TIMA: Text-Image Mutual Awareness for Balancing Zero-Shot Adversarial Robustness and Generalization Ability

0
Sign in to get full access
Overview
• This paper introduces TIMA, a new approach to balancing zero-shot adversarial robustness and generalization ability in vision-language models.
• The key idea is to incorporate "text-image mutual awareness" during training, which helps the model better understand the relationship between visual and textual information.
• This allows the model to maintain strong performance on standard benchmarks while also being more robust to adversarial attacks in zero-shot settings.
Plain English Explanation
Vision-language models are AI systems that can understand and process both images and text. These models have shown impressive performance on a variety of tasks, but they can also be vulnerable to adversarial attacks - where small, carefully crafted changes to an image can cause the model to misclassify it.
The authors of this paper wanted to find a way to make these models more robust to adversarial attacks, while still maintaining their strong generalization ability - the ability to perform well on a wide range of tasks, even ones they haven't been specifically trained on.
Their solution, TIMA, focuses on getting the model to be more "aware" of the relationship between the visual and textual information it's processing. By training the model to pay attention to how the images and text relate to each other, it becomes better equipped to handle adversarial attacks in zero-shot settings - where it needs to classify images it hasn't seen before.
At the same time, this "text-image mutual awareness" also helps the model maintain its strong performance on standard benchmarks, where generalization is key. So TIMA allows vision-language models to be both more robust and more versatile.
Technical Explanation
The key innovation in TIMA is the incorporation of "text-image mutual awareness" during the training process. This means that the model is trained to not only learn the mappings between images and text, but also to understand how the visual and textual information are related and dependent on each other.
Specifically, the authors propose a new training objective that encourages the model to predict the text given the image, and vice versa. This "mutual prediction" task helps the model develop a deeper understanding of the multimodal relationships in the data.
In addition, the authors leverage adversarial prompt tuning and compositional image-text matching techniques to further improve the model's zero-shot adversarial robustness and generalization ability.
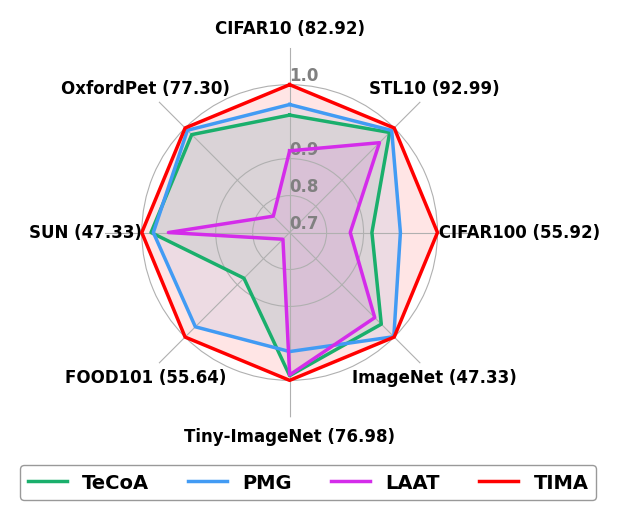
The authors evaluate TIMA on standard vision-language benchmarks as well as zero-shot adversarial robustness tests. Their results show that TIMA outperforms previous state-of-the-art models in terms of balancing these two important capabilities.
Critical Analysis
The authors acknowledge that TIMA, like other vision-language models, may still be vulnerable to certain types of adversarial attacks, such as those that exploit the model's biases or weaknesses in specific domains. They also note that the mutual prediction task can be computationally expensive, which may limit its scalability.
Additionally, the paper does not provide a detailed analysis of the model's performance on specific types of zero-shot tasks or adversarial attacks. Further research would be needed to fully understand the model's strengths and weaknesses in these areas.
That said, the authors' approach of incorporating text-image mutual awareness is a promising direction for improving the robustness and generalization of vision-language models. The Revisiting Adversarial Robustness in Vision-Language Models and Test-Time Zero-Shot Generalization in Vision-Language papers provide additional context and insights on these important challenges.
Conclusion
The TIMA paper presents a novel approach to balancing zero-shot adversarial robustness and generalization ability in vision-language models. By incorporating text-image mutual awareness during training, the model is able to better understand the relationship between visual and textual information, which in turn improves its performance on both standard benchmarks and zero-shot adversarial robustness tests.
This work represents an important step forward in making vision-language models more reliable and versatile, with potential applications in areas like image classification, question answering, and multimodal reasoning. As the field of AI continues to advance, techniques like TIMA will be increasingly important for developing robust and generalizable models that can be safely deployed in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TIMA: Text-Image Mutual Awareness for Balancing Zero-Shot Adversarial Robustness and Generalization Ability
Fengji Ma, Li Liu, Hei Victor Cheng
This work addresses the challenge of achieving zero-shot adversarial robustness while preserving zero-shot generalization in large-scale foundation models, with a focus on the popular Contrastive Language-Image Pre-training (CLIP). Although foundation models were reported to have exceptional zero-shot generalization, they are highly vulnerable to adversarial perturbations. Existing methods achieve a comparable good tradeoff between zero-shot adversarial robustness and generalization under small adversarial perturbations. However, they fail to achieve a good tradeoff under large adversarial perturbations. To this end, we propose a novel Text-Image Mutual Awareness (TIMA) method that strikes a balance between zero-shot adversarial robustness and generalization. More precisely, we propose an Image-Aware Text (IAT) tuning mechanism that increases the inter-class distance of text embeddings by incorporating the Minimum Hyperspherical Energy (MHE). Simultaneously, fixed pre-trained image embeddings are used as cross-modal auxiliary supervision to maintain the similarity between the MHE-tuned and original text embeddings by the knowledge distillation, preserving semantic information between different classes. Besides, we introduce a Text-Aware Image (TAI) tuning mechanism, which increases inter-class distance between image embeddings during the training stage by Text-distance based Adaptive Margin (TAM). Similarly, a knowledge distillation is utilized to retain the similarity between fine-tuned and pre-trained image embeddings. Extensive experimental results demonstrate the effectiveness of our approach, showing impressive zero-shot performance against a wide range of adversarial perturbations while preserving the zero-shot generalization capabilities of the original CLIP model.
