Emergent specialization from participation dynamics and multi-learner retraining
2206.02667
0
0
⚙️
Abstract
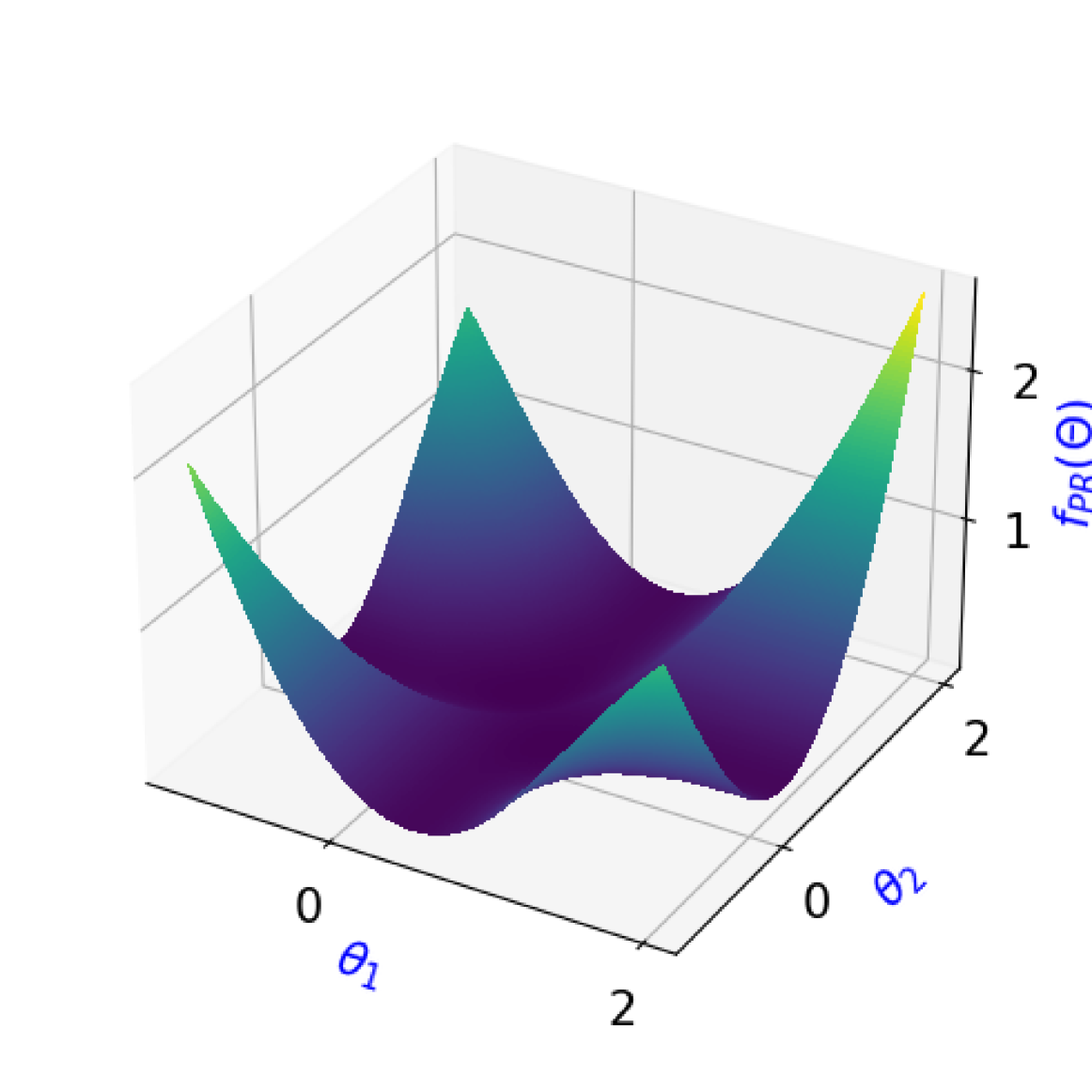
Numerous online services are data-driven: the behavior of users affects the system's parameters, and the system's parameters affect the users' experience of the service, which in turn affects the way users may interact with the system. For example, people may choose to use a service only for tasks that already works well, or they may choose to switch to a different service. These adaptations influence the ability of a system to learn about a population of users and tasks in order to improve its performance broadly. In this work, we analyze a class of such dynamics -- where users allocate their participation amongst services to reduce the individual risk they experience, and services update their model parameters to reduce the service's risk on their current user population. We refer to these dynamics as emph{risk-reducing}, which cover a broad class of common model updates including gradient descent and multiplicative weights. For this general class of dynamics, we show that asymptotically stable equilibria are always segmented, with sub-populations allocated to a single learner. Under mild assumptions, the utilitarian social optimum is a stable equilibrium. In contrast to previous work, which shows that repeated risk minimization can result in (Hashimoto et al., 2018; Miller et al., 2021), we find that repeated myopic updates with multiple learners lead to better outcomes. We illustrate the phenomena via a simulated example initialized from real data.
