Enhancing Vision-Language Model with Unmasked Token Alignment

0

Sign in to get full access
Overview
- Proposes an approach to enhance vision-language models by aligning unmasked tokens during pretraining
- Aims to improve the model's understanding of the relationship between visual and textual information
- Builds on previous work in text-image mutual awareness, caption diversity, and ranking-consistent pretraining
Plain English Explanation
Vision-language models are AI systems that can understand and generate text based on visual information, like describing an image. The paper proposes a new way to train these models to better learn the connections between what they see and what they say.
The key idea is to have the model pay attention to the relationship between the words it uses and the visual elements in an image, even for words that aren't "masked" (hidden from the model during training). This helps the model understand how language and visuals are linked, beyond just the specific words that describe an image.
By focusing on these unmasked word-image connections, the model can build a richer understanding of the visual world and how it relates to language. This could lead to vision-language models that are more accurate, versatile, and better at tasks like image captioning, visual question answering, and multimodal reasoning.
The approach builds on previous research in areas like text-image mutual awareness, caption diversity, and ranking-consistent pretraining, which have explored different ways to improve the interaction between visual and textual information in AI models.
Technical Explanation
The paper proposes a training approach called "Unmasked Token Alignment" (UTA) to enhance vision-language models. During pretraining, the model is shown image-text pairs, and in addition to predicting masked tokens (as in standard masked language modeling), the model also learns to align the unmasked tokens with the corresponding visual elements in the image.
This is achieved by introducing an additional loss function that encourages the model to correctly associate unmasked tokens with the relevant visual features. The authors show that this improves the model's ability to understand the relationship between language and vision, leading to better performance on a range of vision-language tasks.
The UTA approach builds on insights from previous work, such as the emerging property of masked tokens and the importance of ranking-consistent pretraining for vision-language models. By focusing on the unmasked tokens, the model can learn richer cross-modal associations that go beyond just the specific words used to describe an image.
Critical Analysis
The paper presents a well-designed study that demonstrates the potential benefits of the proposed UTA approach. However, it is important to note that the experiments were conducted on a limited set of vision-language tasks, and the generalization of the findings to a broader range of applications remains to be seen.
Additionally, the paper does not provide a detailed analysis of the computational cost and training time required for the UTA approach compared to standard pretraining methods. This information would be valuable for assessing the practical applicability of the technique, especially in resource-constrained settings.
Further research could explore the interplay between the UTA approach and other caption quality and pretraining techniques to better understand the synergies and tradeoffs involved. Investigating the interpretability and explainability of the learned associations between unmasked tokens and visual features could also provide valuable insights.
Conclusion
The proposed Unmasked Token Alignment (UTA) approach offers a promising direction for enhancing vision-language models by explicitly aligning unmasked textual tokens with corresponding visual elements during pretraining. This technique aims to improve the model's understanding of the complex relationships between language and vision, which could lead to better performance on a variety of vision-language tasks.
While the paper presents compelling results, further research is needed to assess the broader applicability and practical implications of the UTA approach. Exploring the interplay with other pretraining techniques and investigating the interpretability of the learned associations could provide valuable insights and guide the development of more capable and robust vision-language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Vision-Language Model with Unmasked Token Alignment
Jihao Liu, Jinliang Zheng, Boxiao Liu, Yu Liu, Hongsheng Li
Contrastive pre-training on image-text pairs, exemplified by CLIP, becomes a standard technique for learning multi-modal visual-language representations. Although CLIP has demonstrated remarkable performance, training it from scratch on noisy web-scale datasets is computationally demanding. On the other hand, mask-then-predict pre-training approaches, like Masked Image Modeling (MIM), offer efficient self-supervised learning for single-modal representations. This paper introduces Unmasked Token Alignment (UTA), a method that leverages existing CLIP models to further enhance its vision-language representations. UTA trains a Vision Transformer (ViT) by aligning unmasked visual tokens to the corresponding image tokens from a frozen CLIP vision encoder, which automatically aligns the ViT model with the CLIP text encoder. The pre-trained ViT can be directly applied for zero-shot evaluation even without training on image-text pairs. Compared to MIM approaches, UTA does not suffer from training-finetuning inconsistency and is much more training-efficient by avoiding using the extra [MASK] tokens. Extensive experimental results demonstrate that UTA can enhance CLIP models and outperform existing MIM methods on various uni- and multi-modal benchmarks. Code and models are available at https://github.com/jihaonew/UTA.
Read more6/17/2024