Read more5/29/2024

0
Revisiting the Robust Generalization of Adversarial Prompt Tuning
Fan Yang, Mingxuan Xia, Sangzhou Xia, Chicheng Ma, Hui Hui
Understanding the vulnerability of large-scale pre-trained vision-language models like CLIP against adversarial attacks is key to ensuring zero-shot generalization capacity on various downstream tasks. State-of-the-art defense mechanisms generally adopt prompt learning strategies for adversarial fine-tuning to improve the adversarial robustness of the pre-trained model while keeping the efficiency of adapting to downstream tasks. Such a setup leads to the problem of over-fitting which impedes further improvement of the model's generalization capacity on both clean and adversarial examples. In this work, we propose an adaptive Consistency-guided Adversarial Prompt Tuning (i.e., CAPT) framework that utilizes multi-modal prompt learning to enhance the alignment of image and text features for adversarial examples and leverage the strong generalization of pre-trained CLIP to guide the model-enhancing its robust generalization on adversarial examples while maintaining its accuracy on clean ones. We also design a novel adaptive consistency objective function to balance the consistency of adversarial inputs and clean inputs between the fine-tuning model and the pre-trained model. We conduct extensive experiments across 14 datasets and 4 data sparsity schemes (from 1-shot to full training data settings) to show the superiority of CAPT over other state-of-the-art adaption methods. CAPT demonstrated excellent performance in terms of the in-distribution performance and the generalization under input distribution shift and across datasets.
Read more5/21/2024
0
Towards Alleviating Text-to-Image Retrieval Hallucination for CLIP in Zero-shot Learning
Hanyao Wang, Yibing Zhan, Liu Liu, Liang Ding, Yan Yang, Jun Yu
Pretrained cross-modal models, for instance, the most representative CLIP, have recently led to a boom in using pre-trained models for cross-modal zero-shot tasks, considering the generalization properties. However, we analytically discover that CLIP suffers from the text-to-image retrieval hallucination, adversely limiting its capabilities under zero-shot learning: CLIP would select the image with the highest score when asked to figure out which image perfectly matches one given query text among several candidate images even though CLIP knows contents in the image. Accordingly, we propose a Balanced Score with Auxiliary Prompts (BSAP) to mitigate the CLIP's text-to-image retrieval hallucination under zero-shot learning. Specifically, we first design auxiliary prompts to provide multiple reference outcomes for every single image retrieval, then the outcomes derived from each retrieved image in conjunction with the target text are normalized to obtain the final similarity, which alleviates hallucinations in the model. Additionally, we can merge CLIP's original results and BSAP to obtain a more robust hybrid outcome (BSAP-H). Extensive experiments on two typical zero-shot learning tasks, i.e., Referring Expression Comprehension (REC) and Referring Image Segmentation (RIS), are conducted to demonstrate the effectiveness of our BSAP. Specifically, when evaluated on the validation dataset of RefCOCO in REC, BSAP increases CLIP's performance by 20.6%. Further, we validate that our strategy could be applied in other types of pretrained cross-modal models, such as ALBEF and BLIP.
Read more6/28/2024
🖼️
0
ComCLIP: Training-Free Compositional Image and Text Matching
Kenan Jiang, Xuehai He, Ruize Xu, Xin Eric Wang
Contrastive Language-Image Pretraining (CLIP) has demonstrated great zero-shot performance for matching images and text. However, it is still challenging to adapt vision-lanaguage pretrained models like CLIP to compositional image and text matching -- a more challenging image and text matching task requiring the model understanding of compositional word concepts and visual components. Towards better compositional generalization in zero-shot image and text matching, in this paper, we study the problem from a causal perspective: the erroneous semantics of individual entities are essentially confounders that cause the matching failure. Therefore, we propose a novel textbf{textit{training-free}} compositional CLIP model (ComCLIP). ComCLIP disentangles input images into subjects, objects, and action sub-images and composes CLIP's vision encoder and text encoder to perform evolving matching over compositional text embedding and sub-image embeddings. In this way, ComCLIP can mitigate spurious correlations introduced by the pretrained CLIP models and dynamically evaluate the importance of each component. Experiments on four compositional image-text matching datasets: SVO, ComVG, Winoground, and VL-checklist, and two general image-text retrieval datasets: Flick30K, and MSCOCO demonstrate the effectiveness of our plug-and-play method, which boosts the textbf{textit{zero-shot}} inference ability of CLIP, SLIP, and BLIP2 even without further training or fine-tuning. Our codes can be found at https://github.com/eric-ai-lab/ComCLIP.
Read more4/16/2024