ESQA: Event Sequences Question Answering

0

Sign in to get full access
Overview
- This paper introduces ESQA (Event Sequences Question Answering), a novel task and dataset for answering questions about event sequences.
- ESQA aims to assess a model's ability to understand and reason about the temporal and causal relationships between events in a given sequence.
- The paper presents a new benchmark dataset for ESQA, along with several baseline models and evaluation metrics.
Plain English Explanation
The paper focuses on a new task called "Event Sequences Question Answering" (ESQA). The goal is to develop AI systems that can understand and reason about the temporal and causal relationships between different events that occur in a sequence.
For example, imagine a sequence of events like "John woke up, made coffee, drove to work, and attended a meeting." An ESQA system would need to be able to answer questions about this sequence, such as "What did John do after making coffee?" or "What happened before John attended the meeting?"
To enable research in this area, the paper introduces a new benchmark dataset for ESQA. This dataset contains many examples of event sequences, along with questions and answers about those sequences. The researchers also propose several baseline models and evaluation metrics to measure how well AI systems perform on this task.
The key idea is that being able to understand and reason about event sequences is an important skill for AI systems, as it reflects our human-like understanding of how the world works. By developing ESQA, the researchers hope to advance the field of AI towards more natural and contextual language understanding.
Technical Explanation
The paper presents the ESQA: Event Sequences Question Answering task, where the goal is to answer questions about the temporal and causal relationships between events in a given sequence.
To enable research in this area, the authors introduce a new ESQA dataset, which contains over 100,000 examples of event sequences, questions, and answers. The dataset is designed to test an AI system's ability to understand and reason about the temporal and causal structure of event sequences.
The paper also proposes several baseline models for the ESQA task, including transformer-based models fine-tuned on the dataset, as well as a novel model that explicitly models the temporal and causal relationships between events. The models are evaluated using both standard QA metrics as well as custom metrics designed to assess the systems' understanding of event sequences.
The results show that while the baseline models perform reasonably well on the task, there is still significant room for improvement, indicating that the ESQA task presents a challenging new frontier for natural language understanding and reasoning.
Critical Analysis
The ESQA task and dataset introduced in this paper represent an important step forward in developing AI systems that can understand and reason about the temporal and causal relationships between events in a more natural and contextual way.
However, the paper acknowledges several limitations and areas for further research. For example, the current dataset is primarily focused on relatively simple, everyday event sequences, and it may not capture the full complexity of real-world event understanding. Additionally, the baseline models, while promising, still struggle to fully capture the nuanced temporal and causal reasoning required for this task.
There are also potential concerns about the generalizability of the ESQA task and dataset. As with any benchmark, there is a risk that models may "overfit" to the specific characteristics of the dataset, rather than developing more general event understanding capabilities.
Further research is needed to explore more diverse and challenging event sequences, as well as to develop more sophisticated models that can better capture the underlying temporal and causal structures of event sequences. Incorporating knowledge about the physical and social world, as well as leveraging multimodal information, may also be important avenues for improving event sequence understanding.
Conclusion
The ESQA task and dataset introduced in this paper represent an important step forward in the field of natural language understanding and reasoning. By focusing on the temporal and causal relationships between events, the ESQA task challenges AI systems to develop a more contextual and human-like understanding of the world.
While the current baseline models show promise, there is still significant room for improvement, and the paper identifies several key areas for future research. As the field of AI continues to advance, the ability to reason about event sequences will become increasingly important for a wide range of applications, from dialogue systems to autonomous agents.
By tackling the ESQA challenge, researchers can contribute to the development of more intelligent and capable AI systems that can better understand and interact with the world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ESQA: Event Sequences Question Answering
Irina Abdullaeva, Andrei Filatov, Mikhail Orlov, Ivan Karpukhin, Viacheslav Vasilev, Denis Dimitrov, Andrey Kuznetsov, Ivan Kireev, Andrey Savchenko
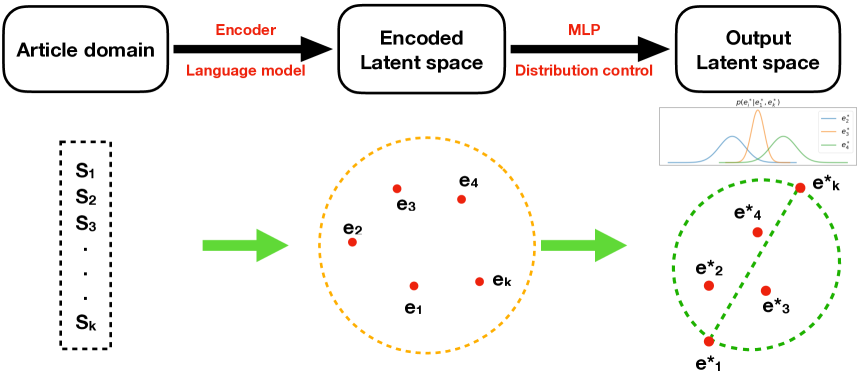
Event sequences (ESs) arise in many practical domains including finance, retail, social networks, and healthcare. In the context of machine learning, event sequences can be seen as a special type of tabular data with annotated timestamps. Despite the importance of ESs modeling and analysis, little effort was made in adapting large language models (LLMs) to the ESs domain. In this paper, we highlight the common difficulties of ESs processing and propose a novel solution capable of solving multiple downstream tasks with little or no finetuning. In particular, we solve the problem of working with long sequences and improve time and numeric features processing. The resulting method, called ESQA, effectively utilizes the power of LLMs and, according to extensive experiments, achieves state-of-the-art results in the ESs domain.
Read more7/22/2024
0
On the Sequence Evaluation based on Stochastic Processes
Tianhao Zhang, Zhexiao Lin, Zhecheng Sheng, Chen Jiang, Dongyeop Kang
Modeling and analyzing long sequences of text is an essential task for Natural Language Processing. Success in capturing long text dynamics using neural language models will facilitate many downstream tasks such as coherence evaluation, text generation, machine translation and so on. This paper presents a novel approach to model sequences through a stochastic process. We introduce a likelihood-based training objective for the text encoder and design a more thorough measurement (score) for long text evaluation compared to the previous approach. The proposed training objective effectively preserves the sequence coherence, while the new score comprehensively captures both temporal and spatial dependencies. Theoretical properties of our new score show its advantages in sequence evaluation. Experimental results show superior performance in various sequence evaluation tasks, including global and local discrimination within and between documents of different lengths. We also demonstrate the encoder achieves competitive results on discriminating human and AI written text.
Read more6/18/2024

