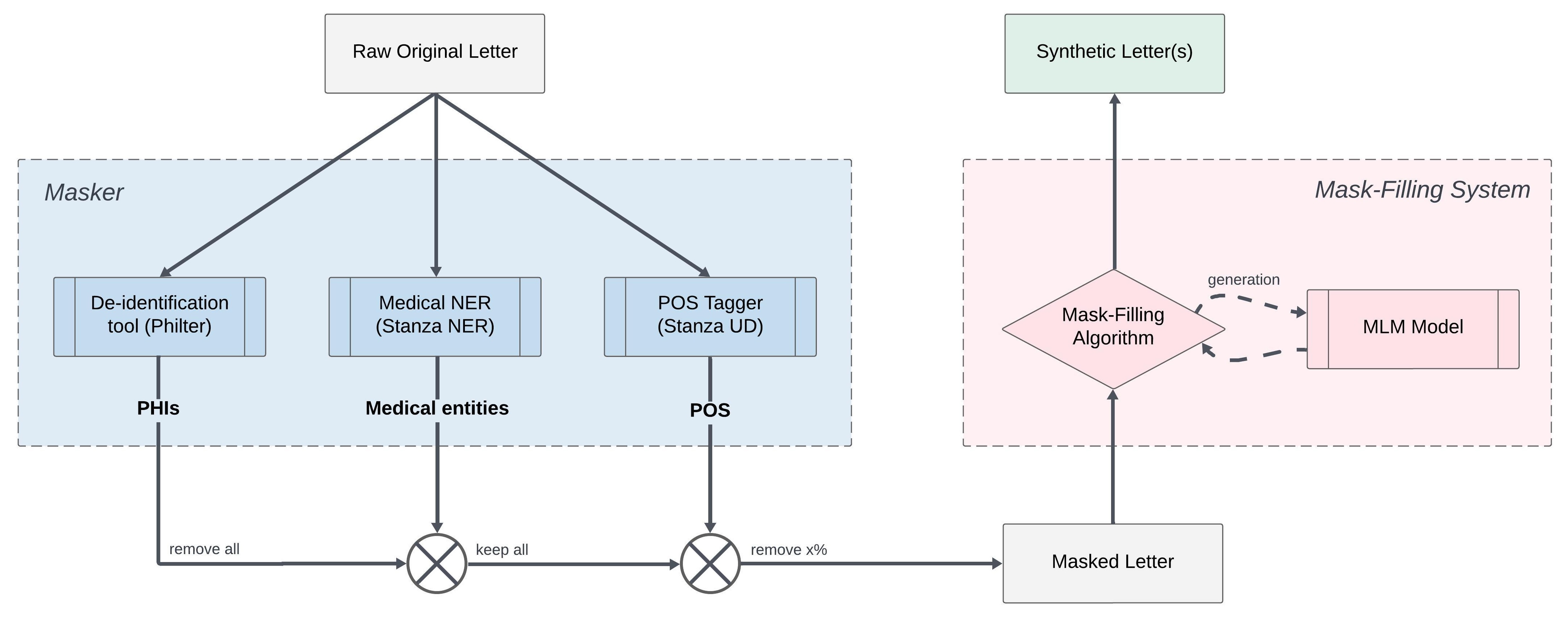
0
New!Generating Synthetic Free-text Medical Records with Low Re-identification Risk using Masked Language Modeling
Samuel Belkadi, Libo Ren, Nicolo Micheletti, Lifeng Han, Goran Nenadic
In this paper, we present a system that generates synthetic free-text medical records, such as discharge summaries, admission notes and doctor correspondences, using Masked Language Modeling (MLM). Our system is designed to preserve the critical information of the records while introducing significant diversity and minimizing re-identification risk. The system incorporates a de-identification component that uses Philter to mask Protected Health Information (PHI), followed by a Medical Entity Recognition (NER) model to retain key medical information. We explore various masking ratios and mask-filling techniques to balance the trade-off between diversity and fidelity in the synthetic outputs without affecting overall readability. Our results demonstrate that the system can produce high-quality synthetic data with significant diversity while achieving a HIPAA-compliant PHI recall rate of 0.96 and a low re-identification risk of 0.035. Furthermore, downstream evaluations using a NER task reveal that the synthetic data can be effectively used to train models with performance comparable to those trained on real data. The flexibility of the system allows it to be adapted for specific use cases, making it a valuable tool for privacy-preserving data generation in medical research and healthcare applications.
Read more9/18/2024