ER-FSL: Experience Replay with Feature Subspace Learning for Online Continual Learning

0
Sign in to get full access
Overview
- This paper proposes a new approach called ER-FSL (Experience Replay with Feature Subspace Learning) for online continual learning, which aims to overcome the challenges of catastrophic forgetting and negative transfer.
- ER-FSL uses experience replay to store and replay past data, and feature subspace learning to learn new tasks without forgetting previous knowledge.
- The authors demonstrate the effectiveness of ER-FSL on image classification tasks, showing improved performance compared to other state-of-the-art continual learning methods.
Plain English Explanation
ER-FSL is a machine learning technique that helps AI systems learn new tasks without forgetting what they've learned in the past. This is a common problem in continual learning, where AI models need to adapt to new information over time.
The key ideas behind ER-FSL are:
- Experience Replay: The system stores and replays past data, which helps it remember what it has learned before.
- Feature Subspace Learning: The system learns new tasks by focusing on a specific set of features, rather than trying to learn everything at once. This helps it avoid forgetting previous knowledge.
By combining these two approaches, ER-FSL is able to outperform other continual learning methods on image classification tasks. This is important because it means AI systems can be more flexible and adaptable, allowing them to learn and grow over time without losing their previous capabilities.
Technical Explanation
The paper introduces ER-FSL, a novel approach for online continual learning that addresses the challenges of catastrophic forgetting and negative transfer. ER-FSL combines two key components:
-
Experience Replay: ER-FSL stores past data in a replay buffer and replays this data during training, which helps the model retain previously learned knowledge. This is similar to approaches like Adaptive Memory Replay and Offline Experience Replay.
-
Feature Subspace Learning: ER-FSL learns new tasks by focusing on a specific subspace of features, rather than trying to learn everything at once. This helps the model avoid negative transfer and catastrophic forgetting, as it can selectively update the relevant parts of the network without disrupting the knowledge learned for previous tasks. This is related to ideas like Overcoming Domain Drift and Brain-Inspired Continual Learning.
The authors evaluate ER-FSL on various image classification tasks and show that it outperforms other state-of-the-art continual learning methods, demonstrating its effectiveness in learning new tasks while preserving previous knowledge.
Critical Analysis
The paper presents a well-designed and thorough evaluation of ER-FSL, including comparisons to multiple baseline methods on diverse datasets. The authors also discuss several limitations and potential areas for future research, such as:
- Extending ER-FSL to more complex and diverse task sequences, beyond the image classification tasks considered in this work.
- Exploring the impact of different experience replay strategies and feature subspace learning methods on the overall performance of ER-FSL.
- Investigating the computational and memory overhead of ER-FSL, and potential ways to further optimize its efficiency.
While the paper makes a strong contribution to the field of continual learning, one potential area for further research could be to explore the generalization of ER-FSL to other domains, such as reinforcement learning, where continual learning is also an important challenge.
Conclusion
The ER-FSL approach presented in this paper represents a significant advancement in the field of online continual learning. By combining experience replay and feature subspace learning, ER-FSL is able to effectively learn new tasks while mitigating the issues of catastrophic forgetting and negative transfer. The authors' thorough evaluation and discussion of the method's strengths and limitations provide a solid foundation for further research and development in this area, with the potential to enable more versatile and adaptable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ER-FSL: Experience Replay with Feature Subspace Learning for Online Continual Learning
Huiwei Lin
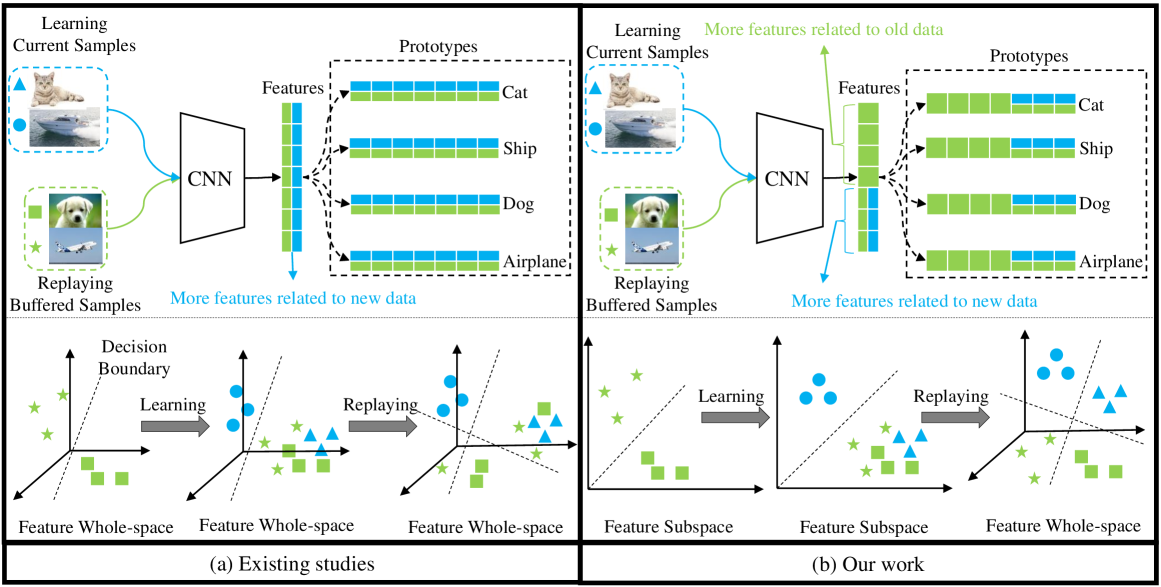
Online continual learning (OCL) involves deep neural networks retaining knowledge from old data while adapting to new data, which is accessible only once. A critical challenge in OCL is catastrophic forgetting, reflected in reduced model performance on old data. Existing replay-based methods mitigate forgetting by replaying buffered samples from old data and learning current samples of new data. In this work, we dissect existing methods and empirically discover that learning and replaying in the same feature space is not conducive to addressing the forgetting issue. Since the learned features associated with old data are readily changed by the features related to new data due to data imbalance, leading to the forgetting problem. Based on this observation, we intuitively explore learning and replaying in different feature spaces. Learning in a feature subspace is sufficient to capture novel knowledge from new data while replaying in a larger feature space provides more feature space to maintain historical knowledge from old data. To this end, we propose a novel OCL approach called experience replay with feature subspace learning (ER-FSL). Firstly, ER-FSL divides the entire feature space into multiple subspaces, with each subspace used to learn current samples. Moreover, it introduces a subspace reuse mechanism to address situations where no blank subspaces exist. Secondly, ER-FSL replays previous samples using an accumulated space comprising all learned subspaces. Extensive experiments on three datasets demonstrate the superiority of ER-FSL over various state-of-the-art methods.
Read more7/18/2024

