Challenges in Deploying Long-Context Transformers: A Theoretical Peak Performance Analysis

0

Sign in to get full access
Overview
- This paper analyzes the challenges in deploying long-context transformers, which are AI models that can process and understand long pieces of text.
- The researchers look at the theoretical peak performance of these models and identify several key obstacles to their widespread adoption.
- The paper suggests that issues like memory constraints, inefficient attention mechanisms, and difficulties in extending embeddings to long contexts are major hurdles that need to be addressed.
Plain English Explanation
Long-context transformers are a type of AI model that can work with and make sense of lengthy pieces of text, like long documents or entire books. This is a valuable capability because many real-world applications, from summarizing legal contracts to analyzing research papers, require understanding extended context beyond just a few sentences.
However, deploying these models in practice comes with significant technical challenges. The paper dives into these challenges from a theoretical perspective, examining the fundamental limitations that prevent long-context transformers from reaching their full potential.
One major issue is memory constraints - these models require a lot of computer memory to process long inputs, which can make them impractical to run on many real-world systems. The researchers also find problems with the attention mechanisms used by transformers, which become increasingly inefficient as the context size grows.
Another key challenge is extending the embedding models that transformers rely on to handle long-form content. Typical embedding techniques struggle when applied to very long inputs.
The paper argues that solving these fundamental limitations is critical for unlocking the full potential of long-context transformers and bringing their benefits to a wider range of applications. Researchers will need to develop new architectures, attention mechanisms, and embedding approaches specifically designed for extended contexts.
Technical Explanation
The paper begins by highlighting the importance of long-context understanding for many real-world AI applications, from document summarization to open-ended question answering. However, the authors note that deploying long-context transformers in practice faces significant challenges.
To understand these challenges, the researchers analyze the theoretical peak performance of long-context transformers. They find that memory constraints are a major bottleneck, as the memory requirements of these models grow quadratically with the input size. This makes it impractical to process very long contexts on many real-world systems.
The paper also delves into issues with the attention mechanisms used by transformers. The authors show that attention becomes increasingly inefficient as the context size grows, limiting the models' ability to capture long-range dependencies. This finding aligns with other recent work, such as the LEAVE-NO-CONTEXT-BEHIND and XLD2D benchmarks, which have highlighted the struggles of transformers with extremely long contexts.
Another key challenge identified in the paper is the difficulty of extending embedding models to handle long-form content. The researchers show that typical embedding techniques, such as averaging word embeddings, perform poorly when applied to very long inputs. This suggests the need for new embedding approaches tailored to long-context understanding.
To address these challenges, the authors propose several directions for future research, including the development of length-aware multi-kernel transformer architectures and more efficient attention mechanisms.
Critical Analysis
The paper provides a detailed theoretical analysis of the challenges facing long-context transformers, which is a valuable contribution to the field. The researchers do an excellent job of identifying and rigorously examining the key bottlenecks, such as memory constraints and attention inefficiencies, that limit the performance of these models.
That said, the paper is primarily focused on the theoretical aspects and does not delve deeply into practical solutions or empirical evaluations. While the authors suggest some potential research directions, such as length-aware architectures, the paper lacks concrete proposals or experiments demonstrating how these challenges can be overcome.
Additionally, the paper could have delved more into the broader implications and real-world impacts of these challenges. For example, how might the limitations of long-context transformers affect their adoption in various application domains? What are the potential societal or economic consequences of these models failing to reach their full potential?
Overall, the paper offers a strong theoretical foundation and lays the groundwork for future research on addressing the fundamental obstacles to deploying long-context transformers. However, more work is needed to translate these insights into practical solutions and understand the broader implications of this work.
Conclusion
This paper provides a detailed analysis of the challenges in deploying long-context transformers, which are AI models designed to process and understand lengthy pieces of text. The researchers identify several key obstacles, including memory constraints, inefficient attention mechanisms, and difficulties in extending embedding models to long contexts.
The findings presented in this paper are a crucial step towards unlocking the full potential of long-context transformers and enabling their widespread adoption in real-world applications that require extended understanding beyond just a few sentences. By addressing these fundamental limitations, researchers can pave the way for transformers that can seamlessly handle long-form content, opening up new possibilities in domains like document summarization, legal analysis, and open-ended question answering.