Create account to get full access
Overview
- The paper analyzes a class of dynamics where users allocate their participation across different online services to reduce their individual risk, and the services update their model parameters to reduce the overall risk on their current user population.
- The authors refer to these dynamics as "risk-reducing", which cover a broad class of common model updates including gradient descent and multiplicative weights.
- The paper shows that asymptotically stable equilibria are always segmented, with sub-populations allocated to a single service. Under mild assumptions, the utilitarian social optimum is a stable equilibrium.
- In contrast to previous work, which shows that repeated risk minimization can result in suboptimal outcomes, the authors find that repeated myopic updates with multiple services lead to better outcomes.
Plain English Explanation
Many online services today rely on data-driven approaches, where the behavior of users affects the system's parameters, and the system's parameters in turn affect the users' experience. This can lead to a complex, adaptive dynamic between the users and the service.
For example, users may choose to use a service only for tasks that already work well, or they may switch to a different service. These adaptations influence the service's ability to learn about its user population and improve its performance over time.
The paper analyzes a specific class of these dynamics, where users try to minimize their individual risk by allocating their participation across different services, and the services update their models to reduce the overall risk for their current user base. The authors call this a "risk-reducing" dynamic.
Interestingly, the paper shows that these dynamics will naturally lead to a stable equilibrium where the user population is divided into distinct segments, each using a single service. Moreover, under certain conditions, this segmented equilibrium will also be the best overall outcome for society (the "utilitarian social optimum").
This is in contrast to previous research, which had suggested that repeated risk minimization could lead to suboptimal outcomes. The current paper finds that having multiple services competing for users can actually result in better outcomes through these risk-reducing dynamics.
Technical Explanation
The paper analyzes a class of dynamics where users allocate their participation among different online services in order to reduce their individual risk, and the services update their model parameters to reduce the overall risk on their current user population.
The authors show that for this general class of "risk-reducing" dynamics, which includes common techniques like gradient descent and multiplicative weights, the asymptotically stable equilibria are always segmented. This means that the user population will divide into distinct sub-populations, each allocated to a single service.
Furthermore, under mild assumptions, the paper demonstrates that the utilitarian social optimum - the outcome that maximizes the overall welfare of users - is a stable equilibrium in this system. This is in contrast to previous work, which had shown that repeated risk minimization can lead to suboptimal outcomes.
The authors illustrate these phenomena using a simulated example initialized from real data, showing that the presence of multiple competing services can actually lead to better outcomes through the risk-reducing dynamics, compared to a single service scenario.
Critical Analysis
The paper provides an interesting theoretical analysis of a class of dynamics that arise in many data-driven online services. The key insight - that risk-reducing dynamics can lead to stable, segmented equilibria that align with the utilitarian social optimum - is noteworthy and worth further exploration.
However, the paper does make some simplifying assumptions, such as the form of the risk function and the availability of global information about the user population. In practice, online services may have more limited information and face other constraints that could affect the dynamics.
Additionally, the paper does not address potential issues around fairness, such as whether the segmented equilibria might disadvantage certain user groups. There may also be questions around the stability of these equilibria in the face of external shocks or rapidly changing user preferences.
Further research could explore the robustness of these results under more realistic conditions, as well as investigate potential interventions or design choices that could steer the system towards more equitable outcomes. Demand sampling, group decision-making, and other related areas may offer useful perspectives and techniques to build on this work.