0
Event prediction and causality inference despite incomplete information
Harrison Lam, Yuanjie Chen, Noboru Kanazawa, Mohammad Chowdhury, Anna Battista, Stephan Waldert
We explored the challenge of predicting and explaining the occurrence of events within sequences of data points. Our focus was particularly on scenarios in which unknown triggers causing the occurrence of events may consist of non-consecutive, masked, noisy data points. This scenario is akin to an agent tasked with learning to predict and explain the occurrence of events without understanding the underlying processes or having access to crucial information. Such scenarios are encountered across various fields, such as genomics, hardware and software verification, and financial time series prediction. We combined analytical, simulation, and machine learning (ML) approaches to investigate, quantify, and provide solutions to this challenge. We deduced and validated equations generally applicable to any variation of the underlying challenge. Using these equations, we (1) described how the level of complexity changes with various parameters (e.g., number of apparent and hidden states, trigger length, confidence, etc.) and (2) quantified the data needed to successfully train an ML model. We then (3) proved our ML solution learns and subsequently identifies unknown triggers and predicts the occurrence of events. If the complexity of the challenge is too high, our ML solution can identify trigger candidates to be used to interactively probe the system under investigation to determine the true trigger in a way considerably more efficient than brute force methods. By sharing our findings, we aim to assist others grappling with similar challenges, enabling estimates on the complexity of their problem, the data required and a solution to solve it.
Read more6/11/2024

0
Towards Better Question Generation in QA-Based Event Extraction
Zijin Hong, Jian Liu
Event Extraction (EE) is an essential information extraction task that aims to extract event-related information from unstructured texts. The paradigm of this task has shifted from conventional classification-based methods to more contemporary question-answering-based (QA-based) approaches. However, in QA-based EE, the quality of the questions dramatically affects the extraction accuracy, and how to generate high-quality questions for QA-based EE remains a challenge. In this work, to tackle this challenge, we suggest four criteria to evaluate the quality of a question and propose a reinforcement learning method, RLQG, for QA-based EE that can generate generalizable, high-quality, and context-dependent questions and provides clear guidance to QA models. The extensive experiments conducted on ACE and RAMS datasets have strongly validated our approach's effectiveness, which also demonstrates its robustness in scenarios with limited training data. The corresponding code of RLQG is released for further research.
Read more7/23/2024