Training of Neural Networks with Uncertain Data -- A Mixture of Experts Approach

0
🏋️
Sign in to get full access
Overview
- This paper introduces the Uncertainty-aware Mixture of Experts (uMoE), a novel approach to managing aleatoric uncertainty in neural network-based predictive models.
- Existing methods primarily focus on addressing uncertainty during the inference stage, but uMoE uniquely embeds uncertainty management into the training process.
- uMoE employs a "Divide and Conquer" strategy, partitioning the uncertain input space into more manageable subspaces, each with its own expert component trained on the respective subspace uncertainties.
- An overarching Gating Unit leverages additional information about the distribution of uncertain inputs across these subspaces to dynamically adjust the weighting of the experts, minimizing deviations from ground truth.
Plain English Explanation
Neural networks are powerful tools for making predictions, but they can struggle with uncertainty. Traditionally, methods have tried to manage uncertainty during the final prediction stage, but the Uncertainty-aware Mixture of Experts (uMoE) takes a different approach.
uMoE breaks the problem down into smaller, more manageable pieces. It starts by dividing the input space (the set of possible inputs to the model) into several smaller subspaces. Then, it trains a separate "expert" model on each of these subspaces, with each expert focused on handling the uncertainty within its own subspace.
Finally, uMoE uses a special "Gating Unit" to dynamically combine the outputs of these expert models. The Gating Unit looks at the distribution of the uncertain inputs and adjusts the weights given to each expert, to minimize the overall error.
This innovative approach allows uMoE to better handle uncertainty throughout the entire process, from training to prediction. The researchers found that uMoE outperformed other baseline methods in managing data uncertainty, and it showed adaptability to different levels of uncertainty.
The uMoE technique could have broad applications in fields like biomedical signal processing, autonomous driving, and quality control, where dealing with uncertainty is crucial.
Technical Explanation
The key innovation of the Uncertainty-aware Mixture of Experts (uMoE) is its unique approach to embedding uncertainty management into the training phase of neural network models, unlike existing methods that primarily focus on addressing uncertainty during inference.
uMoE employs a "Divide and Conquer" strategy, where the uncertain input space is strategically partitioned into more manageable subspaces. This is accomplished by training individual "Expert" components, each responsible for a specific subspace and its associated uncertainties.
Overarching the Experts, a "Gating Unit" leverages additional information about the distribution of uncertain inputs across these subspaces. The Gating Unit dynamically adjusts the weighting of the Experts' outputs to minimize deviations from the ground truth, effectively managing the overall uncertainty.
The researchers' experiments demonstrate the superior performance of uMoE compared to baseline methods in handling data uncertainty. Additionally, the comprehensive robustness analysis showcases uMoE's adaptability to varying uncertainty levels and suggests optimal threshold parameters.
Critical Analysis
The paper provides a thorough introduction to the uMoE approach and its key components, including the Divide and Conquer strategy, Expert models, and Gating Unit. The experimental results demonstrate the effectiveness of uMoE in managing data uncertainty, which is a significant challenge in many real-world applications.
However, the paper does not delve deeply into the potential limitations or caveats of the approach. For instance, the computational complexity and training time of the uMoE model, especially as the number of subspaces and Experts increases, are not discussed. Additionally, the paper could have explored the sensitivity of the uMoE performance to the choice of hyperparameters or the specific partitioning of the input space.
Further research could also investigate the generalization of the uMoE approach to other types of uncertainty, such as epistemic uncertainty, and its applicability to a wider range of domains beyond the examples provided.
Conclusion
The Uncertainty-aware Mixture of Experts (uMoE) represents a novel and innovative approach to managing aleatoric uncertainty within neural network-based predictive models. By embedding uncertainty management into the training process, rather than solely focusing on the inference stage, uMoE demonstrates superior performance over baseline methods.
The key strengths of uMoE lie in its Divide and Conquer strategy, which partitions the uncertain input space into more manageable subspaces, and its dynamic Gating Unit, which adjusts the weighting of the Expert models to minimize deviations from ground truth.
This flexible and adaptable uMoE technique holds great promise for a wide range of data-driven domains, from biomedical signal processing to autonomous driving and production quality control, where effectively managing uncertainty is crucial for reliable and robust predictive models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Training of Neural Networks with Uncertain Data -- A Mixture of Experts Approach
Lucas Luttner
This paper introduces the Uncertainty-aware Mixture of Experts (uMoE), a novel solution aimed at addressing aleatoric uncertainty within Neural Network (NN) based predictive models. While existing methodologies primarily concentrate on managing uncertainty during inference, uMoE uniquely embeds uncertainty into the training phase. Employing a Divide and Conquer strategy, uMoE strategically partitions the uncertain input space into more manageable subspaces. It comprises Expert components, individually trained on their respective subspace uncertainties. Overarching the Experts, a Gating Unit, leveraging additional information regarding the distribution of uncertain in-puts across these subspaces, dynamically adjusts the weighting to minimize deviations from ground truth. Our findings demonstrate the superior performance of uMoE over baseline methods in effectively managing data uncertainty. Furthermore, through a comprehensive robustness analysis, we showcase its adaptability to varying uncertainty levels and propose optimal threshold parameters. This innovative approach boasts broad applicability across diverse da-ta-driven domains, including but not limited to biomedical signal processing, autonomous driving, and production quality control.
Read more4/26/2024
0
HyperMoE: Towards Better Mixture of Experts via Transferring Among Experts
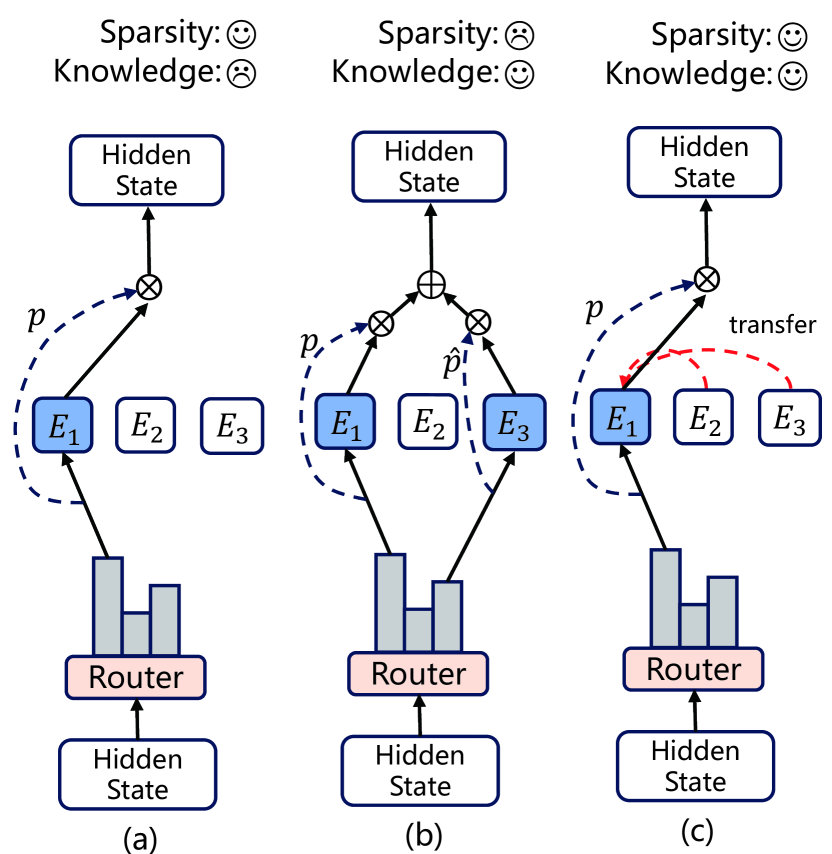
Hao Zhao, Zihan Qiu, Huijia Wu, Zili Wang, Zhaofeng He, Jie Fu
The Mixture of Experts (MoE) for language models has been proven effective in augmenting the capacity of models by dynamically routing each input token to a specific subset of experts for processing. Despite the success, most existing methods face a challenge for balance between sparsity and the availability of expert knowledge: enhancing performance through increased use of expert knowledge often results in diminishing sparsity during expert selection. To mitigate this contradiction, we propose HyperMoE, a novel MoE framework built upon Hypernetworks. This framework integrates the computational processes of MoE with the concept of knowledge transferring in multi-task learning. Specific modules generated based on the information of unselected experts serve as supplementary information, which allows the knowledge of experts not selected to be used while maintaining selection sparsity. Our comprehensive empirical evaluations across multiple datasets and backbones establish that HyperMoE significantly outperforms existing MoE methods under identical conditions concerning the number of experts.
Read more7/26/2024

