Ensemble Successor Representations for Task Generalization in Offline-to-Online Reinforcement Learning
2405.07223
0
0
Abstract
In Reinforcement Learning (RL), training a policy from scratch with online experiences can be inefficient because of the difficulties in exploration. Recently, offline RL provides a promising solution by giving an initialized offline policy, which can be refined through online interactions. However, existing approaches primarily perform offline and online learning in the same task, without considering the task generalization problem in offline-to-online adaptation. In real-world applications, it is common that we only have an offline dataset from a specific task while aiming for fast online-adaptation for several tasks. To address this problem, our work builds upon the investigation of successor representations for task generalization in online RL and extends the framework to incorporate offline-to-online learning. We demonstrate that the conventional paradigm using successor features cannot effectively utilize offline data and improve the performance for the new task by online fine-tuning. To mitigate this, we introduce a novel methodology that leverages offline data to acquire an ensemble of successor representations and subsequently constructs ensemble Q functions. This approach enables robust representation learning from datasets with different coverage and facilitates fast adaption of Q functions towards new tasks during the online fine-tuning phase. Extensive empirical evaluations provide compelling evidence showcasing the superior performance of our method in generalizing to diverse or even unseen tasks.
Create account to get full access
Overview
- This paper introduces a novel approach called Ensemble Successor Representations (ESR) for improving task generalization in offline-to-online reinforcement learning.
- The key idea is to leverage an ensemble of successor representation models to better capture the latent structure of the environment and facilitate transfer learning across tasks.
- The authors demonstrate the effectiveness of ESR on various benchmark environments, showing improved performance compared to existing offline-to-online RL methods.
Plain English Explanation
Reinforcement learning (RL) is a powerful approach for training agents to solve complex problems by interacting with their environment and receiving rewards. However, in many real-world scenarios, the agent may not have the opportunity to explore the environment extensively before being deployed. This is known as the offline-to-online RL setting, where the agent must learn and generalize from a limited set of pre-collected data.
The Ensemble Successor Representations (ESR) method proposed in this paper aims to address this challenge. The core idea is to leverage multiple "successor representation" models, which can capture the underlying structure of the environment and facilitate transfer learning across different tasks. By using an ensemble of these models, the agent can better understand the environment and adapt more effectively when deployed online.
The authors demonstrate the effectiveness of ESR on a variety of benchmark environments, showing that it outperforms existing offline-to-online RL approaches. This work has important implications for real-world applications, where agents need to quickly adapt and perform well without extensive exploration.
Technical Explanation
The paper introduces the Ensemble Successor Representations (ESR) framework for improving task generalization in the offline-to-online RL setting. The key components are:
-
Successor Representations: The successor representation (SR) is a neural network model that learns to predict the expected future state visitation from any given state. This provides a compact, predictive representation of the environment that can facilitate transfer learning across tasks.
-
Ensemble of SRs: The authors propose to train an ensemble of SR models, each with a different random initialization. This ensemble captures a more diverse set of latent representations of the environment, leading to better generalization.
-
Offline-to-Online RL: The agent first pre-trains the ESR model on the offline dataset, then fine-tunes it during online deployment to adapt to the target task. The ensemble nature of ESR allows for more robust and effective transfer learning.
The paper evaluates ESR on various continuous control benchmarks, including single-task continual offline RL, offline trajectory generalization, OER for continual offline RL, diffusion-based continual offline RL, and multi-task RL for continuous control. The results demonstrate the advantages of ESR over existing offline-to-online RL methods.
Critical Analysis
The paper presents a compelling approach for improving task generalization in offline-to-online RL, but there are a few potential limitations and areas for further research:
-
Ensemble Size: The authors note that the performance of ESR is sensitive to the number of models in the ensemble. The optimal ensemble size may vary depending on the complexity of the environment and the available offline data, which could complicate practical deployment.
-
Computational Overhead: Training and fine-tuning an ensemble of SR models may incur a higher computational cost compared to single-model approaches. This could be a concern for resource-constrained applications.
-
Interpretability: The ensemble nature of ESR makes it more challenging to interpret the learned representations and understand the model's decision-making process. Improving the interpretability of such complex RL systems is an important area for future research.
-
Scalability: While the paper demonstrates the effectiveness of ESR on several benchmark environments, it remains to be seen how well the approach would scale to more complex, large-scale real-world applications with high-dimensional state and action spaces.
Overall, the Ensemble Successor Representations approach is a promising step towards more effective offline-to-online RL, but further research is needed to address the potential limitations and expand the applicability of the method.