0
MTA-CLIP: Language-Guided Semantic Segmentation with Mask-Text Alignment
Anurag Das, Xinting Hu, Li Jiang, Bernt Schiele
Recent approaches have shown that large-scale vision-language models such as CLIP can improve semantic segmentation performance. These methods typically aim for pixel-level vision-language alignment, but often rely on low resolution image features from CLIP, resulting in class ambiguities along boundaries. Moreover, the global scene representations in CLIP text embeddings do not directly correlate with the local and detailed pixel-level features, making meaningful alignment more difficult. To address these limitations, we introduce MTA-CLIP, a novel framework employing mask-level vision-language alignment. Specifically, we first propose Mask-Text Decoder that enhances the mask representations using rich textual data with the CLIP language model. Subsequently, it aligns mask representations with text embeddings using Mask-to-Text Contrastive Learning. Furthermore, we introduce MaskText Prompt Learning, utilizing multiple context-specific prompts for text embeddings to capture diverse class representations across masks. Overall, MTA-CLIP achieves state-of-the-art, surpassing prior works by an average of 2.8% and 1.3% on on standard benchmark datasets, ADE20k and Cityscapes, respectively.
Read more8/1/2024
👀
0
Learning with Unmasked Tokens Drives Stronger Vision Learners
Taekyung Kim, Sanghyuk Chun, Byeongho Heo, Dongyoon Han
Masked image modeling (MIM) has become a leading self-supervised learning strategy. MIMs such as Masked Autoencoder (MAE) learn strong representations by randomly masking input tokens for the encoder to process, with the decoder reconstructing the masked tokens to the input. However, MIM pre-trained encoders often exhibit a limited attention span, attributed to MIM's sole focus on regressing masked tokens only, which may impede the encoder's broader context learning. To tackle the limitation, we improve MIM by explicitly incorporating unmasked tokens into the training process. Specifically, our method enables the encoder to learn from broader context supervision, allowing unmasked tokens to experience broader contexts while the decoder reconstructs masked tokens. Thus, the encoded unmasked tokens are equipped with extensive contextual information, empowering masked tokens to leverage the enhanced unmasked tokens for MIM. As a result, our simple remedy trains more discriminative representations revealed by achieving 84.2% top-1 accuracy with ViT-B on ImageNet-1K with 0.6%p gain. We attribute the success to the enhanced pre-training method, as evidenced by the singular value spectrum and attention analyses. Finally, our models achieve significant performance gains at the downstream semantic segmentation and fine-grained visual classification tasks; and on diverse robust evaluation metrics. Code is available at https://github.com/naver-ai/lut
Read more8/27/2024
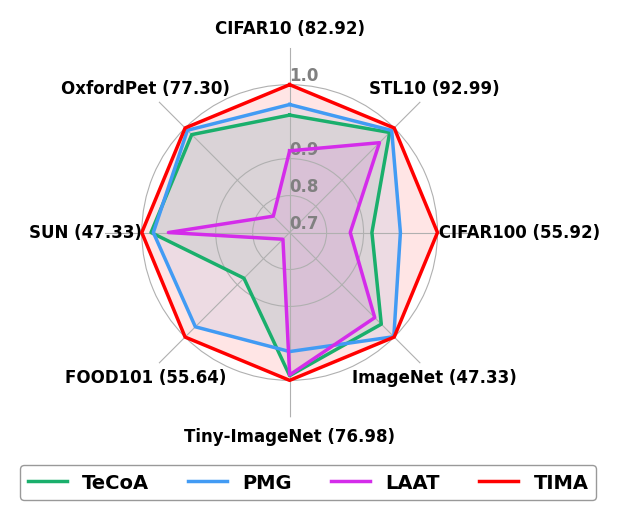
0
TIMA: Text-Image Mutual Awareness for Balancing Zero-Shot Adversarial Robustness and Generalization Ability
Fengji Ma, Li Liu, Hei Victor Cheng
This work addresses the challenge of achieving zero-shot adversarial robustness while preserving zero-shot generalization in large-scale foundation models, with a focus on the popular Contrastive Language-Image Pre-training (CLIP). Although foundation models were reported to have exceptional zero-shot generalization, they are highly vulnerable to adversarial perturbations. Existing methods achieve a comparable good tradeoff between zero-shot adversarial robustness and generalization under small adversarial perturbations. However, they fail to achieve a good tradeoff under large adversarial perturbations. To this end, we propose a novel Text-Image Mutual Awareness (TIMA) method that strikes a balance between zero-shot adversarial robustness and generalization. More precisely, we propose an Image-Aware Text (IAT) tuning mechanism that increases the inter-class distance of text embeddings by incorporating the Minimum Hyperspherical Energy (MHE). Simultaneously, fixed pre-trained image embeddings are used as cross-modal auxiliary supervision to maintain the similarity between the MHE-tuned and original text embeddings by the knowledge distillation, preserving semantic information between different classes. Besides, we introduce a Text-Aware Image (TAI) tuning mechanism, which increases inter-class distance between image embeddings during the training stage by Text-distance based Adaptive Margin (TAM). Similarly, a knowledge distillation is utilized to retain the similarity between fine-tuned and pre-trained image embeddings. Extensive experimental results demonstrate the effectiveness of our approach, showing impressive zero-shot performance against a wide range of adversarial perturbations while preserving the zero-shot generalization capabilities of the original CLIP model.
Read more5/29/2024