0
A Survey on Mixture of Experts
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, Jiayi Huang
Large language models (LLMs) have garnered unprecedented advancements across diverse fields, ranging from natural language processing to computer vision and beyond. The prowess of LLMs is underpinned by their substantial model size, extensive and diverse datasets, and the vast computational power harnessed during training, all of which contribute to the emergent abilities of LLMs (e.g., in-context learning) that are not present in small models. Within this context, the mixture of experts (MoE) has emerged as an effective method for substantially scaling up model capacity with minimal computation overhead, gaining significant attention from academia and industry. Despite its growing prevalence, there lacks a systematic and comprehensive review of the literature on MoE. This survey seeks to bridge that gap, serving as an essential resource for researchers delving into the intricacies of MoE. We first briefly introduce the structure of the MoE layer, followed by proposing a new taxonomy of MoE. Next, we overview the core designs for various MoE models including both algorithmic and systemic aspects, alongside collections of available open-source implementations, hyperparameter configurations and empirical evaluations. Furthermore, we delineate the multifaceted applications of MoE in practice, and outline some potential directions for future research. To facilitate ongoing updates and the sharing of cutting-edge developments in MoE research, we have established a resource repository accessible at https://github.com/withinmiaov/A-Survey-on-Mixture-of-Experts.
Read more7/10/2024

0
Mixture of Experts in a Mixture of RL settings
Timon Willi, Johan Obando-Ceron, Jakob Foerster, Karolina Dziugaite, Pablo Samuel Castro
Mixtures of Experts (MoEs) have gained prominence in (self-)supervised learning due to their enhanced inference efficiency, adaptability to distributed training, and modularity. Previous research has illustrated that MoEs can significantly boost Deep Reinforcement Learning (DRL) performance by expanding the network's parameter count while reducing dormant neurons, thereby enhancing the model's learning capacity and ability to deal with non-stationarity. In this work, we shed more light on MoEs' ability to deal with non-stationarity and investigate MoEs in DRL settings with amplified non-stationarity via multi-task training, providing further evidence that MoEs improve learning capacity. In contrast to previous work, our multi-task results allow us to better understand the underlying causes for the beneficial effect of MoE in DRL training, the impact of the various MoE components, and insights into how best to incorporate them in actor-critic-based DRL networks. Finally, we also confirm results from previous work.
Read more6/27/2024