0
Adaptive Memory Replay for Continual Learning
James Seale Smith, Lazar Valkov, Shaunak Halbe, Vyshnavi Gutta, Rogerio Feris, Zsolt Kira, Leonid Karlinsky
Foundation Models (FMs) have become the hallmark of modern AI, however, these models are trained on massive data, leading to financially expensive training. Updating FMs as new data becomes available is important, however, can lead to `catastrophic forgetting', where models underperform on tasks related to data sub-populations observed too long ago. This continual learning (CL) phenomenon has been extensively studied, but primarily in a setting where only a small amount of past data can be stored. We advocate for the paradigm where memory is abundant, allowing us to keep all previous data, but computational resources are limited. In this setting, traditional replay-based CL approaches are outperformed by a simple baseline which replays past data selected uniformly at random, indicating that this setting necessitates a new approach. We address this by introducing a framework of adaptive memory replay for continual learning, where sampling of past data is phrased as a multi-armed bandit problem. We utilize Bolzmann sampling to derive a method which dynamically selects past data for training conditioned on the current task, assuming full data access and emphasizing training efficiency. Through extensive evaluations on both vision and language pre-training tasks, we demonstrate the effectiveness of our approach, which maintains high performance while reducing forgetting by up to 10% at no training efficiency cost.
Read more4/22/2024
🏅
0
OER: Offline Experience Replay for Continual Offline Reinforcement Learning
Sibo Gai, Donglin Wang, Li He
The capability of continuously learning new skills via a sequence of pre-collected offline datasets is desired for an agent. However, consecutively learning a sequence of offline tasks likely leads to the catastrophic forgetting issue under resource-limited scenarios. In this paper, we formulate a new setting, continual offline reinforcement learning (CORL), where an agent learns a sequence of offline reinforcement learning tasks and pursues good performance on all learned tasks with a small replay buffer without exploring any of the environments of all the sequential tasks. For consistently learning on all sequential tasks, an agent requires acquiring new knowledge and meanwhile preserving old knowledge in an offline manner. To this end, we introduced continual learning algorithms and experimentally found experience replay (ER) to be the most suitable algorithm for the CORL problem. However, we observe that introducing ER into CORL encounters a new distribution shift problem: the mismatch between the experiences in the replay buffer and trajectories from the learned policy. To address such an issue, we propose a new model-based experience selection (MBES) scheme to build the replay buffer, where a transition model is learned to approximate the state distribution. This model is used to bridge the distribution bias between the replay buffer and the learned model by filtering the data from offline data that most closely resembles the learned model for storage. Moreover, in order to enhance the ability on learning new tasks, we retrofit the experience replay method with a new dual behavior cloning (DBC) architecture to avoid the disturbance of behavior-cloning loss on the Q-learning process. In general, we call our algorithm offline experience replay (OER). Extensive experiments demonstrate that our OER method outperforms SOTA baselines in widely-used Mujoco environments.
Read more4/23/2024

0
Diffusion-Driven Data Replay: A Novel Approach to Combat Forgetting in Federated Class Continual Learning
Jinglin Liang, Jin Zhong, Hanlin Gu, Zhongqi Lu, Xingxing Tang, Gang Dai, Shuangping Huang, Lixin Fan, Qiang Yang
Federated Class Continual Learning (FCCL) merges the challenges of distributed client learning with the need for seamless adaptation to new classes without forgetting old ones. The key challenge in FCCL is catastrophic forgetting, an issue that has been explored to some extent in Continual Learning (CL). However, due to privacy preservation requirements, some conventional methods, such as experience replay, are not directly applicable to FCCL. Existing FCCL methods mitigate forgetting by generating historical data through federated training of GANs or data-free knowledge distillation. However, these approaches often suffer from unstable training of generators or low-quality generated data, limiting their guidance for the model. To address this challenge, we propose a novel method of data replay based on diffusion models. Instead of training a diffusion model, we employ a pre-trained conditional diffusion model to reverse-engineer each class, searching the corresponding input conditions for each class within the model's input space, significantly reducing computational resources and time consumption while ensuring effective generation. Furthermore, we enhance the classifier's domain generalization ability on generated and real data through contrastive learning, indirectly improving the representational capability of generated data for real data. Comprehensive experiments demonstrate that our method significantly outperforms existing baselines. Code is available at https://github.com/jinglin-liang/DDDR.
Read more9/5/2024