Equivariance via Minimal Frame Averaging for More Symmetries and Efficiency

0

Sign in to get full access
Overview
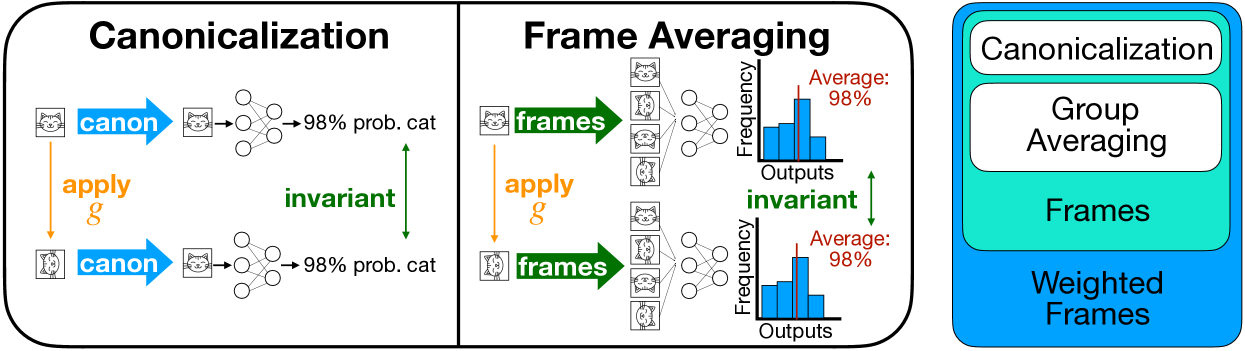
- This paper introduces a new approach called "Minimal Frame Averaging" (MFA) that can make machine learning models more symmetry-equivariant and efficient.
- Equivariance is an important property that allows models to be invariant to certain transformations, like rotations or translations, which can improve performance and generalization.
- The MFA method aims to capture more symmetries than previous approaches and do so in a more computationally efficient way.
Plain English Explanation
The researchers have developed a new technique called "Minimal Frame Averaging" (MFA) that can help make machine learning models better at capturing different types of symmetries. Symmetries are important because they allow models to be invariant to certain transformations, like rotating or translating an image. This can improve a model's performance and ability to generalize to new data.
Previous methods for building symmetry-equivariant models have had some limitations. The MFA approach aims to overcome these by being able to capture a wider range of symmetries in a more efficient way. The key idea is to average the model's outputs over a minimal set of "frames" or viewpoints, rather than a larger set. This allows the model to learn symmetries more effectively without as much computational overhead.
The paper demonstrates that models using the MFA technique can achieve better performance on certain tasks compared to previous symmetry-based approaches, while also being more computationally efficient. This could make it easier to build machine learning systems that are robust to different types of transformations and variations in the input data.
Technical Explanation
The paper introduces a new method called "Minimal Frame Averaging" (MFA) for building more symmetry-equivariant and efficient machine learning models. Equivariance is an important property that allows models to be invariant to certain transformations, like rotations or translations, which can improve performance and generalization.
Previous approaches to building equivariant models, such as group convolutions and tensor frames, have had some limitations in the types of symmetries they can capture and their computational efficiency. The MFA method aims to address these limitations by only averaging the model's outputs over a minimal set of "frames" or viewpoints, rather than a larger set.
The paper demonstrates that models using the MFA technique can achieve better performance on certain tasks, such as data-scarce scientific modeling, compared to previous symmetry-based approaches. They also show that the MFA method is more computationally efficient, which could make it easier to build symmetry-equivariant models in practice.
Critical Analysis
The paper provides a novel and promising approach to building more symmetry-equivariant and efficient machine learning models. The MFA method appears to be a significant advancement over previous techniques, offering the ability to capture a wider range of symmetries with lower computational cost.
However, the paper does not address some potential limitations or caveats of the MFA approach. For example, it's not clear how the method would perform on highly complex or diverse datasets, where the set of relevant symmetries may be more challenging to identify and incorporate. Additionally, the paper does not explore the robustness of MFA-based models to different types of distributional shift or adversarial attacks.
Further research could also investigate the theoretical properties of the MFA technique, such as its convergence guarantees and the relationship between the size of the minimal frame set and the expressivity of the resulting models. Exploring these aspects could help solidify the foundations of the approach and guide its practical application.
Conclusion
The "Minimal Frame Averaging" (MFA) method presented in this paper offers a promising new approach for building more symmetry-equivariant and efficient machine learning models. By only averaging the model's outputs over a minimal set of viewpoints, the MFA technique can capture a wider range of symmetries with lower computational overhead compared to previous methods.
The paper's empirical results demonstrate the potential benefits of the MFA approach, particularly in terms of improved performance and efficiency. These advancements could make it easier to develop machine learning systems that are robust to various transformations and variations in the input data, which has important implications for a wide range of applications.
While the paper does not address all potential limitations, the MFA method represents a significant step forward in the field of symmetry-equivariant learning. Further research and refinement of the approach could lead to even more powerful and versatile machine learning models that can better generalize and adapt to the complex and diverse data encountered in real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Equivariance via Minimal Frame Averaging for More Symmetries and Efficiency
Yuchao Lin, Jacob Helwig, Shurui Gui, Shuiwang Ji
We consider achieving equivariance in machine learning systems via frame averaging. Current frame averaging methods involve a costly sum over large frames or rely on sampling-based approaches that only yield approximate equivariance. Here, we propose Minimal Frame Averaging (MFA), a mathematical framework for constructing provably minimal frames that are exactly equivariant. The general foundations of MFA also allow us to extend frame averaging to more groups than previously considered, including the Lorentz group for describing symmetries in space-time, and the unitary group for complex-valued domains. Results demonstrate the efficiency and effectiveness of encoding symmetries via MFA across a diverse range of tasks, including $n$-body simulation, top tagging in collider physics, and relaxed energy prediction. Our code is available at https://github.com/divelab/MFA.
Read more6/24/2024
0
Equivariant Frames and the Impossibility of Continuous Canonicalization
Nadav Dym, Hannah Lawrence, Jonathan W. Siegel
Canonicalization provides an architecture-agnostic method for enforcing equivariance, with generalizations such as frame-averaging recently gaining prominence as a lightweight and flexible alternative to equivariant architectures. Recent works have found an empirical benefit to using probabilistic frames instead, which learn weighted distributions over group elements. In this work, we provide strong theoretical justification for this phenomenon: for commonly-used groups, there is no efficiently computable choice of frame that preserves continuity of the function being averaged. In other words, unweighted frame-averaging can turn a smooth, non-symmetric function into a discontinuous, symmetric function. To address this fundamental robustness problem, we formally define and construct emph{weighted} frames, which provably preserve continuity, and demonstrate their utility by constructing efficient and continuous weighted frames for the actions of $SO(2)$, $SO(3)$, and $S_n$ on point clouds.
Read more6/19/2024
🎯
0
A Canonization Perspective on Invariant and Equivariant Learning
George Ma, Yifei Wang, Derek Lim, Stefanie Jegelka, Yisen Wang
In many applications, we desire neural networks to exhibit invariance or equivariance to certain groups due to symmetries inherent in the data. Recently, frame-averaging methods emerged to be a unified framework for attaining symmetries efficiently by averaging over input-dependent subsets of the group, i.e., frames. What we currently lack is a principled understanding of the design of frames. In this work, we introduce a canonization perspective that provides an essential and complete view of the design of frames. Canonization is a classic approach for attaining invariance by mapping inputs to their canonical forms. We show that there exists an inherent connection between frames and canonical forms. Leveraging this connection, we can efficiently compare the complexity of frames as well as determine the optimality of certain frames. Guided by this principle, we design novel frames for eigenvectors that are strictly superior to existing methods -- some are even optimal -- both theoretically and empirically. The reduction to the canonization perspective further uncovers equivalences between previous methods. These observations suggest that canonization provides a fundamental understanding of existing frame-averaging methods and unifies existing equivariant and invariant learning methods.
Read more5/30/2024