While the paper focuses on the theoretical aspects, the insights it provides can inform the development of novel architectures, attention mechanisms, and embedding techniques specifically tailored for long-context understanding. Overcoming these challenges is essential for bringing the benefits of advanced language models to a wider range of applications and users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Challenges in Deploying Long-Context Transformers: A Theoretical Peak Performance Analysis
Yao Fu
Transformer-based long context generative models power emerging AI applications like hour-long video understanding and project-level coding agent. Deploying long context transformers (e.g., 100K to 10M tokens) is prohibitively expensive compared to short context (e.g., 4K tokens) model variants. Reducing the cost of long-context transformers is becoming a pressing research and engineering challenge starting from the year of 2024. This work describes a concurrent programming framework for quantitatively analyzing the efficiency challenges in serving multiple long-context requests under limited size of GPU high-bandwidth memory (HBM) regime. We give a detailed analysis of how all additional computational costs, compared to 4K context, trace back to textit{one single source: the large size of the KV cache}. We use a 34B GPT-3.5 level model of 50K context on A100 NVLink as a running example, and describe how its large KV cache causes four types of deployment challenges: (1) prefilling long inputs takes much longer compute time and GPU memory than short inputs; (2) after prefilling, the large KV cache residing on the GPU HBM substantially restricts the number of concurrent users being served; (3) during decoding, repeatedly reading the KV cache from HBM to SM largely increases latency; (4) when KV cache memory overflows, swapping it from HBM to DDR causes significant context switching latency. We use this framework to analyze existing works and identify possibilities of combining them to build end-to-end systems. Overall, this work offers a foundational framework for analyzing long context transformer deployment and identifies directions towards reducing the inference cost of 1M context to be as cheap as 4K.
Read more5/16/2024
🌐
0
KV Cache Compression, But What Must We Give in Return? A Comprehensive Benchmark of Long Context Capable Approaches
Jiayi Yuan (Henry), Hongyi Liu (Henry), Shaochen (Henry), Zhong, Yu-Neng Chuang, Songchen Li, Guanchu Wang, Duy Le, Hongye Jin, Vipin Chaudhary, Zhaozhuo Xu, Zirui Liu, Xia Hu
Long context capability is a crucial competency for large language models (LLMs) as it mitigates the human struggle to digest long-form texts. This capability enables complex task-solving scenarios such as book summarization, code assistance, and many more tasks that are traditionally manpower-intensive. However, transformer-based LLMs face significant challenges with long context input due to the growing size of the KV cache and the intrinsic complexity of attending to extended inputs; where multiple schools of efficiency-driven approaches -- such as KV cache quantization, token dropping, prompt compression, linear-time sequence models, and hybrid architectures -- have been proposed to produce efficient yet long context-capable models. Despite these advancements, no existing work has comprehensively benchmarked these methods in a reasonably aligned environment. In this work, we fill this gap by providing a taxonomy of current methods and evaluating 10+ state-of-the-art approaches across seven categories of long context tasks. Our work reveals numerous previously unknown phenomena and offers insights -- as well as a friendly workbench -- for the future development of long context-capable LLMs. The source code will be available at https://github.com/henryzhongsc/longctx_bench
Read more7/2/2024

0
Training Ultra Long Context Language Model with Fully Pipelined Distributed Transformer
Jinghan Yao, Sam Ade Jacobs, Masahiro Tanaka, Olatunji Ruwase, Aamir Shafi, Hari Subramoni, Dhabaleswar K. Panda
Large Language Models (LLMs) with long context capabilities are integral to complex tasks in natural language processing and computational biology, such as text generation and protein sequence analysis. However, training LLMs directly on extremely long contexts demands considerable GPU resources and increased memory, leading to higher costs and greater complexity. Alternative approaches that introduce long context capabilities via downstream finetuning or adaptations impose significant design limitations. In this paper, we propose Fully Pipelined Distributed Transformer (FPDT) for efficiently training long-context LLMs with extreme hardware efficiency. For GPT and Llama models, we achieve a 16x increase in sequence length that can be trained on the same hardware compared to current state-of-the-art solutions. With our dedicated sequence chunk pipeline design, we can now train 8B LLM with 2 million sequence length on only 4 GPUs, while also maintaining over 55% of MFU. Our proposed FPDT is agnostic to existing training techniques and is proven to work efficiently across different LLM models.
