Espresso: Robust Concept Filtering in Text-to-Image Models

0
⛏️
Sign in to get full access
Overview
- This research paper introduces Espresso, a robust concept filter for text-to-image (T2I) models trained on large, potentially noisy internet datasets.
- T2I models can generate high-quality images from text prompts, but the training data may contain unacceptable concepts like copyright-infringing or unsafe content.
- Existing methods for removing unacceptable concepts, such as filtering and fine-tuning, have limitations in effectiveness, utility preservation, and robustness to adversarial prompts.
- Espresso addresses these challenges by using Contrastive Language-Image Pre-Training (CLIP) to identify and remove unacceptable concepts while preserving the utility of the T2I model.
Plain English Explanation
Text-to-image (T2I) models are AI systems that can generate images from text descriptions. These models are trained on massive datasets of images and their corresponding text captions, often scraped from the internet. However, this training data can contain unacceptable content, such as images that violate copyrights or depict unsafe or inappropriate subject matter.
Removing this unacceptable content from the training data and retraining the T2I model is inefficient and can degrade the model's performance on acceptable content. The researchers introduce a new technique called Espresso that addresses this problem. Espresso uses a pre-trained AI model called CLIP, which has learned to understand the relationship between images and their text descriptions.
Espresso identifies unacceptable concepts by looking at how the generated image's features are positioned in the CLIP model's joint text-image feature space. If the image features are close to the "vector" connecting acceptable and unacceptable concepts, Espresso knows the image contains an unacceptable concept and can remove it. This makes Espresso robust against attempts to bypass the filter by slightly modifying the text prompt.
Additionally, Espresso is fine-tuned to further separate the acceptable and unacceptable concept embeddings while preserving their overall pairing with the image embeddings. This ensures Espresso is effective at removing unacceptable content while still preserving the utility of the T2I model on acceptable content.
The researchers evaluate Espresso on 11 different unacceptable concepts and show that it is effective, utility-preserving, and robust to adversarial prompts. They also provide theoretical bounds for the certified robustness of Espresso against such prompts.
Technical Explanation
The core idea behind Espresso is to leverage the joint text-image embedding space learned by the Contrastive Language-Image Pre-Training (CLIP) model to identify and remove unacceptable concepts from the generated images.
Espresso works as follows:
- It first identifies unacceptable concepts by projecting the generated image's embedding onto the vector connecting unacceptable and acceptable concept embeddings in the CLIP space. If the projection is close to the unacceptable concept, the image is considered to contain an unacceptable concept.
- To make this process robust against adversarial prompts, Espresso restricts the adversary to only adding noise in the direction of the acceptable concept, as this is the only direction that preserves the image-text pairing.
- Espresso is further fine-tuned to separate the embeddings of acceptable and unacceptable concepts while preserving their overall pairing with the image embeddings. This ensures both effectiveness in removing unacceptable concepts and utility preservation on acceptable concepts.
The researchers evaluate Espresso on 11 different unacceptable concepts and show that it achieves:
- Effectiveness: ~5% CLIP accuracy on unacceptable concepts
- Utility preservation: ~93% normalized CLIP score on acceptable concepts
- Robustness: ~4% CLIP accuracy on adversarial prompts for unacceptable concepts
The paper also presents theoretical bounds for the certified robustness of Espresso against adversarial prompts, as well as an empirical analysis.
Critical Analysis
The Espresso approach addresses an important challenge in the deployment of text-to-image models, which is the potential inclusion of unacceptable content in the training data. The researchers' use of the CLIP model's joint text-image embedding space is a clever and effective way to identify and remove such content, while preserving the utility of the T2I model on acceptable concepts.
One potential limitation of the Espresso approach is that it relies on the availability of a pre-trained CLIP model, which may not always be the case, especially as the field of AI continues to evolve rapidly. Additionally, the researchers' evaluation is limited to 11 specific unacceptable concepts, and it would be valuable to see how Espresso performs on a wider range of unacceptable content.