0
Symmetries in Overparametrized Neural Networks: A Mean-Field View
Javier Maass, Joaquin Fontbona
We develop a Mean-Field (MF) view of the learning dynamics of overparametrized Artificial Neural Networks (NN) under data symmetric in law wrt the action of a general compact group $G$. We consider for this a class of generalized shallow NNs given by an ensemble of $N$ multi-layer units, jointly trained using stochastic gradient descent (SGD) and possibly symmetry-leveraging (SL) techniques, such as Data Augmentation (DA), Feature Averaging (FA) or Equivariant Architectures (EA). We introduce the notions of weakly and strongly invariant laws (WI and SI) on the parameter space of each single unit, corresponding, respectively, to $G$-invariant distributions, and to distributions supported on parameters fixed by the group action (which encode EA). This allows us to define symmetric models compatible with taking $Ntoinfty$ and give an interpretation of the asymptotic dynamics of DA, FA and EA in terms of Wasserstein Gradient Flows describing their MF limits. When activations respect the group action, we show that, for symmetric data, DA, FA and freely-trained models obey the exact same MF dynamic, which stays in the space of WI laws and minimizes therein the population risk. We also give a counterexample to the general attainability of an optimum over SI laws. Despite this, quite remarkably, we show that the set of SI laws is also preserved by the MF dynamics even when freely trained. This sharply contrasts the finite-$N$ setting, in which EAs are generally not preserved by unconstrained SGD. We illustrate the validity of our findings as $N$ gets larger in a teacher-student experimental setting, training a student NN to learn from a WI, SI or arbitrary teacher model through various SL schemes. We last deduce a data-driven heuristic to discover the largest subspace of parameters supporting SI distributions for a problem, that could be used for designing EA with minimal generalization error.
Read more7/29/2024