Equilibria in multiagent online problems with predictions

0
Sign in to get full access
Overview
- This paper explores equilibrium dynamics in multi-agent online problems where agents can leverage predictions about the future.
- The authors analyze the impact of prediction capabilities on the existence and properties of equilibria in these scenarios.
- They consider both cooperative and competitive settings, and investigate how prediction accuracy affects the emergence of efficient and fair outcomes.
Plain English Explanation
The paper examines situations where multiple intelligent agents, like software programs or robots, interact with each other and make decisions over time. The agents can use predictions about the future to guide their actions. The researchers look at how these prediction capabilities affect the stability and fairness of the final outcomes that emerge from the agents' interactions.
They consider two main scenarios: one where the agents are cooperating to achieve a shared goal, and another where the agents are competing against each other. The key question is how accurate predictions influence the emergence of stable and desirable equilibrium states, where no agent has an incentive to unilaterally change their strategy.
Technical Explanation
The paper analyzes equilibrium dynamics in multi-agent online optimization problems where agents can leverage predictions about future problem instances. The authors consider both cooperative and competitive settings, and investigate how prediction accuracy affects the existence and properties of equilibria.
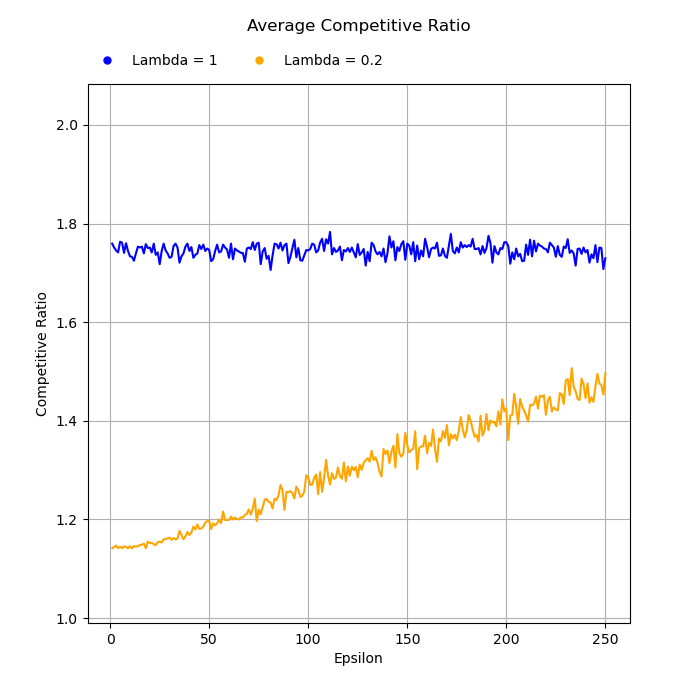
In the cooperative setting, the authors show that high-accuracy predictions can lead to the emergence of efficient and fair equilibria, while low-accuracy predictions may result in biased or suboptimal outcomes. They provide algorithms for caching predictions to reduce the number required without sacrificing performance.
In the competitive setting, the authors characterize the Stackelberg equilibria that arise when agents have access to predictions. They demonstrate that prediction accuracy can lead to the emergence of specialized roles and strategies among the competing agents.
Critical Analysis
The paper provides a rigorous theoretical analysis of the role of predictions in multi-agent online optimization problems. The authors carefully consider the impact of prediction accuracy on the existence and properties of equilibria in both cooperative and competitive settings.
One potential limitation is that the analysis assumes a simplified model of the multi-agent interactions and problem structure. Real-world scenarios may involve more complex dynamics and constraints that are not captured in the theoretical framework. Additionally, the paper does not address the practical challenges of obtaining accurate predictions in realistic settings.
Further research could explore more realistic problem formulations, reinforcement learning approaches for multi-agent training beyond zero-sum games, and the implications of this work for the design of autonomous systems and decision-making algorithms.
Conclusion
This paper makes important contributions to the understanding of equilibrium dynamics in multi-agent online problems with prediction capabilities. The authors demonstrate that prediction accuracy can significantly impact the emergence of efficient, fair, and specialized outcomes, depending on whether the agents are cooperating or competing.
The findings have implications for the design of multi-agent systems, decision-making algorithms, and AI-powered applications that involve complex, dynamic interactions. The insights can help guide the development of more robust and socially responsible autonomous systems that can effectively leverage predictions to achieve desirable collective outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Equilibria in multiagent online problems with predictions
Gabriel Istrate, Cosmin Bonchic{s}, Victor Bogdan
We study the power of (competitive) algorithms with predictions in a multiagent setting. For this we introduce a multiagent version of the ski-rental problem. In this problem agents can collaborate by pooling resources to get a group license for some asset. If the license price is not met agents have to rent the asset individually for the day at a unit price. Otherwise the license becomes available forever to everyone at no extra cost. Our main contribution is a best-response analysis of a single-agent competitive algorithm that assumes perfect knowledge of other agents' actions (but no knowledge of its own renting time). We then analyze the setting when agents have a predictor for their own active time, yielding a tradeoff between robustness and consistency. We investigate the effect of using such a predictor in an equilibrium, as well as the new equilibria formed in this way.
Read more5/21/2024