Conclusion
This paper presents a novel analysis of the dynamics that can arise when users and data-driven online services interact in a risk-reducing manner. The key finding - that stable, segmented equilibria can align with the utilitarian social optimum - is an important theoretical insight with potential practical implications.
While the analysis makes some simplifying assumptions, the paper opens up interesting avenues for further research on the complex interplay between user behavior and service optimization in data-driven systems. By understanding these dynamics better, researchers and practitioners may be able to design online services that better serve the collective interests of users and society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Learning from Streaming Data when Users Choose
Jinyan Su, Sarah Dean
0
0
In digital markets comprised of many competing services, each user chooses between multiple service providers according to their preferences, and the chosen service makes use of the user data to incrementally improve its model. The service providers' models influence which service the user will choose at the next time step, and the user's choice, in return, influences the model update, leading to a feedback loop. In this paper, we formalize the above dynamics and develop a simple and efficient decentralized algorithm to locally minimize the overall user loss. Theoretically, we show that our algorithm asymptotically converges to stationary points of of the overall loss almost surely. We also experimentally demonstrate the utility of our algorithm with real world data.
6/4/2024

Scale-Robust Timely Asynchronous Decentralized Learning
Purbesh Mitra, Sennur Ulukus
0
0
We consider an asynchronous decentralized learning system, which consists of a network of connected devices trying to learn a machine learning model without any centralized parameter server. The users in the network have their own local training data, which is used for learning across all the nodes in the network. The learning method consists of two processes, evolving simultaneously without any necessary synchronization. The first process is the model update, where the users update their local model via a fixed number of stochastic gradient descent steps. The second process is model mixing, where the users communicate with each other via randomized gossiping to exchange their models and average them to reach consensus. In this work, we investigate the staleness criteria for such a system, which is a sufficient condition for convergence of individual user models. We show that for network scaling, i.e., when the number of user devices $n$ is very large, if the gossip capacity of individual users scales as $Omega(log n)$, we can guarantee the convergence of user models in finite time. Furthermore, we show that the bounded staleness can only be guaranteed by any distributed opportunistic scheme by $Omega(n)$ scaling.
5/1/2024
🤔
Understanding Model Selection For Learning In Strategic Environments
Tinashe Handina, Eric Mazumdar
0
0
The deployment of ever-larger machine learning models reflects a growing consensus that the more expressive the model class one optimizes over$unicode{x2013}$and the more data one has access to$unicode{x2013}$the more one can improve performance. As models get deployed in a variety of real-world scenarios, they inevitably face strategic environments. In this work, we consider the natural question of how the interplay of models and strategic interactions affects the relationship between performance at equilibrium and the expressivity of model classes. We find that strategic interactions can break the conventional view$unicode{x2013}$meaning that performance does not necessarily monotonically improve as model classes get larger or more expressive (even with infinite data). We show the implications of this result in several contexts including strategic regression, strategic classification, and multi-agent reinforcement learning. In particular, we show that each of these settings admits a Braess' paradox-like phenomenon in which optimizing over less expressive model classes allows one to achieve strictly better equilibrium outcomes. Motivated by these examples, we then propose a new paradigm for model selection in games wherein an agent seeks to choose amongst different model classes to use as their action set in a game.
6/4/2024
📉
Decentralized Online Learning in General-Sum Stackelberg Games
Yaolong Yu, Haipeng Chen
0
0
We study an online learning problem in general-sum Stackelberg games, where players act in a decentralized and strategic manner. We study two settings depending on the type of information for the follower: (1) the limited information setting where the follower only observes its own reward, and (2) the side information setting where the follower has extra side information about the leader's reward. We show that for the follower, myopically best responding to the leader's action is the best strategy for the limited information setting, but not necessarily so for the side information setting -- the follower can manipulate the leader's reward signals with strategic actions, and hence induce the leader's strategy to converge to an equilibrium that is better off for itself. Based on these insights, we study decentralized online learning for both players in the two settings. Our main contribution is to derive last-iterate convergence and sample complexity results in both settings. Notably, we design a new manipulation strategy for the follower in the latter setting, and show that it has an intrinsic advantage against the best response strategy. Our theories are also supported by empirical results.
5/7/2024