Furthermore, the paper does not address the broader question of how to ensure the ethical and responsible development of text-to-image models, beyond the specific challenge of removing unacceptable content. Factors such as bias, transparency, and accountability in the training and deployment of these models should also be considered.
Overall, the Espresso approach represents an important step forward in making text-to-image models more robust and reliable, but there is still more work to be done to fully address the ethical challenges in this rapidly advancing field of AI.
Conclusion
The research paper introduces Espresso, a novel concept removal technique for text-to-image models that addresses the key challenges of effectiveness, utility preservation, and robustness to adversarial prompts. By leveraging the joint text-image embedding space of the CLIP model, Espresso is able to effectively identify and remove unacceptable concepts while preserving the utility of the T2I model on acceptable content.
The paper's theoretical and empirical analysis demonstrates the efficacy of the Espresso approach, which represents an important contribution to the development of safe and reliable text-to-image generation systems. As these models continue to advance and become more widely deployed, techniques like Espresso will be crucial in ensuring they are developed and used responsibly, with appropriate safeguards against the inclusion of harmful or unacceptable content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
0
Espresso: Robust Concept Filtering in Text-to-Image Models
Anudeep Das, Vasisht Duddu, Rui Zhang, N. Asokan
Diffusion based text-to-image models are trained on large datasets scraped from the Internet, potentially containing unacceptable concepts (e.g., copyright infringing or unsafe). We need concept removal techniques (CRTs) which are effective in preventing the generation of images with unacceptable concepts, utility-preserving on acceptable concepts, and robust against evasion with adversarial prompts. None of the prior CRTs satisfy all these requirements simultaneously. We introduce Espresso, the first robust concept filter based on Contrastive Language-Image Pre-Training (CLIP). We configure CLIP to identify unacceptable concepts in generated images using the distance of their embeddings to the text embeddings of both unacceptable and acceptable concepts. This lets us fine-tune for robustness by separating the text embeddings of unacceptable and acceptable concepts while preserving their pairing with image embeddings for utility. We present a pipeline to evaluate various CRTs, attacks against them, and show that Espresso, is more effective and robust than prior CRTs, while retaining utility.
Read more9/10/2024

0
Six-CD: Benchmarking Concept Removals for Benign Text-to-image Diffusion Models
Jie Ren, Kangrui Chen, Yingqian Cui, Shenglai Zeng, Hui Liu, Yue Xing, Jiliang Tang, Lingjuan Lyu
Text-to-image (T2I) diffusion models have shown exceptional capabilities in generating images that closely correspond to textual prompts. However, the advancement of T2I diffusion models presents significant risks, as the models could be exploited for malicious purposes, such as generating images with violence or nudity, or creating unauthorized portraits of public figures in inappropriate contexts. To mitigate these risks, concept removal methods have been proposed. These methods aim to modify diffusion models to prevent the generation of malicious and unwanted concepts. Despite these efforts, existing research faces several challenges: (1) a lack of consistent comparisons on a comprehensive dataset, (2) ineffective prompts in harmful and nudity concepts, (3) overlooked evaluation of the ability to generate the benign part within prompts containing malicious concepts. To address these gaps, we propose to benchmark the concept removal methods by introducing a new dataset, Six-CD, along with a novel evaluation metric. In this benchmark, we conduct a thorough evaluation of concept removals, with the experimental observations and discussions offering valuable insights in the field.