0
Improving Online Algorithms via ML Predictions
Ravi Kumar, Manish Purohit, Zoya Svitkina
In this work we study the problem of using machine-learned predictions to improve the performance of online algorithms. We consider two classical problems, ski rental and non-clairvoyant job scheduling, and obtain new online algorithms that use predictions to make their decisions. These algorithms are oblivious to the performance of the predictor, improve with better predictions, but do not degrade much if the predictions are poor.
Read more7/26/2024
🔮
0
New!Machine-Learned Prediction Equilibrium for Dynamic Traffic Assignment
Lukas Graf, Tobias Harks, Kostas Kollias, Michael Markl
We study a dynamic traffic assignment model, where agents base their instantaneous routing decisions on real-time delay predictions. We formulate a mathematically concise model and define dynamic prediction equilibrium (DPE) in which no agent can at any point during their journey improve their predicted travel time by switching to a different route. We demonstrate the versatility of our framework by showing that it subsumes the well-known full information and instantaneous information models, in addition to admitting further realistic predictors as special cases. We then proceed to derive properties of the predictors that ensure a dynamic prediction equilibrium exists. Additionally, we define $varepsilon$-approximate DPE wherein no agent can improve their predicted travel time by more than $varepsilon$ and provide further conditions of the predictors under which such an approximate equilibrium can be computed. Finally, we complement our theoretical analysis by an experimental study, in which we systematically compare the induced average travel times of different predictors, including two machine-learning based models trained on data gained from previously computed approximate equilibrium flows, both on synthetic and real world road networks.
Read more9/20/2024

0
Maximizing utility in multi-agent environments by anticipating the behavior of other learners
Angelos Assos, Yuval Dagan, Constantinos Daskalakis
Learning algorithms are often used to make decisions in sequential decision-making environments. In multi-agent settings, the decisions of each agent can affect the utilities/losses of the other agents. Therefore, if an agent is good at anticipating the behavior of the other agents, in particular how they will make decisions in each round as a function of their experience that far, it could try to judiciously make its own decisions over the rounds of the interaction so as to influence the other agents to behave in a way that ultimately benefits its own utility. In this paper, we study repeated two-player games involving two types of agents: a learner, which employs an online learning algorithm to choose its strategy in each round; and an optimizer, which knows the learner's utility function and the learner's online learning algorithm. The optimizer wants to plan ahead to maximize its own utility, while taking into account the learner's behavior. We provide two results: a positive result for repeated zero-sum games and a negative result for repeated general-sum games. Our positive result is an algorithm for the optimizer, which exactly maximizes its utility against a learner that plays the Replicator Dynamics -- the continuous-time analogue of Multiplicative Weights Update (MWU). Additionally, we use this result to provide an algorithm for the optimizer against MWU, i.e.~for the discrete-time setting, which guarantees an average utility for the optimizer that is higher than the value of the one-shot game. Our negative result shows that, unless P=NP, there is no Fully Polynomial Time Approximation Scheme (FPTAS) for maximizing the utility of an optimizer against a learner that best-responds to the history in each round. Yet, this still leaves open the question of whether there exists a polynomial-time algorithm that optimizes the utility up to $o(T)$.
Read more7/9/2024