Conclusion
This paper introduces Ensemble Successor Representations (ESR), a novel framework for improving task generalization in the offline-to-online reinforcement learning setting. By leveraging an ensemble of successor representation models, ESR can better capture the latent structure of the environment and facilitate more effective transfer learning across tasks.
The authors demonstrate the advantages of ESR on various benchmark environments, showcasing its superior performance compared to existing offline-to-online RL methods. This work has important implications for real-world applications where agents need to quickly adapt and perform well without extensive exploration of the environment.
While the paper presents a compelling approach, there are still some potential limitations and areas for further research, such as the impact of ensemble size, computational overhead, interpretability, and scalability. Addressing these challenges could help expand the applicability of ESR and drive further advancements in offline-to-online reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Model-Based Reinforcement Learning with Multi-Task Offline Pretraining
Minting Pan, Yitao Zheng, Yunbo Wang, Xiaokang Yang
0
0
Pretraining reinforcement learning (RL) models on offline datasets is a promising way to improve their training efficiency in online tasks, but challenging due to the inherent mismatch in dynamics and behaviors across various tasks. We present a model-based RL method that learns to transfer potentially useful dynamics and action demonstrations from offline data to a novel task. The main idea is to use the world models not only as simulators for behavior learning but also as tools to measure the task relevance for both dynamics representation transfer and policy transfer. We build a time-varying, domain-selective distillation loss to generate a set of offline-to-online similarity weights. These weights serve two purposes: (i) adaptively transferring the task-agnostic knowledge of physical dynamics to facilitate world model training, and (ii) learning to replay relevant source actions to guide the target policy. We demonstrate the advantages of our approach compared with the state-of-the-art methods in Meta-World and DeepMind Control Suite.
6/6/2024
Discovering Multiple Solutions from a Single Task in Offline Reinforcement Learning
Takayuki Osa, Tatsuya Harada
0
0
Recent studies on online reinforcement learning (RL) have demonstrated the advantages of learning multiple behaviors from a single task, as in the case of few-shot adaptation to a new environment. Although this approach is expected to yield similar benefits in offline RL, appropriate methods for learning multiple solutions have not been fully investigated in previous studies. In this study, we therefore addressed the problem of finding multiple solutions from a single task in offline RL. We propose algorithms that can learn multiple solutions in offline RL, and empirically investigate their performance. Our experimental results show that the proposed algorithm learns multiple qualitatively and quantitatively distinctive solutions in offline RL.
6/11/2024

Single-Task Continual Offline Reinforcement Learning
Sibo Gai, Donglin Wang
0
0
In this paper, we study the continual learning problem of single-task offline reinforcement learning. In the past, continual reinforcement learning usually only dealt with multitasking, that is, learning multiple related or unrelated tasks in a row, but once each learned task was learned, it was not relearned, but only used in subsequent processes. However, offline reinforcement learning tasks require the continuously learning of multiple different datasets for the same task. Existing algorithms will try their best to achieve the best results in each offline dataset they have learned and the skills of the network will overwrite the high-quality datasets that have been learned after learning the subsequent poor datasets. On the other hand, if too much emphasis is placed on stability, the network will learn the subsequent better dataset after learning the poor offline dataset, and the problem of insufficient plasticity and non-learning will occur. How to design a strategy that can always preserve the best performance for each state in the data that has been learned is a new challenge and the focus of this study. Therefore, this study proposes a new algorithm, called Ensemble Offline Reinforcement Learning Based on Experience Replay, which introduces multiple value networks to learn the same dataset and judge whether the strategy has been learned by the discrete degree of the value network, to improve the performance of the network in single-task offline reinforcement learning.