Read more6/24/2024
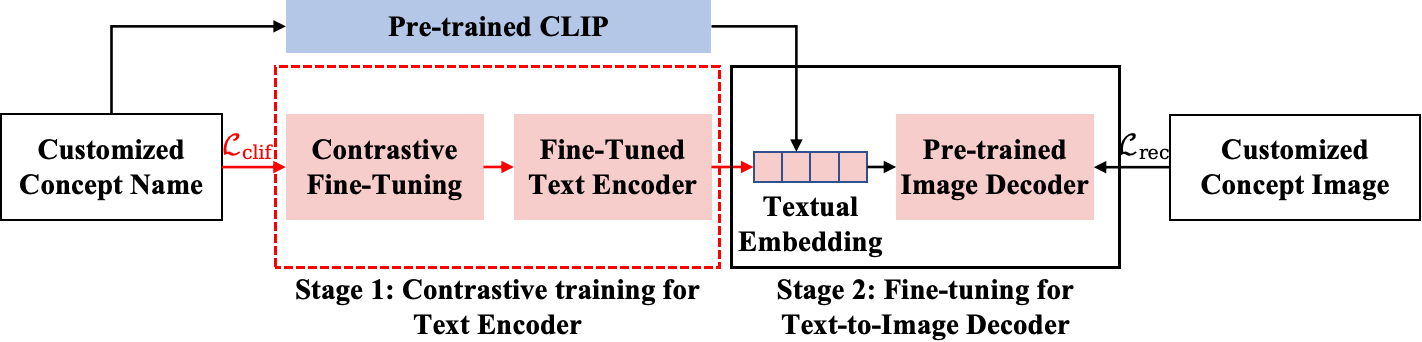
0
Non-confusing Generation of Customized Concepts in Diffusion Models
Wang Lin, Jingyuan Chen, Jiaxin Shi, Yichen Zhu, Chen Liang, Junzhong Miao, Tao Jin, Zhou Zhao, Fei Wu, Shuicheng Yan, Hanwang Zhang
We tackle the common challenge of inter-concept visual confusion in compositional concept generation using text-guided diffusion models (TGDMs). It becomes even more pronounced in the generation of customized concepts, due to the scarcity of user-provided concept visual examples. By revisiting the two major stages leading to the success of TGDMs -- 1) contrastive image-language pre-training (CLIP) for text encoder that encodes visual semantics, and 2) training TGDM that decodes the textual embeddings into pixels -- we point that existing customized generation methods only focus on fine-tuning the second stage while overlooking the first one. To this end, we propose a simple yet effective solution called CLIF: contrastive image-language fine-tuning. Specifically, given a few samples of customized concepts, we obtain non-confusing textual embeddings of a concept by fine-tuning CLIP via contrasting a concept and the over-segmented visual regions of other concepts. Experimental results demonstrate the effectiveness of CLIF in preventing the confusion of multi-customized concept generation.
Read more5/14/2024

0
STEREO: Towards Adversarially Robust Concept Erasing from Text-to-Image Generation Models
Koushik Srivatsan, Fahad Shamshad, Muzammal Naseer, Karthik Nandakumar
The rapid proliferation of large-scale text-to-image generation (T2IG) models has led to concerns about their potential misuse in generating harmful content. Though many methods have been proposed for erasing undesired concepts from T2IG models, they only provide a false sense of security, as recent works demonstrate that concept-erased models (CEMs) can be easily deceived to generate the erased concept through adversarial attacks. The problem of adversarially robust concept erasing without significant degradation to model utility (ability to generate benign concepts) remains an unresolved challenge, especially in the white-box setting where the adversary has access to the CEM. To address this gap, we propose an approach called STEREO that involves two distinct stages. The first stage searches thoroughly enough for strong and diverse adversarial prompts that can regenerate an erased concept from a CEM, by leveraging robust optimization principles from adversarial training. In the second robustly erase once stage, we introduce an anchor-concept-based compositional objective to robustly erase the target concept at one go, while attempting to minimize the degradation on model utility. By benchmarking the proposed STEREO approach against four state-of-the-art concept erasure methods under three adversarial attacks, we demonstrate its ability to achieve a better robustness vs. utility trade-off. Our code and models are available at https://github.com/koushiksrivats/robust-concept-erasing.
Read more9/2/2024