Read more9/2/2024
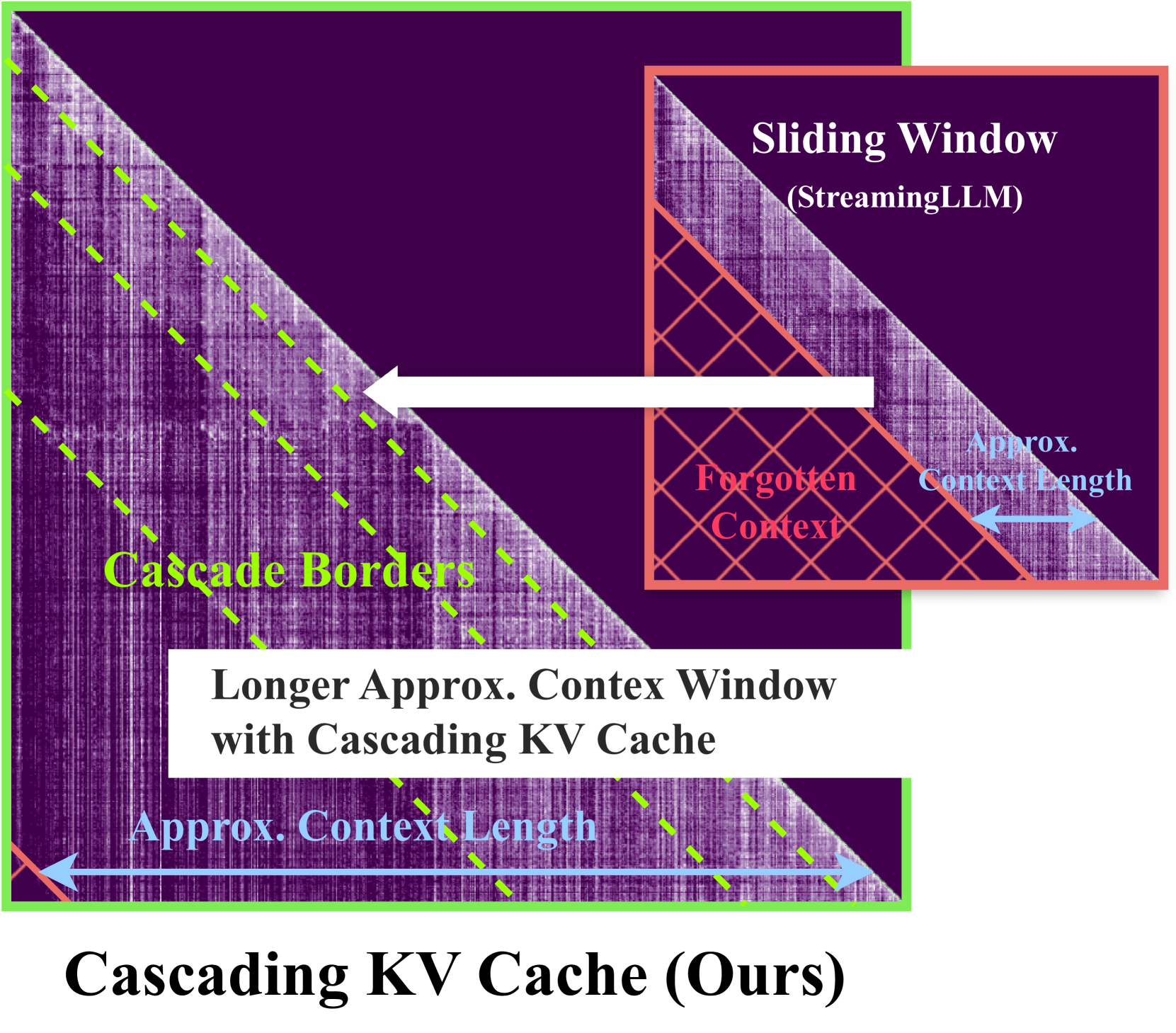
0
Training-Free Exponential Extension of Sliding Window Context with Cascading KV Cache
Jeffrey Willette, Heejun Lee, Youngwan Lee, Myeongjae Jeon, Sung Ju Hwang
The context window within a transformer provides a form of active memory for the current task, which can be useful for few-shot learning and conditional generation, both which depend heavily on previous context tokens. However, as the context length grows, the computational cost increases quadratically. Recent works have shown that saving a few initial tokens along with a fixed-sized sliding window leads to stable streaming generation with linear complexity in transformer-based Large Language Models (LLMs). However, they make suboptimal use of the fixed window by naively evicting all tokens unconditionally from the key-value (KV) cache once they reach the end of the window, resulting in tokens being forgotten and no longer able to affect subsequent predictions. To overcome this limitation, we propose a novel mechanism for storing longer sliding window contexts with the same total cache size by keeping separate cascading sub-cache buffers whereby each subsequent buffer conditionally accepts a fraction of the relatively more important tokens evicted from the previous buffer. Our method results in a dynamic KV cache that can store tokens from the more distant past than a fixed, static sliding window approach. Our experiments show improvements of 5.6% on long context generation (LongBench), 1.2% in streaming perplexity (PG19), and 0.6% in language understanding (MMLU STEM) using LLMs given the same fixed cache size. Additionally, we provide an efficient implementation that improves the KV cache latency from 1.33ms per caching operation to 0.54ms, a 59% speedup over previous work.
Read more6/27/2024