5/6/2024
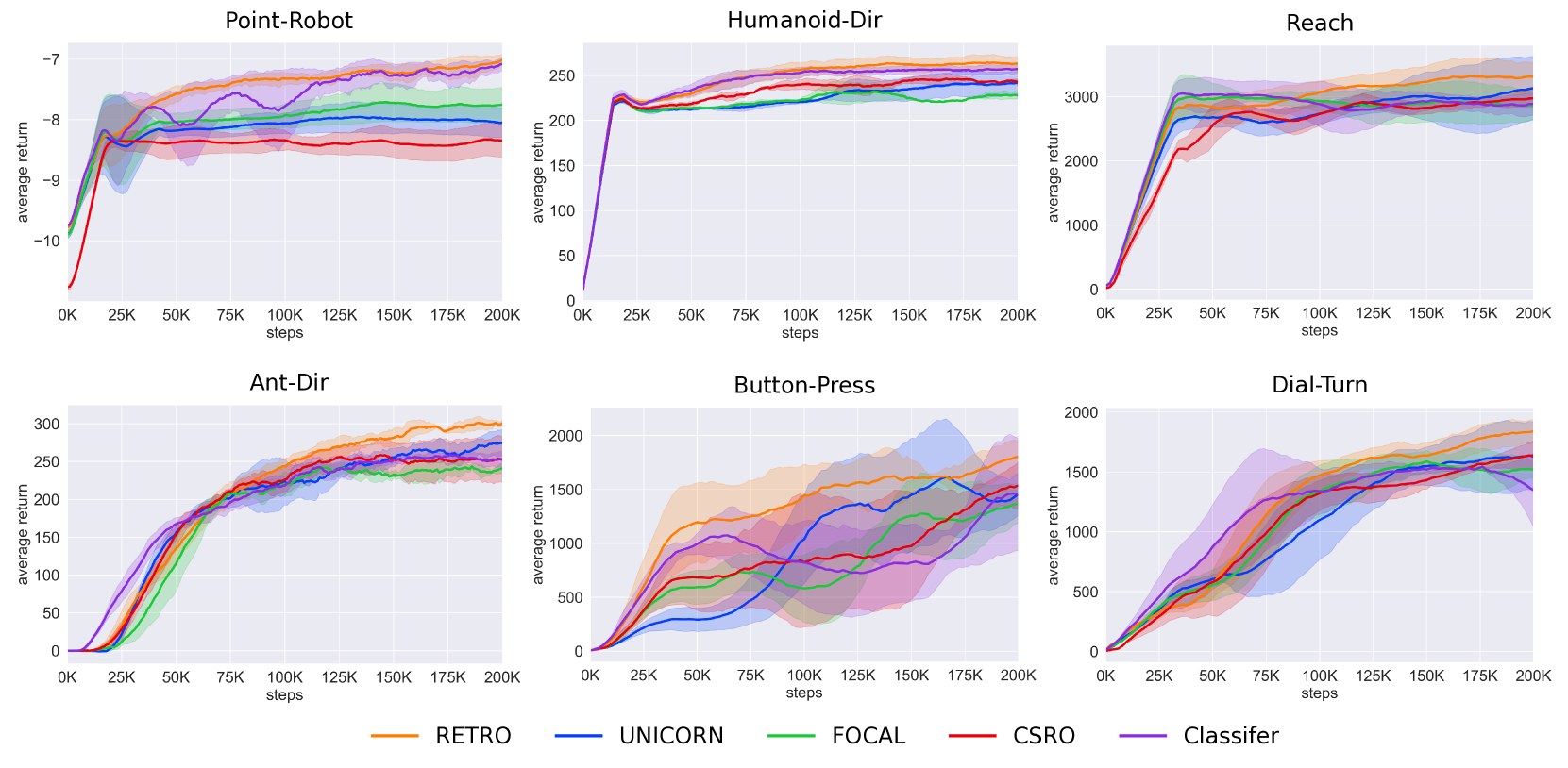
Scrutinize What We Ignore: Reining Task Representation Shift In Context-Based Offline Meta Reinforcement Learning
Hai Zhang, Boyuan Zheng, Anqi Guo, Tianying Ji, Pheng-Ann Heng, Junqiao Zhao, Lanqing Li
0
0
Offline meta reinforcement learning (OMRL) has emerged as a promising approach for interaction avoidance and strong generalization performance by leveraging pre-collected data and meta-learning techniques. Previous context-based approaches predominantly rely on the intuition that maximizing the mutual information between the task and the task representation ($I(Z;M)$) can lead to performance improvements. Despite achieving attractive results, the theoretical justification of performance improvement for such intuition has been lacking. Motivated by the return discrepancy scheme in the model-based RL field, we find that maximizing $I(Z;M)$ can be interpreted as consistently raising the lower bound of the expected return for a given policy conditioning on the optimal task representation. However, this optimization process ignores the task representation shift between two consecutive updates, which may lead to performance improvement collapse. To address this problem, we turn to use the framework of performance difference bound to consider the impacts of task representation shift explicitly. We demonstrate that by reining the task representation shift, it is possible to achieve monotonic performance improvements, thereby showcasing the advantage against previous approaches. To make it practical, we design an easy yet highly effective algorithm RETRO (underline{RE}ining underline{T}ask underline{R}epresentation shift in context-based underline{O}ffline meta reinforcement learning) with only adding one line of code compared to the backbone. Empirical results validate its state-of-the-art (SOTA) asymptotic performance, training stability and training-time consumption on MuJoCo and MetaWorld benchmarks.
5/21/2024